Describe the bug
A clear and concise description of what the bug is.
Programs get blocked when using multiple nodes. By setting export LOG_LEVEL=DEBUG, I can see that it got stuck at BaguaSingleCommunicator, since it prints
2022-11-21T12:40:23.673510Z DEBUG bagua_core_internal::communicators: creating communicator, nccl_unique_id AgCwgcCQEwkAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA=, rank 8, nranks 16, device_id 0, stream_ptr 94639511762624
but fail to print
al communicator initialized at XXX.
When I set --node_rank=0, the program can run smoothly.
Environment
- Your operating system and version: Linux node-162 4.4.0-131-generic #157-Ubuntu SMP Thu Jul 12 15:51:36 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
- Your python version: Python 3.8.13 (default, Mar 28 2022, 11:38:47)
- Your PyTorch version: 1.12.1
- NCCL version: 2.10.3
- How did you install python (e.g. apt or pyenv)? Did you use a virtualenv?: conda
- Have you tried using latest bagua master (
python3 -m pip install --pre bagua)?: yes
Reproducing
Please provide a minimal working example. This means the runnable code.
import argparse
from ast import arg
from curses import baudrate
import os
import random
import shutil
import time
import warnings
import logging
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
from torch.utils.tensorboard import SummaryWriter
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
import bagua.torch_api as bagua
from bisect import bisect_right
from pathlib import Path
model_names = sorted(
name
for name in models.__dict__
if name.islower() and not name.startswith("__") and callable(models.__dict__[name])
)
parser = argparse.ArgumentParser(description="PyTorch ImageNet Training")
parser.add_argument("data", metavar="DIR", help="path to dataset")
parser.add_argument(
"-a",
"--arch",
metavar="ARCH",
default="resnet18",
choices=model_names,
help="model architecture: " + " | ".join(model_names) + " (default: resnet18)",
)
parser.add_argument(
"-j",
"--workers",
default=4,
type=int,
metavar="N",
help="number of data loading workers (default: 4)",
)
parser.add_argument(
"--epochs", default=90, type=int, metavar="N", help="number of total epochs to run"
)
parser.add_argument(
"--warmup-epochs", type=float, default=5, help="number of warmup epochs"
)
parser.add_argument(
"--start-epoch",
default=0,
type=int,
metavar="N",
help="manual epoch number (useful on restarts)",
)
parser.add_argument(
"-b",
"--batch-size",
default=256,
type=int,
metavar="N",
help="mini-batch size (default: 256), this is the total "
"batch size of all GPUs on the current node when "
"using Data Parallel or Distributed Data Parallel",
)
parser.add_argument(
"--lr",
"--learning-rate",
default=0.1,
type=float,
metavar="LR",
help="initial learning rate",
dest="lr",
)
parser.add_argument("--momentum", default=0.9, type=float, metavar="M", help="momentum")
parser.add_argument(
"--wd",
"--weight-decay",
default=1e-4,
type=float,
metavar="W",
help="weight decay (default: 1e-4)",
dest="weight_decay",
)
parser.add_argument(
"--milestones",
default="60,70,80",
type=str,
help="multi-step learning rate scheduler milestones",
)
parser.add_argument(
"--gama",
type=float,
default=0.2,
help="multiplicative factor of learning rate decay",
)
parser.add_argument(
"-p",
"--print-freq",
default=10,
type=int,
metavar="N",
help="print frequency (default: 10)",
)
parser.add_argument(
"--resume",
default="",
type=str,
metavar="PATH",
help="path to latest checkpoint (default: none)",
)
parser.add_argument(
"--save-checkpoint", action="store_true", default=False, help="save checkpoint"
)
parser.add_argument(
"-e",
"--evaluate",
dest="evaluate",
action="store_true",
help="evaluate model on validation set",
)
parser.add_argument(
"--pretrained", dest="pretrained", action="store_true", help="use pre-trained model"
)
parser.add_argument(
"--seed", default=None, type=int, help="seed for initializing training. "
)
parser.add_argument(
"--amp",
action="store_true",
default=False,
help="use amp",
)
parser.add_argument(
"--prof", default=-1, type=int, help="Only run 10 iterations for profiling."
