Multimodal Deep Learning
Models
Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis
This repository contains the official implementation code of the paper Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis, accepted to EMNLP 2021.
Introduction
Multimodal-informax (MMIM) synthesizes fusion results from multi-modality input through a two-level mutual information (MI) maximization. We use BA (Barber-Agakov) lower bound and contrastive predictive coding as the target function to be maximized. To facilitate the computation, we design an entropy estimation module with associated history data memory to facilitate the computation of BA lower bound and the training process.

Usage
-
Download the CMU-MOSI and CMU-MOSEI dataset from Google Drive or Baidu Disk. Please them under the folder
Multimodal-Infomax/datasets -
Set up the environment (need conda prerequisite)
conda env create -f environment.yml
conda activate MMIM
- Start training
python main.py --dataset mosi --contrast
Citation
Please cite our paper if you find our work useful for your research:
@article{han2021improving,
title={Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis},
author={Han, Wei and Chen, Hui and Poria, Soujanya},
journal={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
year={2021}
}
Contact
Should you have any question, feel free to contact me through [email protected]
MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis
Code for the ACM MM 2020 paper MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis

Setup the environment
We work with a conda environment.
conda env create -f environment.yml
conda activate misa-code
Data Download
- Install CMU Multimodal SDK. Ensure, you can perform
from mmsdk import mmdatasdk. - Option 1: Download pre-computed splits and place the contents inside
datasetsfolder. - Option 2: Re-create splits by downloading data from MMSDK. For this, simply run the code as detailed next.
Running the code
cd src- Set
word_emb_pathinconfig.pyto glove file. - Set
sdk_dirto the path of CMU-MultimodalSDK. python train.py --data mosi. Replacemosiwithmoseiorur_funnyfor other datasets.
Citation
If this paper is useful for your research, please cite us at:
@article{hazarika2020misa,
title={MISA: Modality-Invariant and-Specific Representations for Multimodal Sentiment Analysis},
author={Hazarika, Devamanyu and Zimmermann, Roger and Poria, Soujanya},
journal={arXiv preprint arXiv:2005.03545},
year={2020}
}
Contact
For any questions, please email at [email protected]
Bi-Bimodal Modality Fusion for Correlation-Controlled Multimodal Sentiment Analysis
This repository contains official implementation of the paper: Bi-Bimodal Modality Fusion for Correlation-Controlled Multimodal Sentiment Analysis (ICMI 2021)
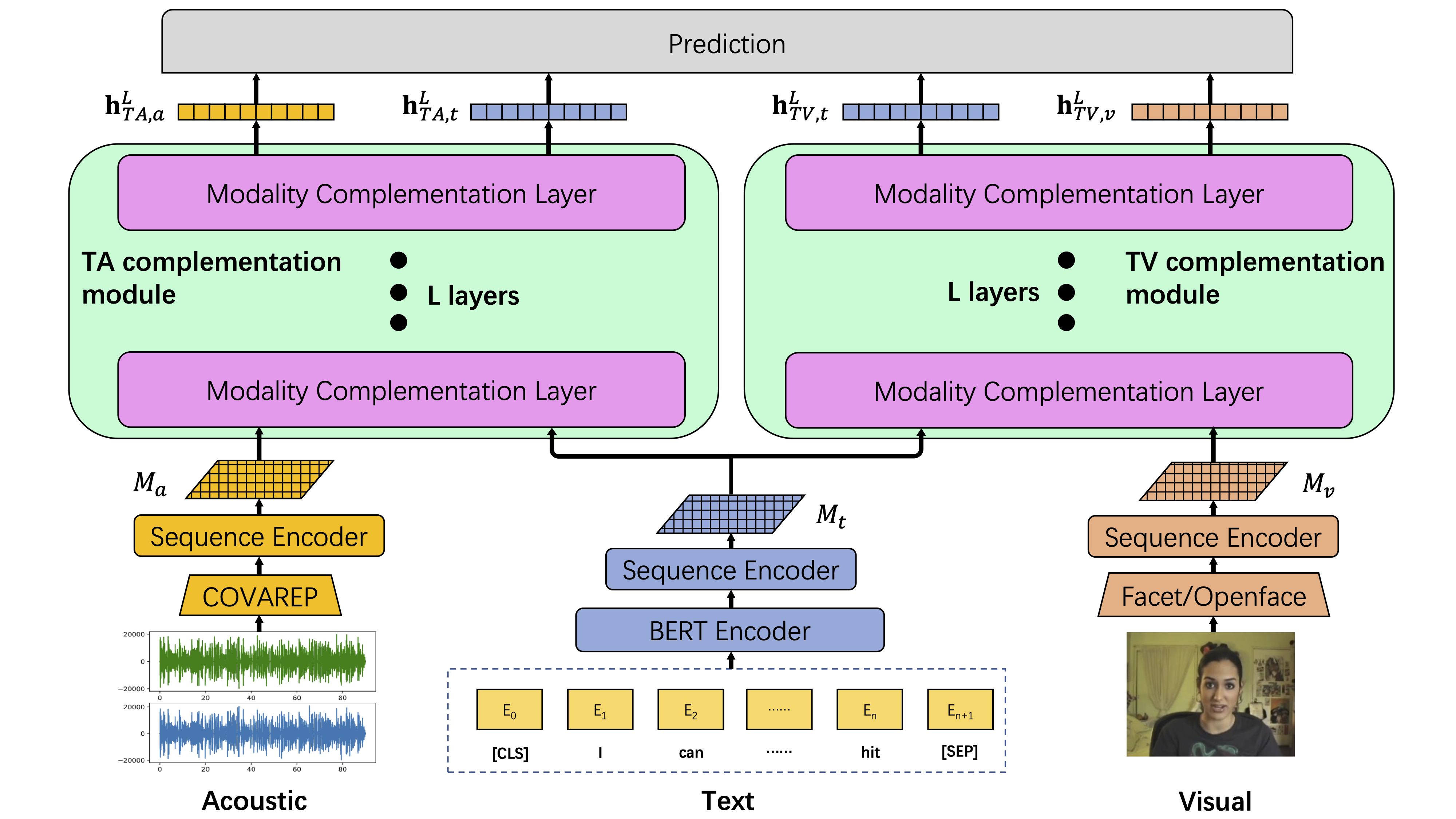
Model Architecture
Overview of our Bi-Bimodal Fusion Network (BBFN). It learns two text-related pairs of representations, text-acoustic and text-visual by enforcing each pair of modalities to complement mutually. Finally, the four (two pairs) head representations are concatenated to generate the final prediction.
