中国基金报 泰勒 吴羽 赵婷
比炒A股惨多了,炒原油亏起来可能要倒贴。
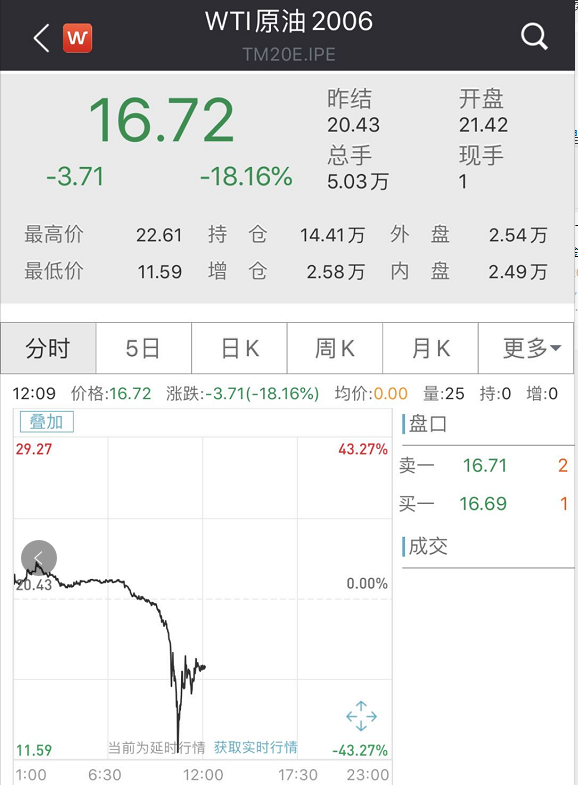
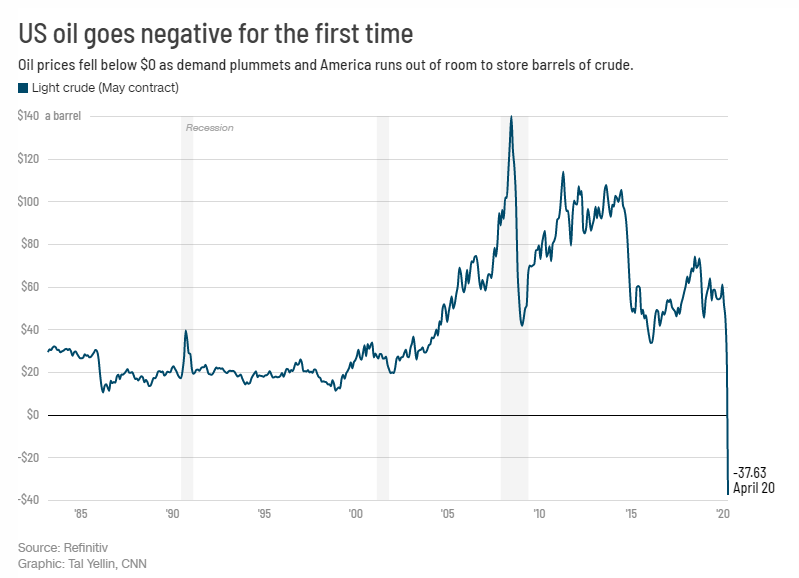
昨夜,WTI原油5月期货合约CME官方结算价收报-37.63美元/桶,历史上首次收于负值。
你以为这就结束了?美油6月期货也崩了!换月到6月的投资者本以为可以逃过一劫,没想到下午又崩了,跌幅一度超过40%…分析称由于6月合约是主力合约,这次大跌会对原油基金将造成实质性重创!