)
parser.add_argument(
"--algorithm",
type=str,
default="gradient_allreduce",
help="distributed algorithm: {gradient_allreduce, bytegrad, decentralized, low_precision_decentralized, qadam, async}",
)
parser.add_argument(
"--async-sync-interval",
default=500,
type=int,
help="Model synchronization interval(ms) for async algorithm",
)
parser.add_argument(
"--async-warmup-steps",
default=100,
type=int,
help="Warmup(allreduce) steps for async algorithm",
)
parser.add_argument(
"--ckpt-dir",
default="./ckpt/ckpt",
type=str,
help="The floder saving ckpt file",
)
parser.add_argument(
"--log-dir",
default="./log/log",
type=str,
help="The floder saving tensorboard log",
)
best_acc1 = 0
summary_writer = None
my_global_step = 0
def main():
args = parser.parse_args()
if args.seed is not None:
random.seed(args.seed)
torch.manual_seed(args.seed)
cudnn.deterministic = True
warnings.warn(
"You have chosen to seed training. "
"This will turn on the CUDNN deterministic setting, "
"which can slow down your training considerably! "
"You may see unexpected behavior when restarting "
"from checkpoints."
)
torch.cuda.set_device(bagua.get_local_rank())
bagua.init_process_group()
args.distributed = bagua.get_world_size() > 1
logging.basicConfig(
format="rank-{} %(asctime)s,%(msecs)d %(levelname)-8s [%(filename)s:%(lineno)d] %(message)s".format(
bagua.get_rank()
),
datefmt="%Y-%m-%d:%H:%M:%S",
level=logging.ERROR,
)
if bagua.get_rank() == 0:
logging.getLogger().setLevel(logging.INFO)
main_worker(args)
def main_worker(args):
global best_acc1
global summary_writer
summary_writer = SummaryWriter(log_dir=args.log_dir)
# create model
if args.pretrained:
print("=> using pre-trained model '{}'".format(args.arch))
model = models.__dict__[args.arch](pretrained=True)
else:
print("=> creating model '{}'".format(args.arch))
model = models.__dict__[args.arch]()
model = model.cuda()
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(
model.parameters(),
args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay,
)
if args.algorithm == "gradient_allreduce":
from bagua.torch_api.algorithms import gradient_allreduce
algorithm = gradient_allreduce.GradientAllReduceAlgorithm()
else:
raise NotImplementedError
scaler = torch.cuda.amp.GradScaler(enabled=args.amp)
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
# Map model to be loaded to specified single gpu.
loc = "cuda:{}".format(bagua.get_local_rank())
checkpoint = torch.load(args.resume, map_location=loc)
args.start_epoch = checkpoint["epoch"]
best_acc1 = checkpoint["best_acc1"]
if bagua.get_local_rank() is not None:
# best_acc1 may be from a checkpoint from a different GPU
best_acc1 = best_acc1.to(bagua.get_local_rank())
model.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
print(
"=> loaded checkpoint '{}' (epoch {})".format(
args.resume, checkpoint["epoch"]
)
)
else:
print("=> no checkpoint found at '{}'".format(args.resume))
if args.distributed:
_test_rank = bagua.get_rank()
model = model.with_bagua(
[optimizer],
algorithm,
)
cudnn.benchmark = True
# Data loading code
traindir = os.path.join(args.data, "train")
valdir = os.path.join(args.data, "val")
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
)
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]
),
)
val_dataset = datasets.ImageFolder(
valdir,
transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]
),
)
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
num_workers=args.workers,
pin_memory=True,
sampler=train_sampler,
)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=args.workers,
pin_memory=True,
)
if args.evaluate:
validate(val_loader, model, criterion, 0, args)
return
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
train_sampler.set_epoch(epoch)
if args.algorithm == "async":
model.bagua_algorithm.resume(model)
# train for one epoch
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
train(train_loader, model, criterion, optimizer, scaler, epoch, args)
end.record()
# Waits for everything to finish running
torch.cuda.synchronize()
elapsed_time = start.elapsed_time(end)
write_scalar(tag='train/epoch_training_time', scalar_value=elapsed_time, global_step=epoch)
if args.algorithm == "async":
model.bagua_algorithm.abort(model)
# evaluate on validation set
acc1 = validate(val_loader, model, criterion, epoch, args)
# remember best acc@1 and save checkpoint
is_best = acc1 > best_acc1
best_acc1 = max(acc1, best_acc1)
if bagua.get_rank() == 0 and args.save_checkpoint:
save_checkpoint(
{
"epoch": epoch + 1,
"arch": args.arch,
"state_dict": model.state_dict(),
"best_acc1": best_acc1,
"optimizer": optimizer.state_dict(),
},
is_best,
dir=args.ckpt_dir
)
def train(train_loader, model, criterion, optimizer, scaler, epoch, args):
global my_global_step
batch_time = AverageMeter("Time", ":6.3f")
data_time = AverageMeter("Data", ":6.3f")
losses = AverageMeter("Loss", ":.4e")
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
