Onboarding Exercise
You will make a list of the most common URLs in all the tweets in /home/aadelucia/files/minerva/raw_tweets_deduplicated/tweets/.
Goals of this exercise
- Learn how to submit a job to the scheduler
- Get comfortable with Tweet JSON format
- Learn strategies for working with large datasets (map-reduce style setup)
- Refresh on git commands
0. Set up your workspace
You will need to be on the grid for this exercise. You can access the grid with ssh
.
Set up your .bashrc
In order to make the grid really feel like home, we need to personalize it. We can do this by setting environment variables, having specific programs run on login, etc. Different OS have different places to save your preferences. On the grid, your preferences immediately get loaded upon login from ~/.profile. This is dumb because most other automated installed edit your ~/.bashrc to modify environment variables such as your PATH.
We need to edit your ~/.profile to source your .bashrc upon login. It's some weird thing where most programs edit your .bashrc but the system doesn't look at it upon login, so this will fix that. Open your ~/.profile with your favorite editor (I use vim) and add the following
# Code from Steven at CLSP help to read bashrc on login
if [ -n "BASH_VERSION" ]; then
# include .bashrc if it exists
if [ -f "$HOME/.bashrc" ]; then
. "$HOME/.bashrc"
fi
fi
Now you can add whatever you want to your ~/.bashrc and it will load on startup. For example, mine saves project directories as environment variables and loads a specific conda environment on login:
export PROJECT=/path/to/project
conda activate fav-env
Set up SSH keys
Okay we will need to set up multiple SSH keys in order to avoid entering our passwords over and over: (1) from your local machine to the grid (2) from the grid to GitHub (3) from your grid home directory to other nodes on the cluster.
- On your local machine, check if you have a key already. You can do this with
ls ~/.ssh/id_rsa.pub. If that file exists, then you already have a key and skip to step 3. - Generate a new private/public key pair with
ssh-keygen -C local machineand accept the defaults. (-Cis just a comment, this lets you know what the key is for) - Copy your public key to the grid with
ssh-copy-id -i ~/.ssh/id_rsa.pub@login.clsp.jhu.edu - Make sure it works by ssh-ing to the grid. You should not have to type your password anymore. For debugging, contact me.
- On the grid, generate a new key for acessing GitHub with
ssh-keygen -C CLSP gridand accept the defaults - Copy the contents of
~/.ssh/id_rsa.puband add it to your GitHub SSH keys (under Settings > SSH and GPG Keys) - Add your Grid SSH key for easy node access with
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
CLSP Grid 101
Think of the grid, also referred to as a cluster or a "supercomputer" on large scales, as a community of well-organized citizens. Each citizen (node) has its role to play in the cluster society. When you log onto the cluster, the login nodes greet you. Their names are login and login2, and are accessed with ssh
. Their job is to welcome you to the grid and so some SCPing for files. That is all, everything else is above their paygrade. Now there are the compute nodes. They are the real heavy lifters, the real workers! They are identified by a letter and a number, such as b01 and c12. To see a full list of the nodes, run qconf -sel. These nodes are where you do all your file editing and debugging. They are accessed by first logging onto the grid and then running ssh
like ssh b10. Working only on the compute nodes frees up the login node resources to welcome others to the grid.
It's easy to forget to immediately move to a compute node, so a modified ssh script can be used to access a compute node directly. From your local machine, run
ssh aadelucia@login.clsp.jhu.edu -t ssh b10
This accesses the grid through the login node and then immediately ssh's onto a compute node.
Set up Anaconda
The grid has Python 3 but in order to make setting up our own environments easier, we will install the package manager Anaconda. Or, more specifically, Miniconda, which is just a lightweight version of Anaconda (doesn't come with all the packages installed).
Log on to the grid and run the following in your home directory:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
chmod u+x Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh
This downloads the Miniconda installation file and begins the installation process. I recommend installing it in your home directory, but you could also put it in the folder you created on a compute node.
After installation is over, run source ~/.bashrc to update your PATH.
To set up an environment for this project, go to the Minerva project root directory and run:
conda env create --file environment.yml
conda activate onboarding
Note: You can add conda activate onboarding to the end of your ~/.bashrc to make this environment load upon login.
Clone this repo (if you haven't already)
You will have to re-clone the repo if you already cloned using HTTPS and would like to use SSH.
- Pick a pretty node name that you like (list node names with
ls /export/. I'm on/export/fs04/a13) and create a folder with your name in/export/. The/homedirectory is small so do not store large datasets or repos there, or it could impact other users. - Clone this repo with
git clone git@github.com:AADeLucia/CLSP-grid-onboarding.git
1. Fill in the code
Remember from above, edit on a compute node!
analyze_tweet_urls.py has the starter code. The task is to complete the script so that it does the following:
Loops through the input files, counts the unique URLs, and saves the counts in the output directory in an easily parsible format (one output file per input file)
As I've been messing with tweets I created a small package (littlebird) for the processes I do over and over again (like iterating over GZIP'd Twitter files). It is already installed in the onboarding environment. An example of how to use littlebird is in token_count_features.py. I highly recommend looking at this script for a guide on how to do this exercise and how to use littlebird.
2. Submit the job to run
Okay your script is done, now we want to run it! There are about 86K Twitter files so we need to be smart about this or it will take 5ever. Luckily, we already wrote our script to take in a list of files, so the plan is to use a "job array" to submit multiple small jobs as part of one big job. A starter script that you need to fill in is batch_count_urls.sh.
- Edit
batch_count_urls.shto work with your script. I suggest starting with-t 1-2to make sure your script works. - Submit the job with
qsub batch_count_urls.sh - Check the progress of your job by looking at your log file or
qstat -u
If your job status is Eqw this means there was an error in the job submission. To read the errors run qstat -j
.
Note: when working with a job array, each job gets submitted to run with the most recent version of your code so be careful about editing your code while waiting for it to end.
3. Aggregate the counts
Create a method to aggregate the counts (in analyze_tweet_urls.py) that:
- Loops over all the files in a given directory
- Adds up the counts for the unique URLs
- Saves the output (either a pickle dump or to a tab-separated (TSV) file)
- Can be called with a command-line flag (e.g.
--aggregate)
4. Make a pretty visualization
You have your results, yay! Now I want you to do something pretty with it. Make a word cloud, do a basic plot, whatever you want! This part is mostly to teach you how to use a jupyter notebook on the grid.
- Edit the paths in
forward_notebook.shto match your desired directory (home or where your files are). Also, change thePORTvariable to a unique number (preferably above 5000). - From the login node (NOT a compute node like b10. To get from a compute node to login run
exit) run~/.forward_notebook.shto start the Jupyter Notebook. This job will stay running, so you only have to run this script again if something goes wrong. - On your local machine run
ssh -L {PORT}:localhost:{PORT}(where@login.clsp.jhu.edu PORTis from the earlier step) and navigate tolocalhost:{PORT}in your browser. If you are prompted for a token or password, open thenotebook_logdirectory (specified inforward_notebook.sh) and take the notebook URL from the most recent log file. - Make a visualization
5. Bask in the glory
Congratulations, you finished the exercise! Go reward yourself with some ice cream or send me a message so I can compliment you.

