gensim – Topic Modelling in Python




Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Target audience is the natural language processing (NLP) and information retrieval (IR) community.
Features
- All algorithms are memory-independent w.r.t. the corpus size (can process input larger than RAM, streamed, out-of-core),
- Intuitive interfaces
- easy to plug in your own input corpus/datastream (trivial streaming API)
- easy to extend with other Vector Space algorithms (trivial transformation API)
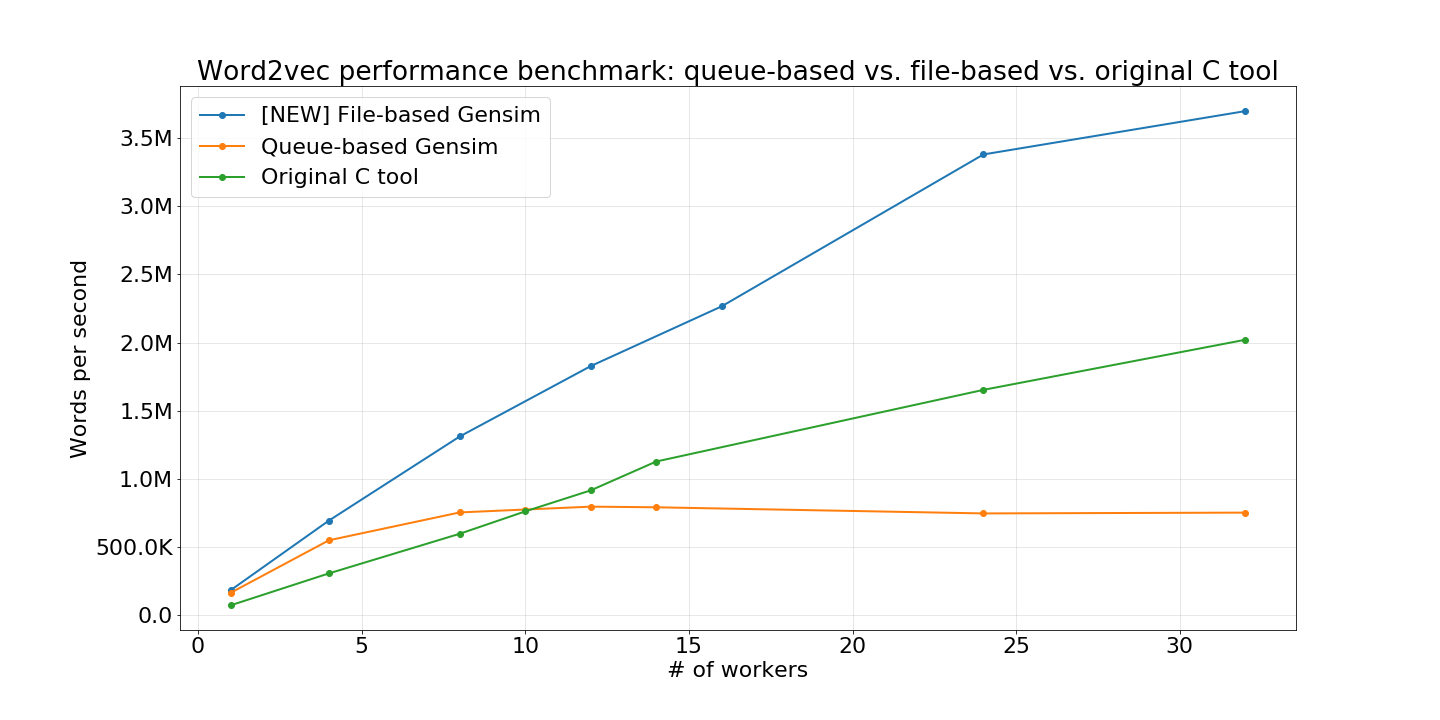
- Efficient multicore implementations of popular algorithms, such as online Latent Semantic Analysis (LSA/LSI/SVD), Latent Dirichlet Allocation (LDA), Random Projections (RP), Hierarchical Dirichlet Process (HDP) or word2vec deep learning.
- Distributed computing: can run Latent Semantic Analysis and Latent Dirichlet Allocation on a cluster of computers.
- Extensive documentation and Jupyter Notebook tutorials.
If this feature list left you scratching your head, you can first read more about the Vector Space Model and unsupervised document analysis on Wikipedia.
Installation
This software depends on NumPy and Scipy, two Python packages for scientific computing. You must have them installed prior to installing gensim.