progress = ProgressMeter(
len(train_loader),
[batch_time, data_time, losses, top1, top5],
prefix="Epoch: [{}]".format(epoch),
)
# switch to train mode
model.train()
end = time.time()
for i, (images, target) in enumerate(train_loader):
if args.prof >= 0 and i == args.prof:
print("Profiling begun at iteration {}".format(i))
torch.cuda.cudart().cudaProfilerStart()
if args.prof >= 0:
torch.cuda.nvtx.range_push("Body of iteration {}".format(i))
# measure data loading time
data_time.update(time.time() - end)
if torch.cuda.is_available():
images = images.cuda(bagua.get_local_rank(), non_blocking=True)
target = target.cuda(bagua.get_local_rank(), non_blocking=True)
adjust_learning_rate(optimizer, epoch, i, len(train_loader), args)
optimizer.zero_grad()
if args.prof >= 0:
torch.cuda.nvtx.range_push("forward")
with torch.cuda.amp.autocast(enabled=args.amp):
# compute output
output = model(images)
loss = criterion(output, target)
if args.prof >= 0:
torch.cuda.nvtx.range_pop()
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images.size(0))
top1.update(acc1[0], images.size(0))
top5.update(acc5[0], images.size(0))
if args.prof >= 0:
torch.cuda.nvtx.range_push("backward")
# compute gradient and do SGD step
scaler.scale(loss).backward()
if args.prof >= 0:
torch.cuda.nvtx.range_pop()
if args.prof >= 0:
torch.cuda.nvtx.range_push("optimizer.step()")
scaler.step(optimizer)
scaler.update()
if args.prof >= 0:
torch.cuda.nvtx.range_pop()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i)
write_scalar(tag='train/acc_top1', scalar_value=top1.get_avg(), global_step=my_global_step)
write_scalar(tag='train/acc_top5', scalar_value=top5.get_avg(), global_step=my_global_step)
# Pop range "Body of iteration {}".format(i)
if args.prof >= 0:
torch.cuda.nvtx.range_pop()
if args.prof >= 0 and i == args.prof + 10:
print("Profiling ended at iteration {}".format(i))
torch.cuda.cudart().cudaProfilerStop()
if args.algorithm == "async":
model.bagua_algorithm.abort(model)
quit()
def validate(val_loader, model, criterion, epoch, args):
batch_time = AverageMeter("Time", ":6.3f")
losses = AverageMeter("Loss", ":.4e")
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
progress = ProgressMeter(
len(val_loader), [batch_time, losses, top1, top5], prefix="Test: "
)
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (images, target) in enumerate(val_loader):
if torch.cuda.is_available():
images = images.cuda(bagua.get_local_rank(), non_blocking=True)
target = target.cuda(bagua.get_local_rank(), non_blocking=True)
# compute output
output = model(images)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images.size(0))
top1.update(acc1[0], images.size(0))
top5.update(acc5[0], images.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i)
# TODO: this should also be done with the ProgressMeter
logging.info(
" * TEST Epoch {} Acc@1 {top1.avg:.3f} Acc@5 {top5.avg:.3f}".format(
epoch, top1=top1, top5=top5
)
)
write_scalar(tag='validation/acc_top1', scalar_value=top1.get_avg(), global_step=epoch)
write_scalar(tag='validation/acc_top5', scalar_value=top5.get_avg(), global_step=epoch)
return top1.avg
def write_scalar(tag, scalar_value, global_step):
global summary_writer
if bagua.get_rank() == 0:
summary_writer.add_scalar(tag=tag, scalar_value=scalar_value, global_step=global_step)
def save_checkpoint(state, is_best, dir="./ckpt/dir"):
dir = Path(dir)
if not dir.exists():
dir.mkdir(parents=True)
file_name = dir / "checkpoint.pth.tar"
torch.save(state, file_name)
if is_best:
shutil.copyfile(file_name, dir / "model_best.pth.tar")
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=":f"):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = "{name} {val" + self.fmt + "} ({avg" + self.fmt + "})"
return fmtstr.format(**self.__dict__)
def get_avg(self):
return self.avg
class ProgressMeter(object):
def __init__(self, num_batches, meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
logging.info("\t".join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = "{:" + str(num_digits) + "d}"
return "[" + fmt + "/" + fmt.format(num_batches) + "]"
def adjust_learning_rate(optimizer, epoch, step, len_epoch, args):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
# lr = args.lr * (0.1 ** (epoch // 30))
# for param_group in optimizer.param_groups:
# param_group["lr"] = lr
milestones = [int(i) for i in args.milestones.split(",")]
lr = args.lr * (args.gama ** bisect_right(milestones, epoch))
"""Warmup"""
if epoch < args.warmup_epochs:
lr = (
lr
* float(1 + step + epoch * len_epoch)
/ float(args.warmup_epochs * len_epoch)
)
# logging.info("epoch = {}, step = {}, lr = {}".format(epoch, step, lr))
for param_group in optimizer.param_groups:
param_group["lr"] = lr
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
if __name__ == "__main__":
main()
Please also write what exact commands are required to reproduce your results.
