![]()
StudioGAN is a Pytorch library providing implementations of representative Generative Adversarial Networks (GANs) for conditional/unconditional image generation. StudioGAN aims to offer an identical playground for modern GANs so that machine learning researchers can readily compare and analyze a new idea.
Features
- Extensive GAN implementations for PyTorch
- Comprehensive benchmark of GANs using CIFAR10, Tiny ImageNet, and ImageNet datasets
- Better performance and lower memory consumption than original implementations
- Providing pre-trained models that are fully compatible with up-to-date PyTorch environment
- Support Multi-GPU (DP, DDP, and Multinode DistributedDataParallel), Mixed Precision, Synchronized Batch Normalization, LARS, Tensorboard Visualization, and other analysis methods
Implemented GANs
| Name | Venue | Architecture | G_type* | D_type* | Loss | EMA** |
|---|---|---|---|---|---|---|
| DCGAN | arXiv' 15 | CNN/ResNet*** | N/A | N/A | Vanilla | False |
| LSGAN | ICCV' 17 | CNN/ResNet*** | N/A | N/A | Least Sqaure | False |
| GGAN | arXiv' 17 | CNN/ResNet*** | N/A | N/A | Hinge | False |
| WGAN-WC | ICLR' 17 | ResNet | N/A | N/A | Wasserstein | False |
| WGAN-GP | NIPS' 17 | ResNet | N/A | N/A | Wasserstein | False |
| WGAN-DRA | arXiv' 17 | ResNet | N/A | N/A | Wasserstein | False |
| ACGAN | ICML' 17 | ResNet | cBN | AC | Hinge | False |
| ProjGAN | ICLR' 18 | ResNet | cBN | PD | Hinge | False |
| SNGAN | ICLR' 18 | ResNet | cBN | PD | Hinge | False |
| SAGAN | ICML' 19 | ResNet | cBN | PD | Hinge | False |
| BigGAN | ICLR' 18 | Big ResNet | cBN | PD | Hinge | True |
| BigGAN-Deep | ICLR' 18 | Big ResNet Deep | cBN | PD | Hinge | True |
| CRGAN | ICLR' 20 | Big ResNet | cBN | PD/CL | Hinge | True |
| ICRGAN | arXiv' 20 | Big ResNet | cBN | PD/CL | Hinge | True |
| LOGAN | arXiv' 19 | Big ResNet | cBN | PD | Hinge | True |
| DiffAugGAN | Neurips' 20 | Big ResNet | cBN | PD/CL | Hinge | True |
| ADAGAN | Neurips' 20 | Big ResNet | cBN | PD/CL | Hinge | True |
| ContraGAN | Neurips' 20 | Big ResNet | cBN | CL | Hinge | True |
| FreezeD | CVPRW' 20 | - | - | - | - | - |
*G/D_type indicates the way how we inject label information to the Generator or Discriminator. **EMA means applying an exponential moving average update to the generator. ***Experiments on Tiny ImageNet are conducted using the ResNet architecture instead of CNN.
cBN : conditional Batch Normalization. AC : Auxiliary Classifier. PD : Projection Discriminator. CL : Contrastive Learning.
To be Implemented
| Name | Venue | Architecture | G_type* | D_type* | Loss | EMA** |
|---|---|---|---|---|---|---|
| StyleGAN2 | CVPR' 20 | StyleNet | AdaIN | - | Vanilla | True |
AdaIN : Adaptive Instance Normalization.
Requirements
- Anaconda
- Python >= 3.6
- 6.0.0 <= Pillow <= 7.0.0
- scipy == 1.1.0 (Recommended for fast loading of Inception Network)
- sklearn
- seaborn
- h5py
- tqdm
- torch >= 1.6.0 (Recommended for mixed precision training and knn analysis)
- torchvision >= 0.7.0
- tensorboard
- 5.4.0 <= gcc <= 7.4.0 (Recommended for proper use of adaptive discriminator augmentation module)
- torchlars (need to use LARS optimizer, can install by typing "pip install torchlars" in the command line)
You can install the recommended environment as follows:
conda env create -f environment.yml -n studiogan
With docker, you can use:
docker pull mgkang/studiogan:latest
This is my command to make a container named "studioGAN".
Also, you can use port number 6006 to connect the tensoreboard.
docker run -it --gpus all --shm-size 128g -p 6006:6006 --name studioGAN -v /home/USER:/root/code --workdir /root/code mgkang/studiogan:latest /bin/bash
Quick Start
- Train (
-t) and evaluate (-e) the model defined inCONFIG_PATHusing GPU0
CUDA_VISIBLE_DEVICES=0 python3 src/main.py -t -e -c CONFIG_PATH
- Train (
-t) and evaluate (-e) the model defined inCONFIG_PATHusing GPUs(0, 1, 2, 3)andDataParallel
CUDA_VISIBLE_DEVICES=0,1,2,3 python3 src/main.py -t -e -c CONFIG_PATH
Try python3 src/main.py to see available options.
