unpaper

Originally written by Jens Gulden — see AUTHORS for more information. Licensed under GNU GPL v2 — see COPYING for more information.
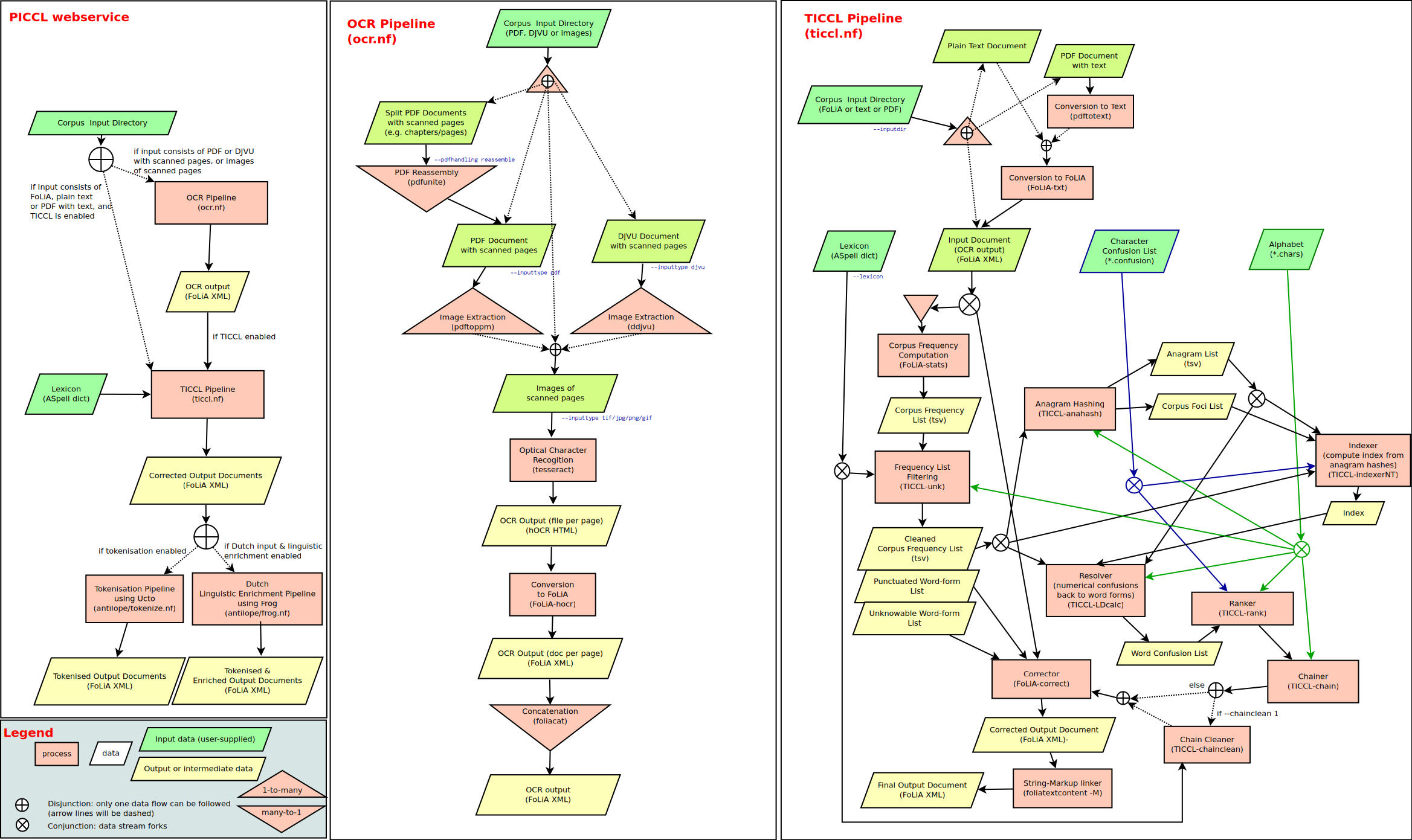
Overview
unpaper is a post-processing tool for scanned sheets of paper, especially for book pages that have been scanned from previously created photocopies. The main purpose is to make scanned book pages better readable on screen after conversion to PDF. Additionally, unpaper might be useful to enhance the quality of scanned pages before performing optical character recognition (OCR).
unpaper tries to clean scanned images by removing dark edges that appeared through scanning or copying on areas outside the actual page content (e.g. dark areas between the left-hand-side and the right-hand-side of a double- sided book-page scan).
The program also tries to detect misaligned centering and rotation of pages and will automatically straighten each page by rotating it to the correct angle. This process is called "deskewing".
Note that the automatic processing will sometimes fail. It is always a good idea to manually control the results of unpaper and adjust the parameter settings according to the requirements of the input. Each processing step can also be disabled individually for each sheet.
See further documentation for the supported file formats notes.
Dependencies
The only hard dependency of unpaper is ffmpeg, which is used for file input and output.
Building instructions
unpaper uses GNU Autotools for its build system, so you should be able to execute the same commands used for other software packages:
./configure
make
sudo make install
There are, though, some recommendations about the way you build the code. Since the tasks are calculation-intensive, it is important to build with optimizations turned on:
./configure CFLAGS="-O2 -march-native -pipe"
Even better, if your compiler supports it, is to use Link-Time Optimizations, as that has shown that execution time can improve sensibly:
./configure CFLAGS="-O2 -march=native -pipe -flto"
Further optimizations such as -ftracer and -ftree-vectorize are thought to work, but their effect has not been evaluated so your mileage may vary.
Further Information
You can find more information on the basic concepts and the image processing in the available documentation.
 41 Dec 27, 2022
41 Dec 27, 2022
 117 Nov 10, 2022
117 Nov 10, 2022
 684 Jan 6, 2023
684 Jan 6, 2023
 5.2k Dec 30, 2022
5.2k Dec 30, 2022

 190 Jan 3, 2023
190 Jan 3, 2023
 343 Dec 24, 2022
343 Dec 24, 2022
 111 Nov 27, 2022
111 Nov 27, 2022

 61 Dec 22, 2022
61 Dec 22, 2022
 648 Dec 30, 2022
648 Dec 30, 2022

 1.5k Dec 28, 2022
1.5k Dec 28, 2022
 127 Dec 3, 2022
127 Dec 3, 2022
 273 Jan 6, 2023
273 Jan 6, 2023
 243 Dec 30, 2022
243 Dec 30, 2022
 209 Dec 6, 2022
209 Dec 6, 2022
 165 Dec 31, 2022
165 Dec 31, 2022
 15 Nov 9, 2022
15 Nov 9, 2022
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
 7.9k Jan 3, 2023
7.9k Jan 3, 2023
 1 Jan 28, 2022
1 Jan 28, 2022