Filter By
146 Repositories
Python Text Processing
Fixes mojibake and other glitches in Unicode text, after the fact.
ftfy: fixes text for you print(fix_encoding("(ง'⌣')ง")) (ง'⌣')ง Full documentation: https://ftfy.readthedocs.org Testimonials “My life is li
 3.4k Jan 8, 2023
3.4k Jan 8, 2023
Python character encoding detector
Chardet: The Universal Character Encoding Detector Detects ASCII, UTF-8, UTF-16 (2 variants), UTF-32 (4 variants) Big5, GB2312, EUC-TW, HZ-GB-2312, IS
 1.8k Jan 8, 2023
1.8k Jan 8, 2023
Fuzzy String Matching in Python
FuzzyWuzzy Fuzzy string matching like a boss. It uses Levenshtein Distance to calculate the differences between sequences in a simple-to-use package.
 8.8k Jan 8, 2023
8.8k Jan 8, 2023
Answer some questions and get your brawler csvs ready!
BRAWL-STARS-V11-BRAWLER-MAKER-TOOL Answer some questions and get your brawler csvs ready! HOW TO RUN on android: Install pydroid3 from playstore, and
 9 Jan 7, 2023
9 Jan 7, 2023

An experimental Fang Song style Chinese font generated with skeleton-tracing and pix2pix
An experimental Fang Song style Chinese font generated with skeleton-tracing and pix2pix, with glyphs based on cwTeXFangSong. The font is optimised fo
 98 Jan 7, 2023
98 Jan 7, 2023
一款高性能敏感词(非法词/脏字)检测过滤组件,附带繁体简体互换,支持全角半角互换,汉字转拼音,模糊搜索等功能。
一款高性能非法词(敏感词)检测组件,附带繁体简体互换,支持全角半角互换,获取拼音首字母,获取拼音字母,拼音模糊搜索等功能。
 3.6k Jan 7, 2023
3.6k Jan 7, 2023
Convert ebooks with few clicks on Telegram!
E-Book Converter Bot A bot that converts e-books to various formats, powered by calibre! It currently supports 34 input formats and 19 output formats.
 45 Jan 5, 2023
45 Jan 5, 2023
A non-validating SQL parser module for Python
python-sqlparse - Parse SQL statements sqlparse is a non-validating SQL parser for Python. It provides support for parsing, splitting and formatting S
 3.1k Jan 4, 2023
3.1k Jan 4, 2023
Returns unicode slugs
Python Slugify A Python slugify application that handles unicode. Overview Best attempt to create slugs from unicode strings while keeping it DRY. Not
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
🐸 Identify anything. pyWhat easily lets you identify emails, IP addresses, and more. Feed it a .pcap file or some text and it'll tell you what it is! 🧙♀️
🐸 Identify anything. pyWhat easily lets you identify emails, IP addresses, and more. Feed it a .pcap file or some text and it'll tell you what it is! 🧙♀️
 5.6k Jan 3, 2023
5.6k Jan 3, 2023
汉字转拼音(pypinyin)
汉字拼音转换工具(Python 版) 将汉字转为拼音。可以用于汉字注音、排序、检索(Russian translation) 。 基于 hotoo/pinyin 开发。 Documentation: http://pypinyin.rtfd.io/ GitHub: https://github.co
 4.2k Jan 3, 2023
4.2k Jan 3, 2023
An implementation of figlet written in Python
All of the documentation and the majority of the work done was by Christopher Jones ([email protected]). Packaged by Peter Waller [email protected],
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
Compute distance between sequences. 30+ algorithms, pure python implementation, common interface, optional external libs usage.
TextDistance TextDistance -- python library for comparing distance between two or more sequences by many algorithms. Features: 30+ algorithms Pure pyt
 3k Jan 2, 2023
3k Jan 2, 2023