Via Tensorboard, you can monitor trends of IS, FID, F_beta, Authenticity Accuracies, and the largest singular values:
~ PyTorch-StudioGAN/logs/RUN_NAME>>> tensorboard --logdir=./ --port PORT
Dataset
-
CIFAR10: StudioGAN will automatically download the dataset once you execute
main.py. -
Tiny Imagenet, Imagenet, or a custom dataset:
- download Tiny Imagenet and Imagenet. Prepare your own dataset.
- make the folder structure of the dataset as follows:
┌── docs
├── src
└── data
└── ILSVRC2012 or TINY_ILSVRC2012 or CUSTOM
├── train
│ ├── cls0
│ │ ├── train0.png
│ │ ├── train1.png
│ │ └── ...
│ ├── cls1
│ └── ...
└── valid
├── cls0
│ ├── valid0.png
│ ├── valid1.png
│ └── ...
├── cls1
└── ...
Supported Training Techniques
- DistributedDataParallel (Please refer to Here)
### NODE_0, 4_GPUs, All ports are open to NODE_1 docker run -it --gpus all --shm-size 128g --name studioGAN --network=host -v /home/USER:/root/code --workdir /root/code mgkang/studiogan:latest /bin/bash ~/code>>> export NCCL_SOCKET_IFNAME=^docker0,lo ~/code>>> export MASTER_ADDR=PUBLIC_IP_OF_NODE_0 ~/code>>> export MASTER_PORT=AVAILABLE_PORT_OF_NODE_0 ~/code/PyTorch-StudioGAN>>> CUDA_VISIBLE_DEVICES=0,1,2,3 python3 src/main.py -t -e -DDP -n 2 -nr 0 -c CONFIG_PATH
### NODE_1, 4_GPUs, All ports are open to NODE_0 docker run -it --gpus all --shm-size 128g --name studioGAN --network=host -v /home/USER:/root/code --workdir /root/code mgkang/studiogan:latest /bin/bash ~/code>>> export NCCL_SOCKET_IFNAME=^docker0,lo ~/code>>> export MASTER_ADDR=PUBLIC_IP_OF_NODE_0 ~/code>>> export MASTER_PORT=AVAILABLE_PORT_OF_NODE_0 ~/code/PyTorch-StudioGAN>>> CUDA_VISIBLE_DEVICES=0,1,2,3 python3 src/main.py -t -e -DDP -n 2 -nr 1 -c CONFIG_PATH
※ StudioGAN does not support DDP training for ContraGAN. This is because conducting contrastive learning requires a 'gather' operation to calculate the exact conditional contrastive loss.
- Mixed Precision Training (Narang et al.)
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -t -mpc -c CONFIG_PATH
- Standing Statistics (Brock et al.)
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -e -std_stat --standing_step STANDING_STEP -c CONFIG_PATH
- Synchronized BatchNorm
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -t -sync_bn -c CONFIG_PATH
- Load All Data in Main Memory
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -t -l -c CONFIG_PATH
- LARS
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -t -l -c CONFIG_PATH -LARS
To Visualize and Analyze Generated Images
The StudioGAN supports Image visualization, K-nearest neighbor analysis, Linear interpolation, and Frequency analysis. All results will be saved in ./figures/RUN_NAME/*.png.
- Image Visualization
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -iv -std_stat --standing_step STANDING_STEP -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --log_output_path LOG_OUTPUT_PATH

- K-Nearest Neighbor Analysis (we have fixed K=7, the images in the first column are generated images.)