今天早间,中国银行发布消息,暂停原油宝产品美国原油合约4月21日交易,并表示,正积极联络CME,确认结算价格的有效性和相关结算安排。
午间,工商银行公告称,4月23日其账户原油产品将转期,从6月调整为7月。同时提示风险,建议谨慎交易。
业内人士表示,对于持仓WTI原油5月期货合约的投资者来说,不仅仅是亏本金,还有可能倒贴。不过这种历史性的出现负值这只是“末日效应”带来的短期影响,大家无需过度恐慌,对国内的原油价格影响也相对较小。
再次上演崩盘,5月崩完6月崩
美油主力合约一度跌超40%
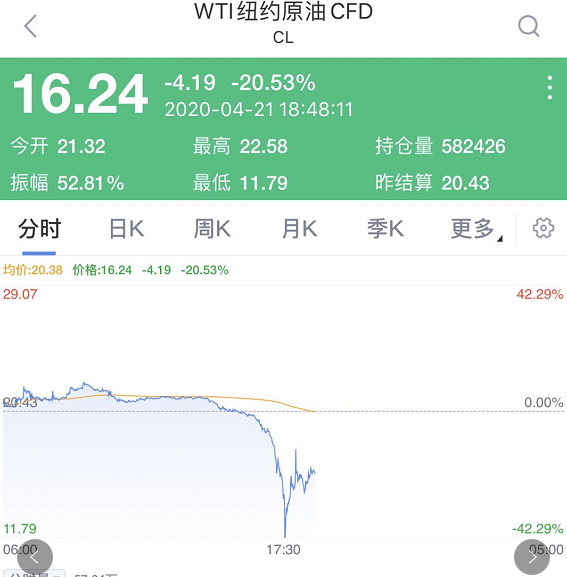
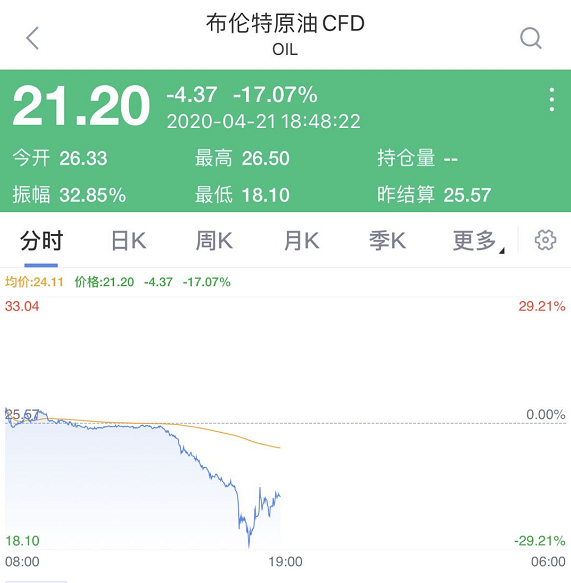
继周一WTI原油5月合约一度跌入负值区间之后,周二WTI原油6月合约和布伦特原油期货也开启了深跌模式,WTI原油6月期货合约一度跌超40%,跌破12美元/桶。布伦特原油期货一度跌破19美元/桶,跌幅超25%。
5月合约收于-37.63美元/桶,但这恐怕还不是最致命的一天,正如瑞穗期货主管Bob Yawger指出,EIA数据并没有显示当前原油库存已经达到最大储能,这次暴跌的主要原因是交易者急于平仓。
也就是说,库容爆满的一刻还没到来,那么这一天将可能在何时降临呢?投资者要尤其关注5月中旬,特别是5月19日6月WTI主力合约到期之时。
据路透社报道,美国能源部下属的战略原油储备基地的储油空间最多能存放约7亿1350万桶原油,目前已储备了约6.4亿桶原油。也就是说,美国的SPR也已经接近极限。
同时,在最引人注目的俄克拉荷马州库欣(Cushing),根据美国能源情报署(EIA)的数据,截至上周,这个全球最大的商业油库约有71%的空间已填满,过去三周内就增加了1800万桶。
华尔街认为,如果到5月19日6月主力合约到期之时,原油市场仍没有太大起色,持有该合约的交易者又将再度面临“高成本移仓”和“实物交割”二选一的困境。也就是说,WTI原油6月合约或将面临与5月合约同样的命运。
中石油、中石化紧急发声