Implementation of hashids (http://hashids.org) in Python. Compatible with Python 2 and Python 3
hashids for Python 2.7 & 3 A python port of the JavaScript hashids implementation. It generates YouTube-like hashes from one or many numbers. Use hash
 1.4k Jan 2, 2023
1.4k Jan 2, 2023
Fuzzy string matching like a boss. It uses Levenshtein Distance to calculate the differences between sequences in a simple-to-use package.
Fuzzy string matching like a boss. It uses Levenshtein Distance to calculate the differences between sequences in a simple-to-use package.
1.2k Jan 1, 2023
Amazing GitHub Template - Sane defaults for your next project!
🚀 Useful README.md, LICENSE, CONTRIBUTING.md, CODE_OF_CONDUCT.md, SECURITY.md, GitHub Issues and Pull Requests and Actions templates to jumpstart your projects.
 276 Jan 1, 2023
276 Jan 1, 2023
A generator library for concise, unambiguous and URL-safe UUIDs.
Description shortuuid is a simple python library that generates concise, unambiguous, URL-safe UUIDs. Often, one needs to use non-sequential IDs in pl
 1.8k Dec 31, 2022
1.8k Dec 31, 2022
Python Lex-Yacc
PLY (Python Lex-Yacc) Copyright (C) 2001-2020 David M. Beazley (Dabeaz LLC) All rights reserved. Redistribution and use in source and binary forms, wi
 2.4k Dec 31, 2022
2.4k Dec 31, 2022
从flomo导出的笔记中生成词云
flomo-word-cloud 从flomo导出的笔记中生成词云 如何使用? 将本项目克隆到你的电脑上,使用如下的命令,安装所需python库 pip install -r requirements.txt 在项目里新建一个file文件夹,把所有从flomo导出的html文件放入其中 运行main
 9 Dec 30, 2022
9 Dec 30, 2022
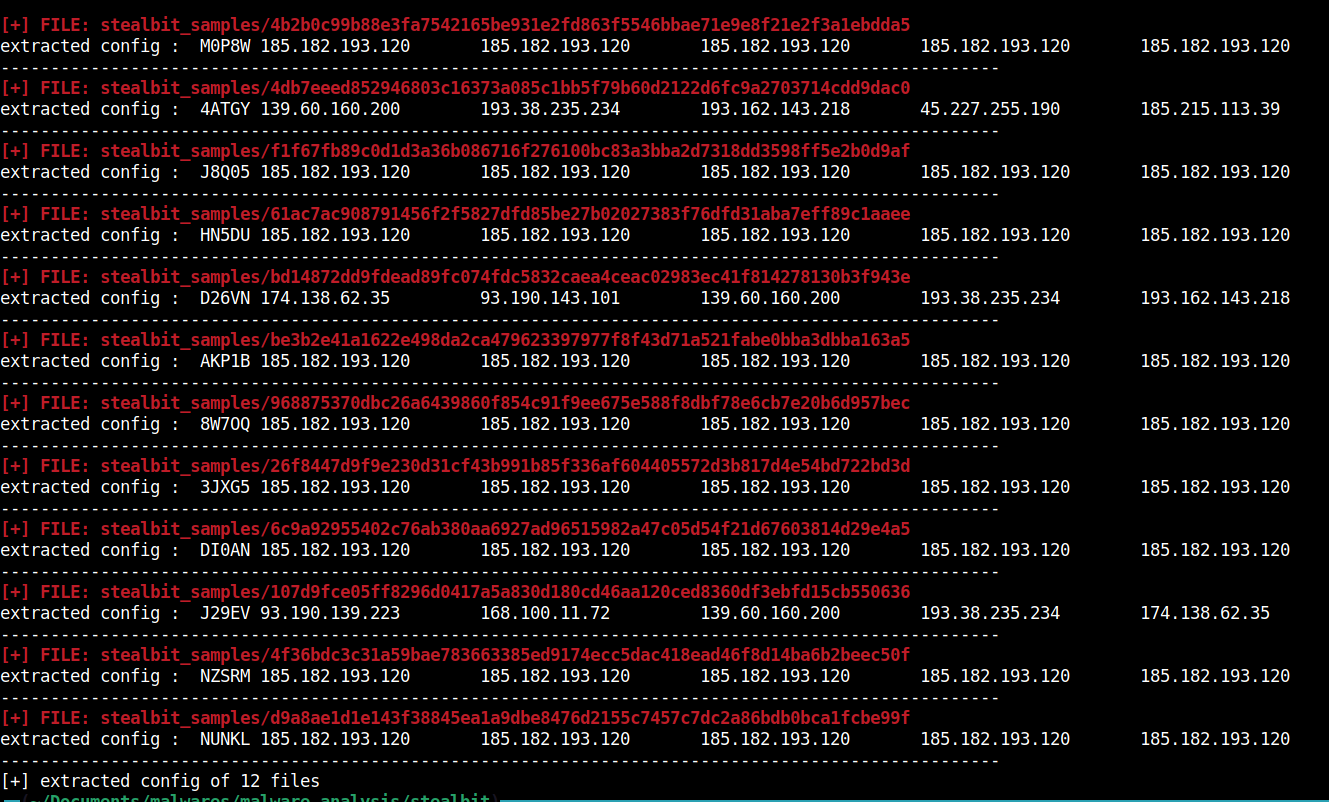
StealBit1.1 and earlier strings and config extraction scripts
StealBit1.1 and earlier scripts Use strings_decryptor.py to extract RC4 encrypted strings from a StealBit1.1 sample(s). Use config_extractor.py to ext
 5 Dec 29, 2022
5 Dec 29, 2022
Widevine KEY Extractor in Python
Widevine Client 3 This was originally written by T3rry7f. This repo is slightly modified version of his repo. This only works on standard Windows! Usa
 68 Dec 29, 2022
68 Dec 29, 2022
一个可以可以统计群组用户发言,并且能将聊天内容生成词云的机器人
当前版本 v2.2 更新维护日志 更新维护日志 有问题请加群组反馈 Telegram 交流反馈群组 点击加入 演示 配置要求 内存:1G以上 安装方法 使用 Docker 安装 Docker官方安装
 117 Dec 29, 2022
117 Dec 29, 2022
Python port of Google's libphonenumber
phonenumbers Python Library This is a Python port of Google's libphonenumber library It supports Python 2.5-2.7 and Python 3.x (in the same codebase,
 3.1k Dec 29, 2022
3.1k Dec 29, 2022
Python library for creating PEG parsers
PyParsing -- A Python Parsing Module Introduction The pyparsing module is an alternative approach to creating and executing simple grammars, vs. the t
 1.7k Dec 27, 2022
1.7k Dec 27, 2022
BaseCrack is a tool written in Python that can decode all alphanumeric base encoding schemes.
BaseCrack Decoder For Base Encoding Schemes BaseCrack is a tool written in Python that can decode all alphanumeric base encoding schemes. This tool ca
 383 Dec 27, 2022
383 Dec 27, 2022
PyMultiDictionary is a Dictionary Module for Python 3+ to get meanings, translations, synonyms and antonyms of words in 20 different languages
PyMultiDictionary PyMultiDictionary is a Dictionary Module for Python 3+ to get meanings, translations, synonyms and antonyms of words in 20 different
 19 Dec 26, 2022
19 Dec 26, 2022