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -knn -std_stat --standing_step STANDING_STEP -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --log_output_path LOG_OUTPUT_PATH

- Linear Interpolation (applicable only to conditional Big ResNet models)
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -itp -std_stat --standing_step STANDING_STEP -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --log_output_path LOG_OUTPUT_PATH

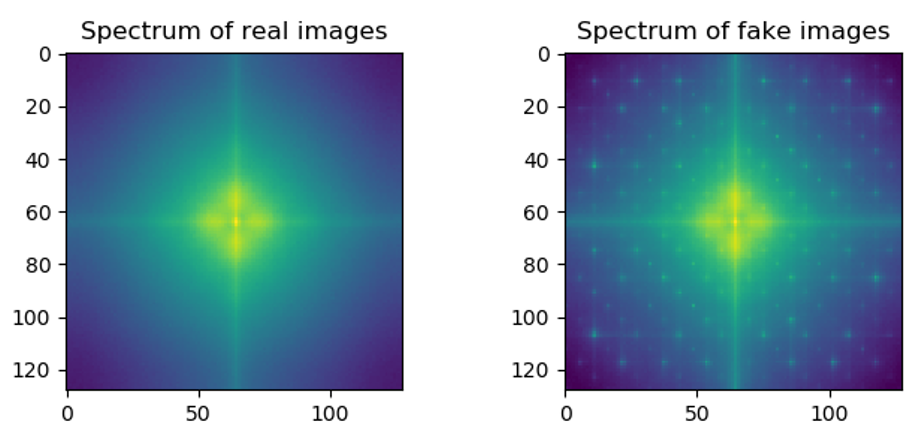
- Frequency Analysis
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -fa -std_stat --standing_step STANDING_STEP -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --log_output_path LOG_OUTPUT_PATH
- TSNE Analysis
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -tsne -std_stat --standing_step STANDING_STEP -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --log_output_path LOG_OUTPUT_PATH

Metrics
Inception Score (IS)
Inception Score (IS) is a metric to measure how much GAN generates high-fidelity and diverse images. Calculating IS requires the pre-trained Inception-V3 network, and recent approaches utilize OpenAI's TensorFlow implementation.
To compute official IS, you have to make a "samples.npz" file using the command below:
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -s -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --log_output_path LOG_OUTPUT_PATH
It will automatically create the samples.npz file in the path ./samples/RUN_NAME/fake/npz/samples.npz. After that, execute TensorFlow official IS implementation. Note that we do not split a dataset into ten folds to calculate IS ten times. We use the entire dataset to compute IS only once, which is the evaluation strategy used in the CompareGAN repository.
CUDA_VISIBLE_DEVICES=0,...,N python3 src/inception_tf13.py --run_name RUN_NAME --type "fake"
Keep in mind that you need to have TensorFlow 1.3 or earlier version installed!
Note that StudioGAN logs Pytorch-based IS during the training.
Frechet Inception Distance (FID)
FID is a widely used metric to evaluate the performance of a GAN model. Calculating FID requires the pre-trained Inception-V3 network, and modern approaches use Tensorflow-based FID. StudioGAN utilizes the PyTorch-based FID to test GAN models in the same PyTorch environment. We show that the PyTorch based FID implementation provides almost the same results with the TensorFlow implementation (See Appendix F of our paper).
Precision and Recall (PR)
Precision measures how accurately the generator can learn the target distribution. Recall measures how completely the generator covers the target distribution. Like IS and FID, calculating Precision and Recall requires the pre-trained Inception-V3 model. StudioGAN uses the same hyperparameter settings with the original Precision and Recall implementation, and StudioGAN calculates the F-beta score suggested by Sajjadi et al.
Benchmark
※ We always welcome your contribution if you find any wrong implementation, bug, and misreported score.
We report the best IS, FID, and F_beta values of various GANs. B. S. means batch size for training.
CR, ICR, DiffAug, ADA, and LO refer to regularization or optimization techiniques: CR (Consistency Regularization), ICR (Improved Consistency Regularization), DiffAug (Differentiable Augmentation), ADA (Adaptive Discriminator Augmentation), and LO (Latent Optimization), respectively.
CIFAR10 (3x32x32)
When training, we used the command below.
CUDA_VISIBLE_DEVICES=0 python3 src/main.py -t -e -l -stat_otf -c CONFIG_PATH --eval_type "test"
With a single TITAN RTX GPU, training BigGAN takes about 13-15 hours.