 1 Jun 1, 2022
1 Jun 1, 2022
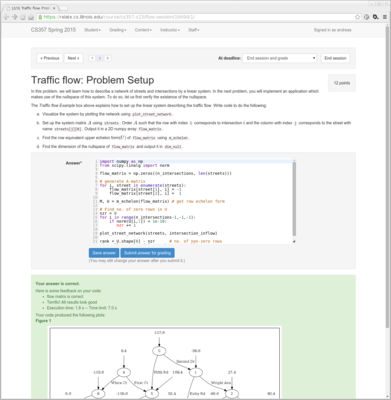
 311 Dec 25, 2022
311 Dec 25, 2022

 134 Jan 9, 2023
134 Jan 9, 2023

 10 Nov 3, 2022
10 Nov 3, 2022
 1 Jul 13, 2022
1 Jul 13, 2022

 14 Jun 27, 2022
14 Jun 27, 2022
 2 Jan 10, 2022
2 Jan 10, 2022
 7 Dec 29, 2022
7 Dec 29, 2022
 16 Nov 5, 2021
16 Nov 5, 2021

 1 Jan 30, 2022
1 Jan 30, 2022
 1 Dec 4, 2021
1 Dec 4, 2021
 2 Nov 14, 2022
2 Nov 14, 2022
 2 Dec 19, 2021
2 Dec 19, 2021
 1 Jan 13, 2022
1 Jan 13, 2022
 9 Aug 16, 2022
9 Aug 16, 2022
 12 Nov 9, 2022
12 Nov 9, 2022
 31 Nov 1, 2022
31 Nov 1, 2022
 13 Oct 11, 2022
13 Oct 11, 2022
 1 Feb 10, 2022
1 Feb 10, 2022