Make writing easier!
Handwriter Make writing easier! How to Download and install a handwriting font, or create a font from your handwriting. Use a word processor like Micr
 64 Dec 25, 2022
64 Dec 25, 2022

box is a text-based visual programming language inspired by Unreal Engine Blueprint function graphs.
Box is a text-based visual programming language inspired by Unreal Engine blueprint function graphs. $ cat factorial.box ┌─ƒ(Factorial)───┐
 104 Dec 24, 2022
104 Dec 24, 2022

Wikipedia Reader for the GNOME Desktop
Wike Wike is a Wikipedia reader for the GNOME Desktop. Provides access to all the content of this online encyclopedia in a native application, with a
 126 Dec 24, 2022
126 Dec 24, 2022
A Python library that provides an easy way to identify devices like mobile phones, tablets and their capabilities by parsing (browser) user agent strings.
Python User Agents user_agents is a Python library that provides an easy way to identify/detect devices like mobile phones, tablets and their capabili
 1.3k Dec 22, 2022
1.3k Dec 22, 2022
pydantic-i18n is an extension to support an i18n for the pydantic error messages.
pydantic-i18n is an extension to support an i18n for the pydantic error messages
 48 Dec 21, 2022
48 Dec 21, 2022
Python flexible slugify function
awesome-slugify Python flexible slugify function PyPi: https://pypi.python.org/pypi/awesome-slugify Github: https://github.com/dimka665/awesome-slugif
 471 Dec 20, 2022
471 Dec 20, 2022
A simple Python module for parsing human names into their individual components
Name Parser A simple Python (3.2+ & 2.6+) module for parsing human names into their individual components. hn.title hn.first hn.middle hn.last hn.suff
 574 Dec 20, 2022
574 Dec 20, 2022
AnnIE - Annotation Platform, tool for open information extraction annotations using text files.
AnnIE - Annotation Platform, tool for open information extraction annotations using text files.
 29 Dec 20, 2022
29 Dec 20, 2022
You can encode and decode base85, ascii85, base64, base32, and base16 with this tool.
You can encode and decode base85, ascii85, base64, base32, and base16 with this tool.
 8 Dec 20, 2022
8 Dec 20, 2022
Repositori untuk belajar pemrograman Python dalam bahasa Indonesia
Python Repositori ini berisi kumpulan dari berbagai macam contoh struktur data, algoritma dan komputasi matematika yang diimplementasikan dengan mengg
 111 Dec 19, 2022
111 Dec 19, 2022

Find a Doc is a free online resource aimed at helping connect the foreign community in Japan with health services in their native language.
Find a Doc - Localization Find a Doc is a free online resource aimed at helping connect the foreign community in Japan with health services in their n
 18 Dec 19, 2022
18 Dec 19, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022
The Levenshtein Python C extension module contains functions for fast computation of Levenshtein distance and string similarity
Contents Maintainer wanted Introduction Installation Documentation License History Source code Authors Maintainer wanted I am looking for a new mainta
 1.2k Dec 16, 2022
1.2k Dec 16, 2022