1、中石油党组召开会议:当前的挑战前所未有、低油价使公司大而不强矛盾凸显
4月20日,中石油集团公司党组召开会议。会议指出,当前的挑战前所未有,要充分估计困难、风险和不确定性,切实增强紧迫感,扎实推进提质增效专项行动。低油价使公司大而不强矛盾凸显, “水落石出”,要按照中央要求,不失时机地推进深化改革。会议还提出,要聚焦“两利三率”指标体系,经营上灵活应对,努力把疫情和油价影响控制在最低限度。
2、中石化党组召开会议 :做好较长时间应对外部环境变化的思想准备和工作准备
中石化党组召开会议指出,要完成百日攻坚创效这个硬任务,日跟踪、旬总结、月分析,勤算账、细算账、精算账,紧贴市场,灵活排产,做到应收尽收、应得尽得、颗粒归仓。要练好降本减费这个硬功夫,牢固树立长期过紧日子思想,做好较长时间应对外部环境变化的思想准备和工作准备,采取超常规措施,严控非生产性支出,大幅降低运行成本。
中石油湛江仓储分公司增加原油期货启用库容至50万立方米
上海期货交易所子公司上海国际能源交易中心已于2020年4月21日发布《关于同意中石油燃料油有限责任公司湛江仓储分公司增加原油期货启用库容的公告》(上能公告 [2020] 18 号)。同意中石油燃料油有限责任公司位于广东省湛江市霞山区友谊路1号湛江港二区栈桥南吹填区的原油期货指定交割仓库存放点启用库容由40万立方米增加至50万立方米,核定库容按70万立方米执行。
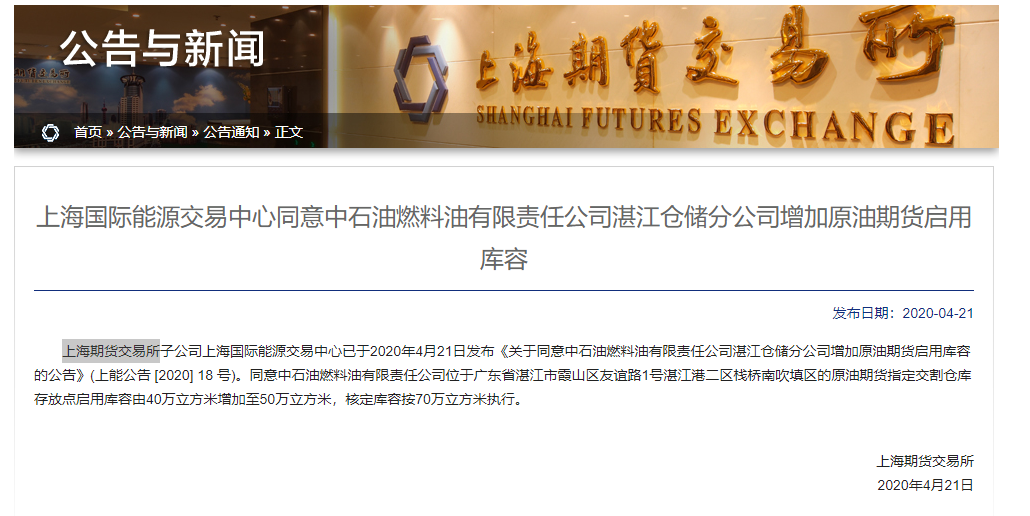
建行:建议投资者充分关注近期原油市场价格波动
合理控制仓位
中国建设银行21日在官网发布“关于近期账户商品业务的市场风险提示”称,受全球新冠肺炎疫情、地缘政治、短期经济冲击等因素综合影响,国际原油市场波动加剧,4月20日原油价格历史首次跌至负值,WTI2005合约最低价报-40.32美元/桶,市场波动风险巨大。同时原油期货升水(远月与近月合约价差)大幅上升,近期WTI2007合约较WTI2006合约升水高达26%,后续可能面临较大的升水波动风险。
