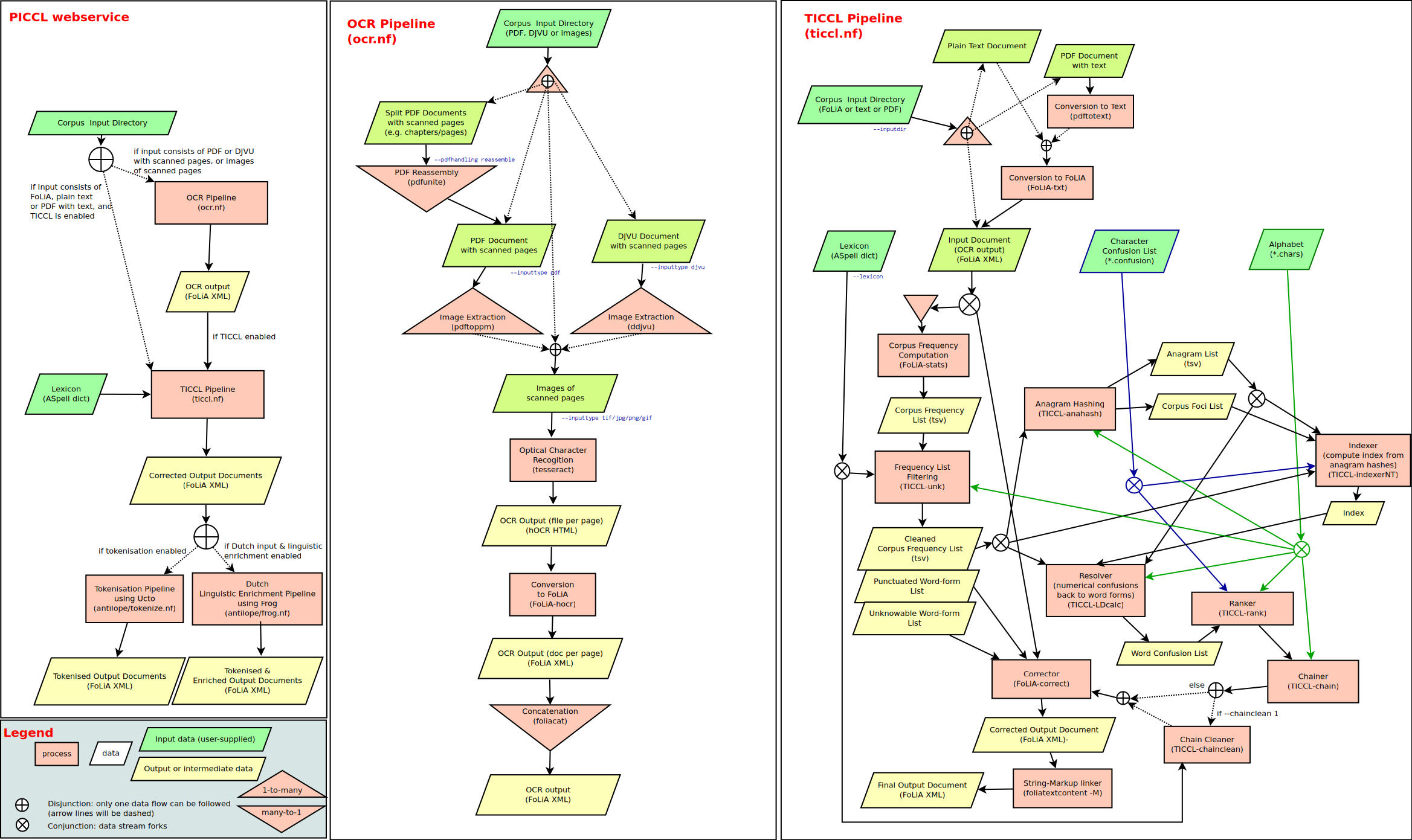
Quick and Dirty OCR of Facebook Papers
Gizmodo has been working through the Facebook Papers and releasing the docs that they process and review.
As luck would have it, I had some ugly but functional code lying around that would do a first pass on OCR on these docs. That code is in the pdf_to_image.py script. I'd welcome improvement to the code, especially in image cleanup prior to OCR (lines 92-97, approx). I experimented with cleaning up the image via PIL and cv2, but the results were less accurate, almost certainly due to my lack of familiarity with either of these approaches.
These Facebook Papers are especially challenging from an OCR perspective because many of them are pictures taken of a screen, so the base image quality isn't especially good. Because of this, not every document can be processed cleanly, and the documents that do get processed have some cruft in them.
With that said, the text pulled from these files simplifies the process of parsing through a large amount of data for keywords.
Other (Better) Options
This OCR should be seen as a first step. Text files are generally a decent starting point because they allow for a wide range of follow on analysis.
And, other/better options exist. For a comprehensive, contained analysis, these other options will almost certainly be a better choice.
Want to help?
If you want to collaborate on this project, let me know!
 763 Jan 1, 2023
763 Jan 1, 2023
 391 Dec 30, 2022
391 Dec 30, 2022

 311 Dec 24, 2022
311 Dec 24, 2022
 496 Jan 5, 2023
496 Jan 5, 2023

 444 Dec 30, 2022
444 Dec 30, 2022
 41 Dec 27, 2022
41 Dec 27, 2022
 99 Nov 1, 2022
99 Nov 1, 2022

 21 Dec 8, 2021
21 Dec 8, 2021
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

 27.5k Jan 8, 2023
27.5k Jan 8, 2023
 363 Jan 3, 2023
363 Jan 3, 2023
 4 Jul 11, 2022
4 Jul 11, 2022
 1 Dec 7, 2021
1 Dec 7, 2021
 5 Dec 6, 2021
5 Dec 6, 2021
 11.4k Jan 2, 2023
11.4k Jan 2, 2023
 43 Mar 15, 2022
43 Mar 15, 2022
 26 Jun 17, 2021
26 Jun 17, 2021
 16.7k Jan 3, 2023
16.7k Jan 3, 2023
 684 Jan 6, 2023
684 Jan 6, 2023