Athens: a great tool for taking notes and organising knowldge
AthensSyncer Athens is a great tool for taking notes and organising knowldge. But it is a bummer that you cannot use it accross multiple devices. Well
 6 Dec 14, 2022
6 Dec 14, 2022
Meeting, rendezvous, confluence (Finnish kohtaaminen) mark up, down, and up again.
kohtaaminen Meeting, rendezvous, confluence (Finnish kohtaaminen) mark up, down, and up again. Given a zip file containing a tree of html and media fi
 2 Dec 14, 2022
2 Dec 14, 2022
Fuzz a language by mixing up only few words.
afasi Fuzz a language by mixing up only few words. Status Beta. Note: The default branch is default. Use Examples Version General Help Translate Help
2 Dec 14, 2022
a python package that lets you add custom colors and text formatting to your scripts in a very easy way!
colormate Python script text formatting package What is colormate? colormate is a python library that lets you add text formatting to your scripts, it
 2 Dec 14, 2022
2 Dec 14, 2022

A Python app which can convert normal text to Handwritten text.
Text to HandWritten Text ✍️ Converter Watch Tutorial for this project Usage:- Clone my repository. Open CMD in working directory. Run following comman
 5 Dec 11, 2022
5 Dec 11, 2022
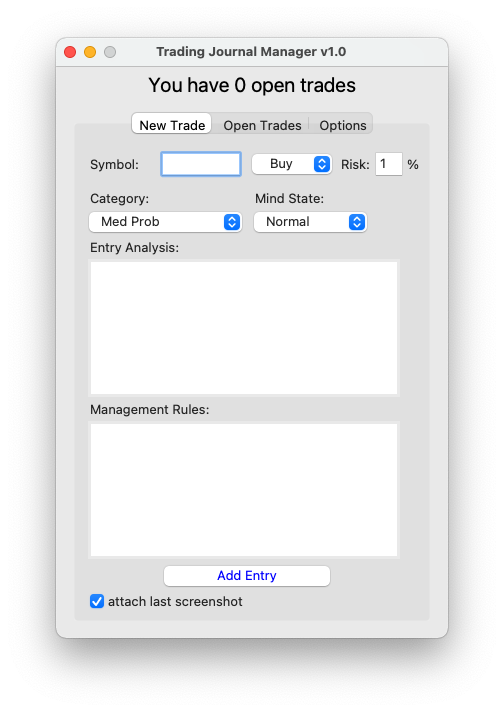
A python Tk GUI that creates, writes text and attaches images into a custom spreadsheet file
A python Tk GUI that creates, writes text and attaches images into a custom spreadsheet file
 13 Dec 9, 2022
13 Dec 9, 2022

RSS Reader application for the Emacs Application Framework.
EAF RSS Reader RSS Reader application for the Emacs Application Framework. Load application (add-to-list 'load-path "~/.emacs.d/site-lisp/eaf-rss-read
 15 Dec 7, 2022
15 Dec 7, 2022
Map Reduce Wordcount in Python using gRPC
This project is implemented in Python using gRPC. The input files are given in .txt format and the word count operation is performed.
 4 Dec 5, 2022
4 Dec 5, 2022

A python tool one can extract the "hash" from a WINDOWS HELLO PIN
WINHELLO2hashcat About With this tool one can extract the "hash" from a WINDOWS HELLO PIN. This hash can be cracked with Hashcat, more precisely with
 33 Dec 5, 2022
33 Dec 5, 2022
Extract knowledge from raw text
Extract knowledge from raw text This repository is a nearly copy-paste of "From Text to Knowledge: The Information Extraction Pipeline" with some cosm
 10 Dec 3, 2022
10 Dec 3, 2022
ChirpText is a collection of text processing tools for Python 3.
ChirpText is a collection of text processing tools for Python 3. It is not meant to be a powerful tank like the popular NTLK but a small package which
 5 Nov 30, 2022
5 Nov 30, 2022
A username generator made from French Canadian most common names.
This script is used to generate a username list using the most common first and last names in Quebec in different formats. It can generate some passwords using specific patterns such as Tremblay2020.
 5 Nov 26, 2022
5 Nov 26, 2022

Auto translate Localizable.strings for multiple languages in Xcode
auto_localize Auto translate Localizable.strings for multiple languages in Xcode Usage put your origin Localizable.strings file in folder pip3 install
 13 Nov 22, 2022
13 Nov 22, 2022
A slugifier that works in unicode
Unicode Slugify Unicode Slugify is a slugifier that generates unicode slugs. It was originally used in the Firefox Add-ons web site to generate slugs
 315 Nov 21, 2022
315 Nov 21, 2022
Aml - anti-money laundering
Anti-money laundering Dedect relationship between A and E by tracing through payments with similar amounts and identifying payment chains. For example
 3 Nov 21, 2022
3 Nov 21, 2022