建行建议投资者充分关注近期原油市场价格波动风险,合理控制仓位;充分关注近期账户原油同一品种两个不同期次月度合约之间大幅升水的风险,客户换仓或转期时,可能会出现持仓份额(按金额即时换仓或自动转期)显著减少,或保证金占用(按数量即时换仓或自动转期)显著增加等情况。并称“也可以选择先主动平仓,再根据市场情况择机建仓新合约。合理安排单一资产配置比例,并做好相关风险管控措施,理性投资。”
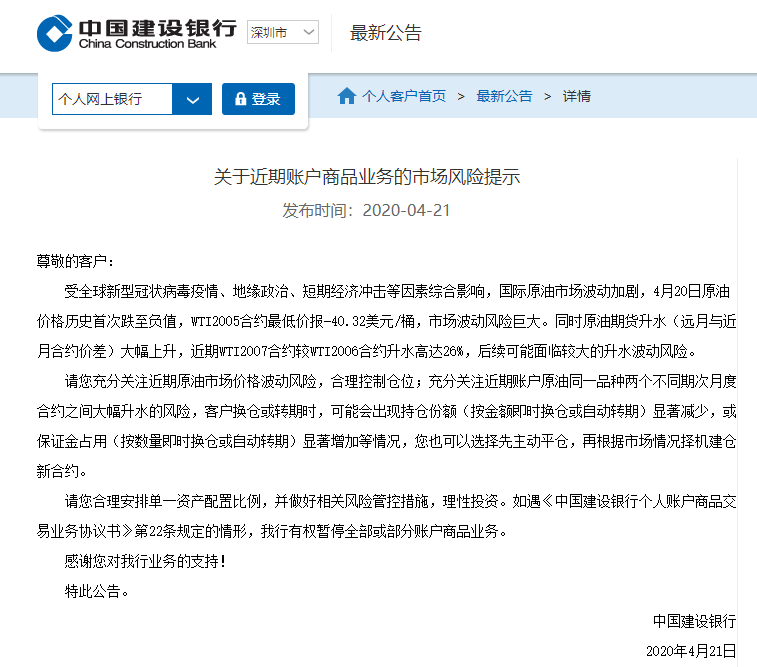
中国银行:
暂停美国原油合约交易
昨夜WTI5月期货合约遭到疯狂抛售,截至凌晨2:30,WTI原油5月期货合约CME官方结算价收报-37.63美元/桶,跌幅305.97%,历史上首次收于负值。
4月21日上午,中国银行发布公告称,我行正积极联络CME,确认结算价格的有效性和相关结算安排。
受此影响,中国银行原油宝产品“美油/美元”、“美油/人民币”两张美国原油合约暂停交易一天,英国原油合约正常交易。
沪上某投资人士对记者表示,历史上从来没出现过价格出现负值的情况,中国银行或要跟芝加哥期货交易所核实,当价格出现负值的时候应怎样核算。
“暂停交易有很多原因,具体什么原因不了解,但猜测主要还是因为5月期货合约这部分要结算,关键就是要算好亏多少钱的问题,中国因为说要和芝加哥交易所联系,也不知道他们怎么做。”某期货研究员对记者表示。
原油宝是中国银行面向个人客户发行的追踪国际原油期货合约的不具备杠杆效应的商品保证金交易业务。产品报价与国际原油期货价格挂钩,对应的基准标的为“欧洲期货交易所(ICE)北海布伦特原油期货合约”和“纽约商品交易所(CME)WTI原油期货合约”。
客户可通过中国银行所提供的报价和交易平台,在事前存入等于开仓货币名义金额的交易保证金后,进行做多或做空双向选择的原油宝交易。原油宝以人民币或美元买卖原油份额,只计份额,不提取实物原油。
由中国银行作为做市商提供报价并进行风险管理。个人客户在中国银行开立相应保证金交易专户,并签订协议,存入足额保证金后,实现做多与做空(卖出)双向选择的原油交易工具。该产品为不具备杠杆效应的保证金交易类产品。该产品还有一个特点是T+0交易,一天可以多空操作多次。