It is also recommended you install a fast BLAS library before installing NumPy. This is optional, but using an optimized BLAS such as ATLAS or OpenBLAS is known to improve performance by as much as an order of magnitude. On OS X, NumPy picks up the BLAS that comes with it automatically, so you don’t need to do anything special.
Install the latest version of gensim:
pip install --upgrade gensim
Or, if you have instead downloaded and unzipped the source tar.gz package:
python setup.py install
For alternative modes of installation, see the documentation.
Gensim is being continuously tested under Python 3.6, 3.7 and 3.8. Support for Python 2.7 was dropped in gensim 4.0.0 – install gensim 3.8.3 if you must use Python 2.7.
How come gensim is so fast and memory efficient? Isn’t it pure Python, and isn’t Python slow and greedy?
Many scientific algorithms can be expressed in terms of large matrix operations (see the BLAS note above). Gensim taps into these low-level BLAS libraries, by means of its dependency on NumPy. So while gensim-the-top-level-code is pure Python, it actually executes highly optimized Fortran/C under the hood, including multithreading (if your BLAS is so configured).
Memory-wise, gensim makes heavy use of Python’s built-in generators and iterators for streamed data processing. Memory efficiency was one of gensim’s design goals, and is a central feature of gensim, rather than something bolted on as an afterthought.
Documentation
Support
Ask open-ended or research questions on the Gensim Mailing List.
Raise bugs on Github but make sure you follow the issue template. Issues that are not bugs or fail to follow the issue template will be closed without inspection.
Adopters
| Company | Logo | Industry | Use of Gensim |
|---|---|---|---|
| RARE Technologies |  |
ML & NLP consulting | Creators of Gensim – this is us! |
| Amazon |  |
Retail | Document similarity. |
| National Institutes of Health |  |
Health | Processing grants and publications with word2vec. |
| Cisco Security |  |
Security | Large-scale fraud detection. |
| Mindseye |  |
Legal | Similarities in legal documents. |
| Channel 4 |  |
Media | Recommendation engine. |
| Talentpair |  |
HR | Candidate matching in high-touch recruiting. |
| Juju |  |
HR | Provide non-obvious related job suggestions. |
| Tailwind |  |
Media | Post interesting and relevant content to Pinterest. |
| Issuu |  |
Media | Gensim's LDA module lies at the very core of the analysis we perform on each uploaded publication to figure out what it's all about. |
| Search Metrics |  |
Content Marketing | Gensim word2vec used for entity disambiguation in Search Engine Optimisation. |
| 12K Research |  |
Media | Document similarity analysis on media articles. |
| Stillwater Supercomputing |  |
Hardware | Document comprehension and association with word2vec. |
| SiteGround |  |
Web hosting | An ensemble search engine which uses different embeddings models and similarities, including word2vec, WMD, and LDA. |
| Capital One |  |
Finance | Topic modeling for customer complaints exploration. |
Citing gensim
When citing gensim in academic papers and theses, please use this BibTeX entry:
@inproceedings{rehurek_lrec,
title = {{Software Framework for Topic Modelling with Large Corpora}},
author = {Radim {\v R}eh{\r u}{\v r}ek and Petr Sojka},
booktitle = {{Proceedings of the LREC 2010 Workshop on New
Challenges for NLP Frameworks}},
pages = {45--50},
year = 2010,
month = May,
day = 22,
publisher = {ELRA},
address = {Valletta, Malta},
note={\url{http://is.muni.cz/publication/884893/en}},
language={English}
}


















 93 Dec 1, 2022
93 Dec 1, 2022
 3k Dec 29, 2022
3k Dec 29, 2022
 801 Jan 8, 2023
801 Jan 8, 2023
 112 Oct 23, 2022
112 Oct 23, 2022
 1.8k Jan 5, 2023
1.8k Jan 5, 2023
 17 Aug 8, 2022
17 Aug 8, 2022
 5 Mar 25, 2022
5 Mar 25, 2022
 24 Dec 12, 2022
24 Dec 12, 2022
 22 Dec 8, 2022
22 Dec 8, 2022
 101 Dec 29, 2022
101 Dec 29, 2022
 16 Dec 13, 2022
16 Dec 13, 2022
 1 Jul 9, 2022
1 Jul 9, 2022
 25 Nov 24, 2022
25 Nov 24, 2022
 57k Jan 9, 2023
57k Jan 9, 2023
 662 Nov 20, 2022
662 Nov 20, 2022
 165 Nov 4, 2022
165 Nov 4, 2022
 15 Dec 13, 2021
15 Dec 13, 2021
 59 Dec 14, 2022
59 Dec 14, 2022