python -m bagua.distributed.launch \
--nproc_per_node=8 --nnodes=1 --node_rank=0 \
--master_addr="10.154.34.164" --master_port=34498 \
main.py \
--arch=resnet50 \
--save-checkpoint \
--lr 0.2 \
--batch-size 64 \
--print-freq 100 \
--algorithm gradient_allreduce \
--resume ./ckpt/multi_node_gradient_allreduce \
--ckpt-dir ./ckpt/multi_node_gradient_allreduce \
--log-dir ./log/multi_node_gradient_allreduce \
$DATA_PATH
Additional context
Add any other context about the problem here.

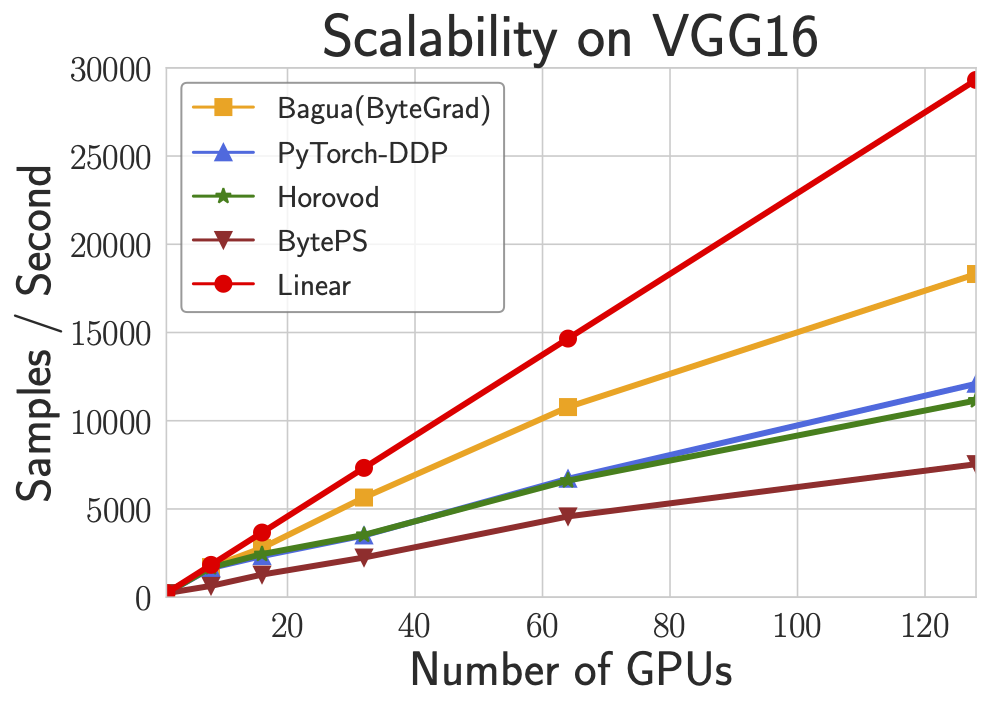
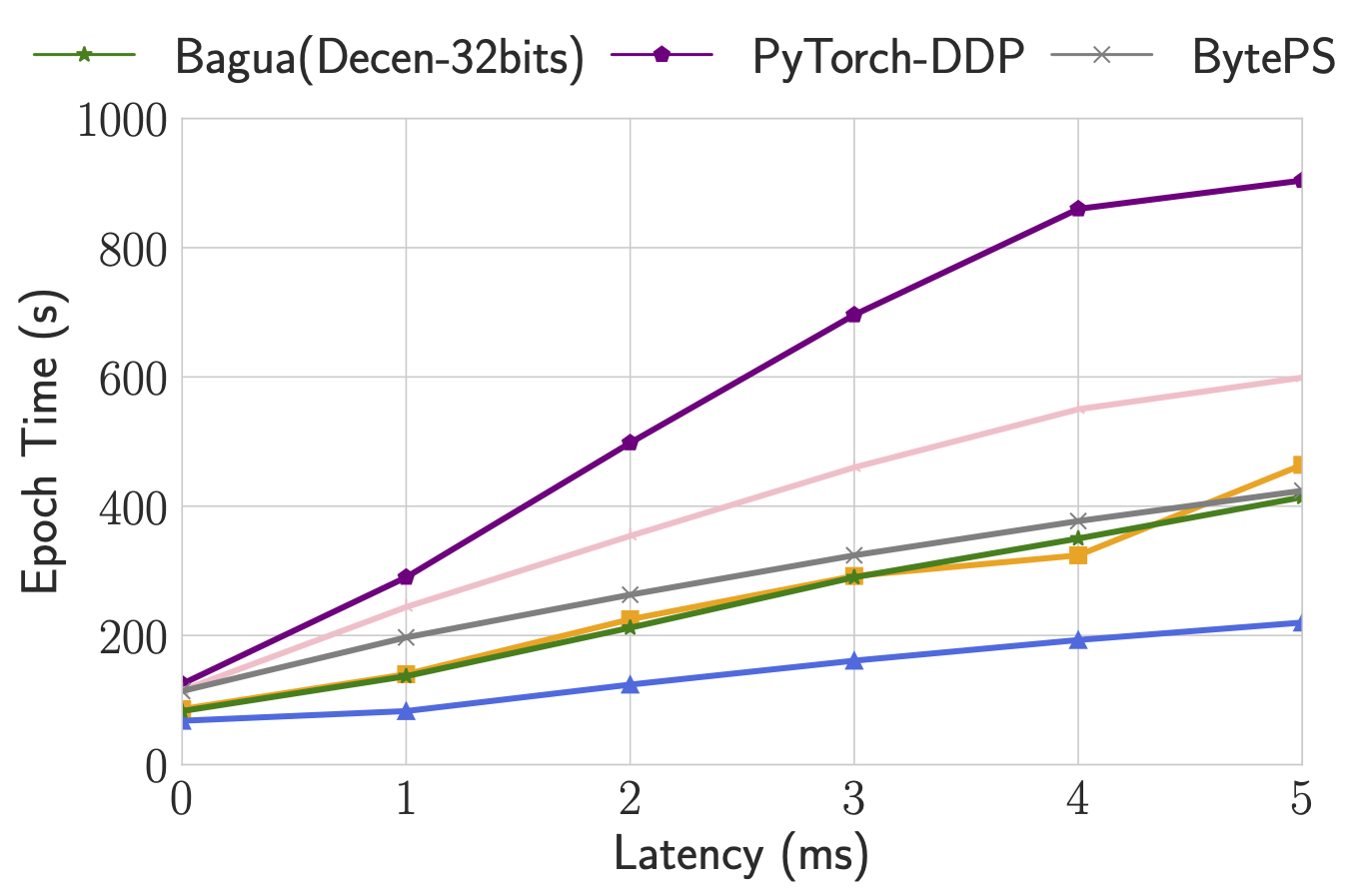
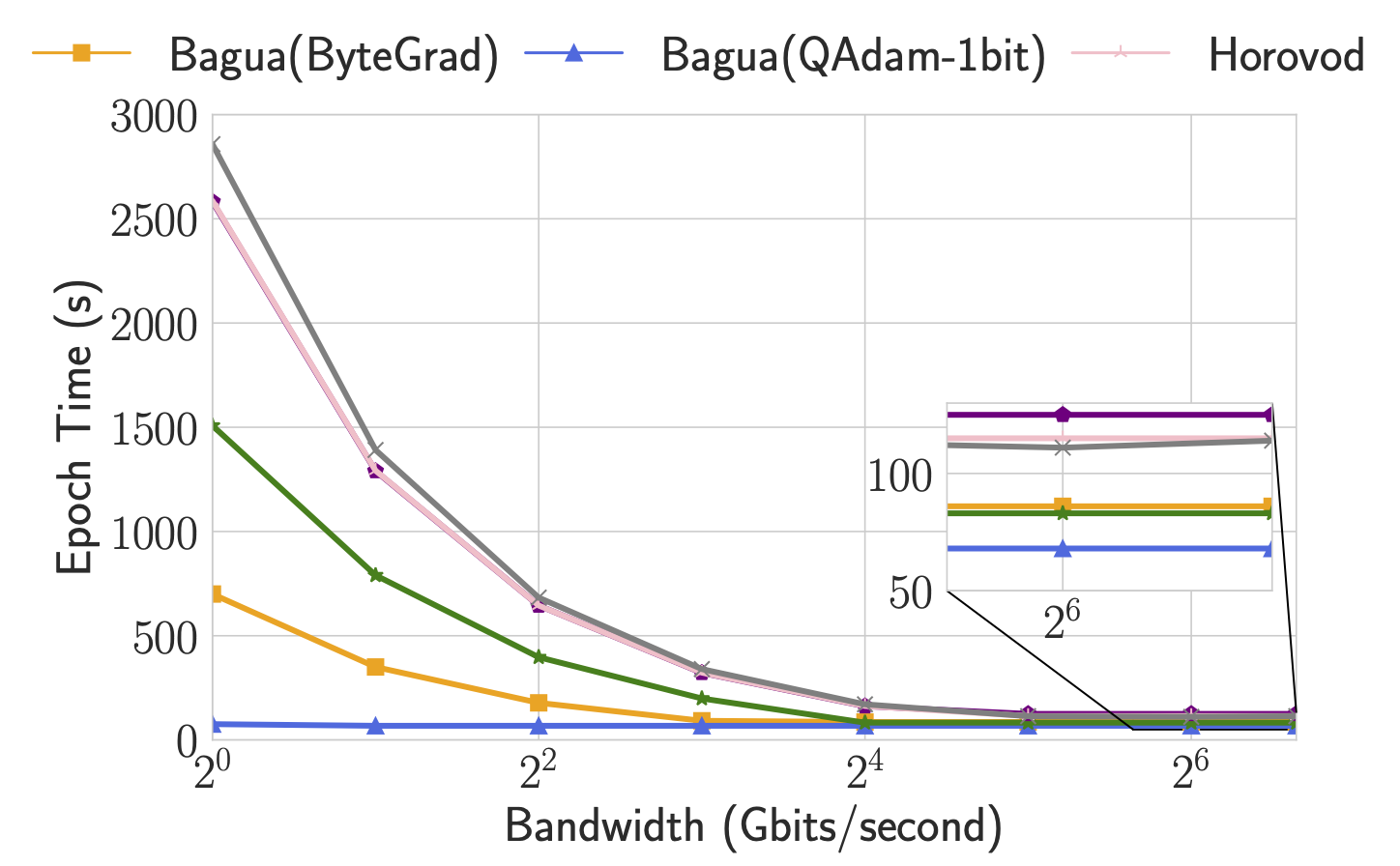











 20.2k Jan 8, 2023
20.2k Jan 8, 2023
 29 Nov 16, 2022
29 Nov 16, 2022
 161 Jan 6, 2023
161 Jan 6, 2023
 463 Dec 9, 2022
463 Dec 9, 2022
 26 Dec 12, 2022
26 Dec 12, 2022
 721 Jan 3, 2023
721 Jan 3, 2023
 114 Dec 27, 2022
114 Dec 27, 2022
 208 Dec 20, 2022
208 Dec 20, 2022
 185 Dec 21, 2022
185 Dec 21, 2022
 7 Apr 5, 2022
7 Apr 5, 2022
 84 Jan 4, 2023
84 Jan 4, 2023
 6.9k Jan 3, 2023
6.9k Jan 3, 2023
 8.4k Jan 1, 2023
8.4k Jan 1, 2023
 5 Sep 29, 2021
5 Sep 29, 2021
 997 Dec 30, 2022
997 Dec 30, 2022
 9 Jul 11, 2022
9 Jul 11, 2022
 3 Nov 23, 2021
3 Nov 23, 2021