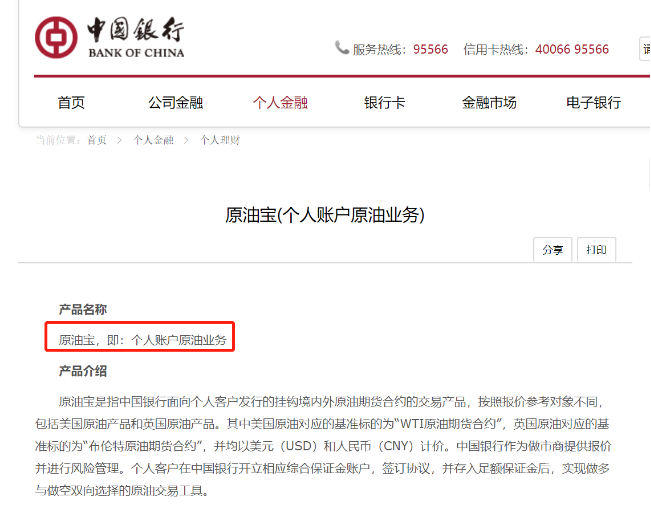
工商银行:
国际原油产品将转期
21日午间,工商银行也发布公告,称4月23日我行账户国际原油产品将转期,当日交易结束后,产品参考的布伦特原油合约将由6月调整为7月。
如您持有期次产品且已设置转期或持有连续产品,我行将依据交易规则重新计算您转期后的持仓份额。
受全球原油市场供应过剩等因素影响,目前新旧合约价差(升水)约4美元(30元人民币)/桶,处于较高水平,调整后您的持仓份额可能减少。近期原油市场波动加剧,请您关注风险,谨慎投资交易。
上述期货研究员表示,工商银行所称的国际原油产品转期不是转的美国的合约,是转的欧洲的原油合约。
持仓肯定亏损
理论上要倒贴
“至于持有原油期货头寸的人,包括期权,基本上就是肯定亏光了,只是说要不要倒贴钱的问题,因为现在的价格已经出现了负值,如果是负值,理论上是要倒贴钱。”上述投资人士称。
也有研究员表示,“目前来看美国合约只是5月份合约的问题,是一个短期的影响,亏损是有的,但后面不是很大的问题。可能很多投资者也已经移仓。”
近期原油价格大幅波动,暴涨暴跌行情也让不少投资者关注到了相关银行交易。
3月下旬以来,国际原油价格一度快速走低。有投资者选择通过银行相关产品进行抄底。对新手来说,这确实是不错的选择。银行账户原油挂钩的是国际市场上的原油期货合约,支持多空双向交易,也就是说既可买涨也可买跌。
但也由此产生了不少问题,多家银行APP因为系统瘫痪等交易问题遭到用户投诉。3月中旬,工商银行北美原油账户一度因为交易购买人数太多、达到了产品相关净额上限而暂停交易,用户无法买入新开仓做多。
4月初,不少投资者转战中国银行原油宝,但app疑似因交易太多发生拥挤,不少投资反馈交易缓慢或无法交易,导致盈利直接被砍掉一半。
“末日效应” 无需过度恐慌
美东时间2:30,WTI 5月原油期货结算收跌55.90美元,跌幅305.97%,报-37.63美元/桶,历史上首次收于负值。WTI 6月原油期货收跌4.60美元,跌幅18.0%,刷新收盘历史低点至20.43美元/桶。
收于负值意味着什么?
