********** feapder begin **********
Thread-5|2021-03-31 15:51:30,281|proxy_pool.py|reset_proxy_pool|line:664|DEBUG| 重置代理池成功: 获取5, 成功添加5, 失效0, 当前代理数5,
Thread-5|2021-03-31 15:51:30,809|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:33,600|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:33,600|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:33,600|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 10
Thread-5|2021-03-31 15:51:34,604|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:34,604|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:34,604|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 20
Thread-5|2021-03-31 15:51:35,608|proxy_pool.py|reset_proxy_pool|line:664|DEBUG| 重置代理池成功: 获取5, 成功添加0, 失效5, 当前代理数0,
Thread-5|2021-03-31 15:51:35,608|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:35,608|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:35,608|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:35,608|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 30
Thread-5|2021-03-31 15:51:36,613|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:36,613|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 40
Thread-5|2021-03-31 15:51:37,617|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:37,617|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:37,617|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 50
Thread-5|2021-03-31 15:51:38,621|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:38,622|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 60
Thread-5|2021-03-31 15:51:39,626|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:39,626|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 70
Thread-5|2021-03-31 15:51:40,629|proxy_pool.py|reset_proxy_pool|line:664|DEBUG| 重置代理池成功: 获取5, 成功添加0, 失效5, 当前代理数0,
Thread-5|2021-03-31 15:51:40,629|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:40,629|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:40,629|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:40,629|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 80
Thread-5|2021-03-31 15:51:41,634|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:41,634|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:41,634|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 90
Thread-5|2021-03-31 15:51:42,638|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:42,638|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 100
Thread-5|2021-03-31 15:51:43,643|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:43,643|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:43,643|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 110
Thread-5|2021-03-31 15:51:44,646|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:44,646|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 120
Thread-5|2021-03-31 15:51:45,649|proxy_pool.py|reset_proxy_pool|line:664|DEBUG| 重置代理池成功: 获取5, 成功添加0, 失效5, 当前代理数0,
Thread-5|2021-03-31 15:51:45,649|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:45,650|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:45,650|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:45,650|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 130
Thread-5|2021-03-31 15:51:46,654|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:46,654|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:46,654|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 140
Thread-5|2021-03-31 15:51:47,659|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:47,659|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 150
Thread-5|2021-03-31 15:51:48,664|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:48,664|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 160
Thread-5|2021-03-31 15:51:49,666|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:49,666|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:49,666|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 170
Thread-5|2021-03-31 15:51:50,669|proxy_pool.py|reset_proxy_pool|line:664|DEBUG| 重置代理池成功: 获取5, 成功添加0, 失效5, 当前代理数0,
Thread-5|2021-03-31 15:51:50,669|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:50,669|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:50,669|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:50,670|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 180
Thread-5|2021-03-31 15:51:51,674|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:51,675|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:51,675|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 190
Thread-5|2021-03-31 15:51:52,679|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:52,680|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 200
Thread-5|2021-03-31 15:51:53,682|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:53,682|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:53,682|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 210
Thread-5|2021-03-31 15:51:54,687|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:54,687|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 220
Thread-5|2021-03-31 15:51:55,693|proxy_pool.py|reset_proxy_pool|line:664|DEBUG| 重置代理池成功: 获取5, 成功添加0, 失效5, 当前代理数0,
Thread-5|2021-03-31 15:51:55,693|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:55,693|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:55,693|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:55,693|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 230
Thread-5|2021-03-31 15:51:56,698|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:56,698|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:56,698|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 240
Thread-5|2021-03-31 15:51:57,701|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:57,701|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 250
Thread-5|2021-03-31 15:51:58,706|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:58,706|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:58,706|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 260
Thread-5|2021-03-31 15:51:59,711|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:51:59,711|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 270
Thread-5|2021-03-31 15:52:00,715|proxy_pool.py|reset_proxy_pool|line:664|DEBUG| 重置代理池成功: 获取5, 成功添加0, 失效5, 当前代理数0,
Thread-5|2021-03-31 15:52:00,715|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:52:00,715|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:52:00,715|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 280
Thread-5|2021-03-31 15:52:01,720|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:52:01,720|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:52:01,720|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 290
Thread-5|2021-03-31 15:52:02,721|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:52:02,722|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:52:02,722|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 300
Thread-5|2021-03-31 15:52:03,723|request.py|get_response|line:272|DEBUG| 暂无可用代理 ...
Thread-5|2021-03-31 15:52:03,723|proxy_pool.py|reset_proxy_pool|line:646|DEBUG| 代理池重置的太快了:) 310


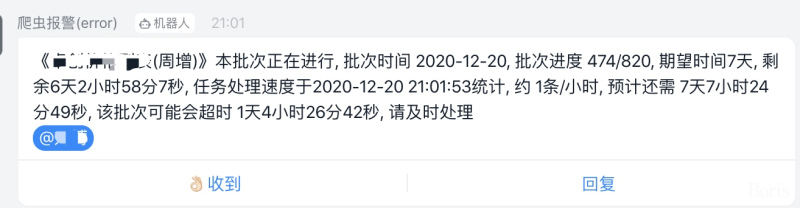
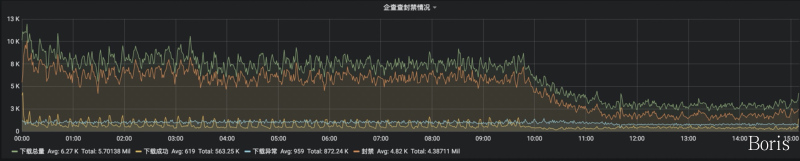













 你好,我在使用框架的时候遇到这样一个现象,可能会是一个潜在的隐患
我是直接在解析体里实例化Item,然后给Item的各个键赋值。
整个解析体会有一些条件分支,如下示例代码所示
一开始我没有注意到,因为大部分情况和我料想的一样
else语句里没有赋值的字段都是自动填充None到数据库的
但是后来发现,有的数据本来key_a, key_b, key_c需要有值的,实际上却只有一个status字段的值是1,其余均为空
定位到上面那张图的代码位置
原因我猜想是这样的,多条数据在一起入库,生成sql语句的时候,选择了列表中第一条记录的key,而第一条记录的key如果是else条件下赋值的,就会只有一个字段被使用,那么这一批一起入库的数据就只有一个字段入库了
不知作者能不能明白我的意思哈哈~
你好,我在使用框架的时候遇到这样一个现象,可能会是一个潜在的隐患
我是直接在解析体里实例化Item,然后给Item的各个键赋值。
整个解析体会有一些条件分支,如下示例代码所示
一开始我没有注意到,因为大部分情况和我料想的一样
else语句里没有赋值的字段都是自动填充None到数据库的
但是后来发现,有的数据本来key_a, key_b, key_c需要有值的,实际上却只有一个status字段的值是1,其余均为空
定位到上面那张图的代码位置
原因我猜想是这样的,多条数据在一起入库,生成sql语句的时候,选择了列表中第一条记录的key,而第一条记录的key如果是else条件下赋值的,就会只有一个字段被使用,那么这一批一起入库的数据就只有一个字段入库了
不知作者能不能明白我的意思哈哈~