| Name | B. S. | IS(⭡) | FID(⭣) | F_1/8(⭡) | F_8(⭡) | Config | Log | Weights |
|---|---|---|---|---|---|---|---|---|
| DCGAN | 64 | 6.638 | 49.030 | 0.833 | 0.795 | Config | Log | Link |
| LSGAN | 64 | 5.577 | 66.686 | 0.757 | 0.720 | Config | Log | Link |
| GGAN | 64 | 6.227 | 42.714 | 0.916 | 0.822 | Config | Log | Link |
| WGAN-WC | 64 | 2.579 | 159.090 | 0.190 | 0.199 | Config | Log | Link |
| WGAN-GP | 64 | 7.458 | 25.852 | 0.962 | 0.929 | Config | Log | Link |
| WGAN-DRA | 64 | 6.432 | 41.586 | 0.922 | 0.863 | Config | Log | Link |
| ACGAN | 64 | 6.629 | 45.571 | 0.857 | 0.847 | Config | Log | Link |
| ProjGAN | 64 | 7.539 | 33.830 | 0.952 | 0.855 | Config | Log | Link |
| SNGAN | 64 | 8.677 | 13.248 | 0.983 | 0.978 | Config | Log | Link |
| SAGAN | 64 | 8.680 | 14.009 | 0.982 | 0.970 | Config | Log | Link |
| BigGAN | 64 | 9.746 | 8.034 | 0.995 | 0.994 | Config | Log | Link |
| BigGAN + CR | 64 | 10.380 | 7.178 | 0.994 | 0.993 | Config | Log | Link |
| BigGAN + ICR | 64 | 10.153 | 7.430 | 0.994 | 0.993 | Config | Log | Link |
| BigGAN + DiffAug | 64 | 9.775 | 7.157 | 0.996 | 0.993 | Config | Log | Link |
| BigGAN + ADA | 64 | 10.136 | 7.881 | 0.993 | 0.994 | Config | Log | Link |
| BigGAN + LO | 64 | 9.701 | 8.369 | 0.992 | 0.989 | Config | Log | Link |
| ContraGAN | 64 | 9.729 | 8.065 | 0.993 | 0.992 | Config | Log | Link |
| ContraGAN + CR | 64 | 9.812 | 7.685 | 0.995 | 0.993 | Config | Log | Link |
| ContraGAN + ICR | 64 | 10.117 | 7.547 | 0.996 | 0.993 | Config | Log | Link |
| ContraGAN + DiffAug | 64 | 9.996 | 7.193 | 0.995 | 0.990 | Config | Log | Link |
| ContraGAN + ADA | 64 | 9.411 | 10.830 | 0.990 | 0.964 | Config | Log | Link |
※ IS, FID, and F_beta values are computed using 10K test and 10K generated Images.
※ When evaluating, the statistics of batch normalization layers are calculated on the fly (statistics of a batch).
CUDA_VISIBLE_DEVICES=0 python3 src/main.py -e -l -stat_otf -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --eval_type "test"
Tiny ImageNet (3x64x64)
When training, we used the command below.
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -t -e -l -stat_otf -c CONFIG_PATH --eval_type "valid"
With 4 TITAN RTX GPUs, training BigGAN takes about 2 days.
| Name | B. S. | IS(⭡) | FID(⭣) | F_1/8(⭡) | F_8(⭡) | Config | Log | Weights |
|---|---|---|---|---|---|---|---|---|
| DCGAN | 256 | 5.640 | 91.625 | 0.606 | 0.391 | Config | Log | Link |
| LSGAN | 256 | 5.381 | 90.008 | 0.638 | 0.390 | Config | Log | Link |
| GGAN | 256 | 5.146 | 102.094 | 0.503 | 0.307 | Config | Log | Link |
| WGAN-WC | 256 | 9.696 | 41.454 | 0.940 | 0.735 | Config | Log | Link |
| WGAN-GP | 256 | 1.322 | 311.805 | 0.016 | 0.000 | Config | Log | Link |
| WGAN-DRA | 256 | 9.564 | 40.655 | 0.938 | 0.724 | Config | Log | Link |
| ACGAN | 256 | 6.342 | 78.513 | 0.668 | 0.518 | Config | Log | Link |
| ProjGAN | 256 | 6.224 | 89.175 | 0.626 | 0.428 | Config | Log | Link |
| SNGAN | 256 | 8.412 | 53.590 | 0.900 | 0.703 | Config | Log | Link |
| SAGAN | 256 | 8.342 | 51.414 | 0.898 | 0.698 | Config | Log | Link |
| BigGAN | 1024 | 11.998 | 31.920 | 0.956 | 0.879 | Config | Log | Link |
| BigGAN + CR | 1024 | 14.887 | 21.488 | 0.969 | 0.936 | Config | Log | Link |
| BigGAN + ICR | 1024 | 5.605 | 91.326 | 0.525 | 0.399 | Config | Log | Link |
| BigGAN + DiffAug | 1024 | 17.075 | 16.338 | 0.979 | 0.971 | Config | Log | Link |
| BigGAN + ADA | 1024 | 15.158 | 24.121 | 0.953 | 0.942 | Config | Log | Link |
| BigGAN + LO | 256 | 6.964 | 70.660 | 0.857 | 0.621 | Config | Log | Link |
| ContraGAN | 1024 | 13.494 | 27.027 | 0.975 | 0.902 | Config | Log | Link |
| ContraGAN + CR | 1024 | 15.623 | 19.716 | 0.983 | 0.941 | Config | Log | Link |
| ContraGAN + ICR | 1024 | 15.830 | 21.940 | 0.980 | 0.944 | Config | Log | Link |
| ContraGAN + DiffAug | 1024 | 17.303 | 15.755 | 0.984 | 0.962 | Config | Log | Link |
| ContraGAN + ADA | 1024 | 8.398 | 55.025 | 0.878 | 0.677 | Config | Log | Link |
※ IS, FID, and F_beta values are computed using 50K validation and 50K generated Images.