CNBC评论称,油价负数意味着将油运送到炼油厂或存储的成本已经超过了石油本身的价值。
从期货交易的原理上讲,WTI原油期货价格暴跌,因交易员被迫平掉多头头寸,以免在没有库容的情况下购入实物原油。
沪上某投资人士表示,虽然原油期货负值“活久见”,但也无需过度惊慌。
其认为,美国原油期货5月份合约已经不是主力合约,6月份或7月份的主力合约,其实没有5月份合约这么极端。
“其实昨天暴跌,是因为‘末日交易’。”该投资人士表示,昨晚是最后一个交易日,如果不完成交割,比如说不把自己手上的多头头寸平掉,就必须要履行实物交割的约定。
可是,现在已经没有仓库了,所有存油的仓库和海上油轮都已经装满了油,没有仓库用来交割,多头必须不惜一切代价把头寸给平掉。
“末日效应才会出现这种情况,不能从宏观角度去认为有多严重,这只是一个技术问题。”该投资人士说。
虽然只是技术问题,但WTI原油5月期货合约暴跌也对A股产生影响。
该投资人士称,因为原油期货事情会让一些衍生品下跌,那可能国外的某些机构流动性不够,需要卖出其他资产来补充头寸,估计今晚对美股和欧股也有负面冲击。
对国内原油价格影响小
南华期货能化分析师顾双飞表示,美原油的大跌还是供需层面的严重失衡导致的,OPEC+的970万桶/天的减产幅度难以缓解二季度原油需求端的减量(或在2000万桶/天以上),这就导致再未来两三个月储罐资源的紧张将为常态。而美国当地的疫情形势依旧相当严峻,下游复工难有起色,我们看到美国当地的成品油(特别是汽油)库存同原油一样来到了历史同期最高水平,而由于美国下游油品消费一直都是以汽油消费作为绝对的大头,汽油消费的萎靡不振对上游原油的去库构成了极大的挑战。而一时半会儿美国页岩油的生产又不能停下来,油井的启停成本很高,导致这样的供需劈叉短期会一直存在,美原油价格压力山大。
顾双飞表示,WTI原油5月交割价本次大幅下跌至0元以下有一定的交割制度的原因,而美国作为全球最大的油品需求国,疫情的影响导致下游消费的崩塌对其储罐资源的冲击是最为严峻的。但我们不能过度解读本次负油价的影响,WTI原油虽然在全球范围内有较大的影响力但总的来说还是美国本土化的定价为主,WTI原油价格的波动对国内原油的影响还是很小的,国内原油锚定的标的还是以布伦特原油为起点衍生定价的中东原油,我们期现交易的油品也同样以中东巴士拉轻油为主。而目前我国的经济生产正在有条不紊的恢复状态,国内的成品油消费已经逐渐恢复到正常水平,而其余化工品的需求可能受国外疫情的影响恢复还尚需时日,但总的来说情况较国外已经好了很多,汽柴油、沥青等油品需求正在大幅回暖。
大家注意了,去加油站加油
还是要付钱的……
中国基金报记者 吴羽
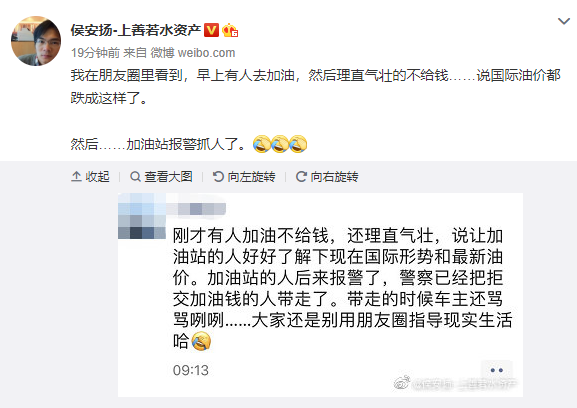
昨晚,美油期货暴跌300%,直接从10美元/桶跌到-37美元/桶,全球人民都跟着一起见证了历史,同时还流出段子:买油倒贴钱还送油桶!
而今天,真的有人误会:以为现在加油不仅免费还倒贴钱……结果……加油站直接报警抓人了。
这里,基金君简单和大家讲2个事:
原油期货暴跌为负,这只是期货,不是现货价格,负数不代表大家以后加油免费还倒贴钱。
我国成品油价格机制设置调控上下限,目前已是地板价,不可能再便宜。
石油期货首次跌到负
当地时间4月20日,美国西得州轻质原油期货5月结算价收于每桶-37.63美元,这是自石油期货从1983年在纽约商品交易所开始交易后首次跌入负数交易。
这意味着将油运送到炼油厂或存储的成本已经超过了石油本身的价值。
加油还是要付钱的
消息出来之后,国内外不少人误会:以后加油免费还倒贴钱?

答案当然是不可能。
国内油价已是地板价
不会再便宜
为啥不可能?
首先来看看国内油价的情况。
2016年1月13日,国家发展改革委发布消息,决定进一步完善成品油价格机制,设置调控上下限。调控上限为每桶130美元,下限为每桶40美元。
3月17日,国际油价已大幅下跌,触发40美元的地板价。国家发改委举行3月份例行新闻发布会,国家发改委价格司副司长、一线巡视员彭绍宗透露,本轮国内成品油价格按照原油价格40美元的水平下调。据机构测算,届时国内大部分地区将回到“5时代”,小型私家车加满一箱油将比之前少花40元左右。
在发布会上,有记者提问,近日国际油价大幅下跌,而今天正好是国内成品油调价窗口期,请问国内油价会怎样调整?会不会触到40美元的调控下限?
彭绍宗指出,按照2016年出台的石油价格管理办法,国内气柴油最高零售价根据国际原油价格变化每十个工作日调整一次。从近十个工作日来看,国际油价大幅下跌,平均水平已跌破每桶40美元调控下限,也就是我们俗称的“地板价”。国内成品油价格将按照机制,从今天(3月17日)24点起大幅下调至对应的原油价格40美元的水平,低于40美元的部分不再下调。
彭绍宗介绍,成品油价格机制设定上下限,上限为每桶130美元,下限为每桶40美元,即当国内成品油价格挂靠的国际市场原油价格高于每桶130美元时,汽、柴油最高零售价格不提或者少提;低于40美元的时候,最高零售价格不再下调。从历史情况看,2016年1-4月份,由于国际原油价格大幅下跌,触及国内成品油价格的调控下限,国内油价按机制在40美元以下的部分未作调整。
截至3月16日收盘,国内第10个工作日参考原油变化率为-26.61%,对应国内汽柴油零售限价每吨分别下调1015及975元,折合成升价,92#汽油及0#柴油每升分别下调0.80及0.83元。本次下调幅度是自2013年新定价机制实施以来最大跌幅。
预计油箱容量在50升的小型私家车加满一箱油将比之前少花40元左右。
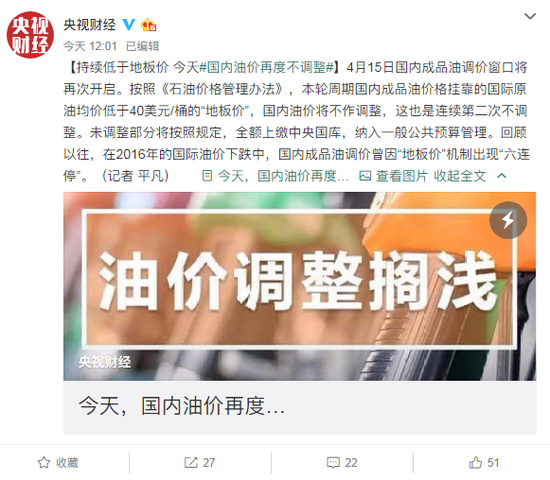
央视财经此前报道,4月15日国内成品油调价窗口将再次开启。按照《石油价格管理办法》,本轮周期国内成品油价格挂靠的国际原油均价低于40美元/桶的“地板价”,国内油价将不作调整,这也是连续第二次不调整。未调整部分将按照规定,全额上缴中央国库,纳入一般公共预算管理。回顾以往,在2016年的国际油价下跌中,国内成品油调价曾因“地板价”机制出现“六连停”。
而今日深圳油价如下:

只是5月原油期货为负
另外,从最本质的问题来看,昨晚是WTI原油期货5月结算价收于每桶-37.63美元。
CNN指出,虽然5月的石油交易价格进入负数,但目前6月交易价格仍处于20美元以上。全球基准布伦特原油交易价格目前也仍以超过25美元的价格交易。
昨晚的原油期货跌幅反应表明原油组织欧佩克、俄罗斯近日刚刚达成的减产协议不足以应对新冠肺炎疫情全球扩散造成的需求骤减,同时美国库存飙升幅度触及纪录高位,进入夏季即将显现的储油设施用尽的难题进一步使市场对近月原油股价失去信心。此外,5月原油期货交割日临近,在期货合约移仓换月时,价格通常会出现跳空现象。
美国能源部的数据显示,仅位于俄克拉何马州库欣(Cushing)的储油罐的储存量目前已达到69%,高于四周前的49%,美国储油设施迅速被填满。在这样的情况下,原油生产商只能通过削减未来数月的采油量并降低近月的原油价格,削减库存,降低生产成本。
油价信息服务部首席石油分析师汤姆•克洛扎(Tom Kloza)表示:“随着期货的到期以及程序交易等的出现,价格可能会波动。” “今天,这个生态系统运转异常。”
原油并不是汽油零售价格的最佳预测指标。相反,批发汽油价格决定了哪些加油站将为汽油付款。周一,汽油期货没有同样的波动,收盘仅下跌了几美分,至每加仑67美分。而这几乎是上周交易价格的两倍。
全美便利商店协会发言人杰夫·列纳德说:“批发汽油期货和石油期货肯定是联系在一起的,但它们不一定在任何一天都能相互反映。”
甚至批发汽油期货也无法完全确定加油站为产品支付的价格。大多数合同都有确定价格的合同,尽管将来的价格已计入其中。
一旦将批发汽油的成本计算在内,所有其他成本都将计入加油支付的价格。