※ When evaluating, the statistics of batch normalization layers are calculated on the fly (statistics of a batch).
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -e -l -stat_otf -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --eval_type "valid"
ImageNet (3x128x128)
When training, we used the command below.
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -t -e -l -sync_bn -stat_otf -c CONFIG_PATH --eval_type "valid"
With 8 TESLA V100 GPUs, training BigGAN2048 takes about a month.
| Name | B. S. | IS(⭡) | FID(⭣) | F_1/8(⭡) | F_8(⭡) | Config | Log | Weights |
|---|---|---|---|---|---|---|---|---|
| SNGAN | 256 | 32.247 | 26.792 | 0.938 | 0.913 | Config | Log | Link |
| SAGAN | 256 | 29.848 | 34.726 | 0.849 | 0.914 | Config | Log | Link |
| BigGAN | 256 | 28.633 | 24.684 | 0.941 | 0.921 | Config | Log | Link |
| BigGAN | 2048 | 99.705 | 7.893 | 0.985 | 0.989 | Config | Log | Link |
| ContraGAN | 256 | 25.249 | 25.161 | 0.947 | 0.855 | Config | Log | Link |
※ IS, FID, and F_beta values are computed using 50K validation and 50K generated Images.
※ When evaluating, the statistics of batch normalization layers are calculated in advance (moving average of the previous statistics).
CUDA_VISIBLE_DEVICES=0,...,N python3 src/main.py -e -l -sync_bn -c CONFIG_PATH --checkpoint_folder CHECKPOINT_FOLDER --eval_type "valid"
References
[1] Exponential Moving Average: https://github.com/ajbrock/BigGAN-PyTorch
[2] Synchronized BatchNorm: https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
[3] Self-Attention module: https://github.com/voletiv/self-attention-GAN-pytorch
[4] Implementation Details: https://github.com/ajbrock/BigGAN-PyTorch
[5] Architecture Details: https://github.com/google/compare_gan
[6] DiffAugment: https://github.com/mit-han-lab/data-efficient-gans
[7] Adaptive Discriminator Augmentation: https://github.com/rosinality/stylegan2-pytorch
[8] Tensorflow IS: https://github.com/openai/improved-gan
[9] Tensorflow FID: https://github.com/bioinf-jku/TTUR
[10] Pytorch FID: https://github.com/mseitzer/pytorch-fid
[11] Tensorflow Precision and Recall: https://github.com/msmsajjadi/precision-recall-distributions
[12] torchlars: https://github.com/kakaobrain/torchlars
Citation
StudioGAN is established for the following research project. Please cite our work if you use StudioGAN.
@inproceedings{kang2020ContraGAN,
title = {{ContraGAN: Contrastive Learning for Conditional Image Generation}},
author = {Minguk Kang and Jaesik Park},
journal = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2020}
}



















 4 Aug 28, 2022
4 Aug 28, 2022
 13.4k Jan 8, 2023
13.4k Jan 8, 2023
 383 Dec 17, 2022
383 Dec 17, 2022
 2 Nov 5, 2021
2 Nov 5, 2021
 141 Dec 30, 2022
141 Dec 30, 2022
 31 Sep 27, 2022
31 Sep 27, 2022
 7 Dec 27, 2022
7 Dec 27, 2022
 7 Jan 3, 2023
7 Jan 3, 2023
 41 Apr 28, 2022
41 Apr 28, 2022
 6k Dec 27, 2022
6k Dec 27, 2022
 33 Dec 6, 2022
33 Dec 6, 2022
 809 Dec 16, 2022
809 Dec 16, 2022
 76 Nov 9, 2022
76 Nov 9, 2022
 86 Oct 5, 2022
86 Oct 5, 2022
 36 Dec 16, 2022
36 Dec 16, 2022
 892 Dec 28, 2022
892 Dec 28, 2022
 373 Jan 2, 2023
373 Jan 2, 2023
 375 Dec 31, 2022
375 Dec 31, 2022
 2.2k Jan 1, 2023
2.2k Jan 1, 2023
{kind=link}