美国能源信息署(US Energy Information Administration)估计,2019年全年平均价格为每加仑2.60美元,每加仑汽油的平均运输和营销成本约为39美分。炼油成本和利润平均增加了34美分。
然后是汽油税。美国加汽油是要征税的,州与州之间的税收差异很大,从阿拉斯加的每加仑约14美分到加利福尼亚的每加仑约60美分。但平均而言,全国一加仑汽油的平均税增至约54美分。
加油不给钱
可能触犯刑法
据悉,“加霸王油”不仅是违法行为,情节严重还有可能触犯刑法构成犯。
在法律上构成抢夺罪。未付钱占有油,直接故意并以非法占有公私财物为目的。
《刑法》第二百六十七条 【抢夺罪】抢夺公私财物,数额较大的,或者多次抢夺的,处三年以下有期徒刑、拘役或者管制,并处或者单处罚金;数额巨大或者有其他严重情节的,处三年以上十年以下有期徒刑,并处罚金;数额特别巨大或者有其他特别严重情节的,处十年以上有期徒刑或者无期徒刑,并处罚金或者没收财产。
抢夺数额较大的公私财物是构成抢夺罪的必要要件。最高人民法院2002年7月20日起施行的《关于审理抢夺刑事案件具体应用法律若干问题的解释》第1条规定:“抢夺公私财物‘数额较大’、‘数额巨大’、‘数额特别巨大’的标准如下:
(一)抢夺公私财物价值人民币500元至2000元以上的,为‘数额较大’;
(二)抢夺公私财物价值人民币5000元至2万元以上的,为‘数额巨大’;
(三)抢夺公私财物价值人民币3万元至10万元以上的,为‘数额特别巨大’。”
各省、自治区、直辖市高级人民法院可以根据本地区经济发展状况,并考虑社会治安状况,在解释第1条规定的数额幅度内,分别确定本地区执行的具体标准,并报最高人民法院备案。
所以,无论是国内还是国外的小伙伴们,加油记得还是要给钱的……

















 12.3k Jan 1, 2023
12.3k Jan 1, 2023
 49 Dec 20, 2022
49 Dec 20, 2022
 1k Dec 31, 2022
1k Dec 31, 2022
 1 Nov 22, 2021
1 Nov 22, 2021
 62 Dec 28, 2022
62 Dec 28, 2022
 135 Dec 31, 2022
135 Dec 31, 2022
 68 Nov 9, 2022
68 Nov 9, 2022
 12 Jan 6, 2023
12 Jan 6, 2023
 10 May 13, 2022
10 May 13, 2022
 3 May 6, 2022
3 May 6, 2022
 270 Jan 4, 2023
270 Jan 4, 2023
 377 Jan 3, 2023
377 Jan 3, 2023
 25 Nov 1, 2022
25 Nov 1, 2022
 54 Dec 13, 2022
54 Dec 13, 2022
 82 Dec 9, 2022
82 Dec 9, 2022
 37 Dec 24, 2022
37 Dec 24, 2022
 6 Sep 25, 2021
6 Sep 25, 2021
 11 Jan 7, 2022
11 Jan 7, 2022
 5 Jul 26, 2022
5 Jul 26, 2022
 1 Nov 22, 2021
1 Nov 22, 2021