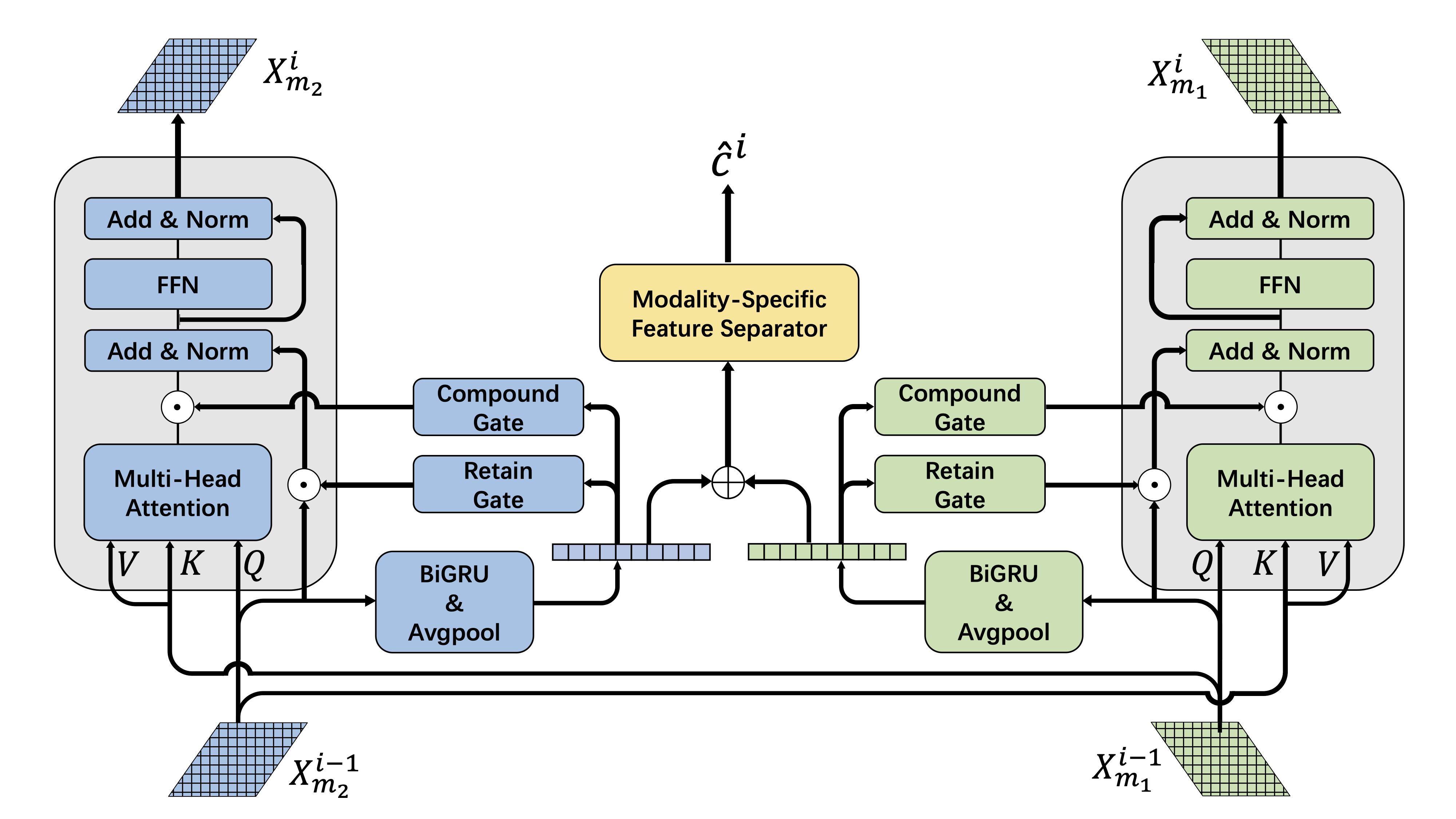
A single complementation layer: two identical pipelines (left and right) propagate the main modality and fuse that with complementary modality with regularization and gated control.
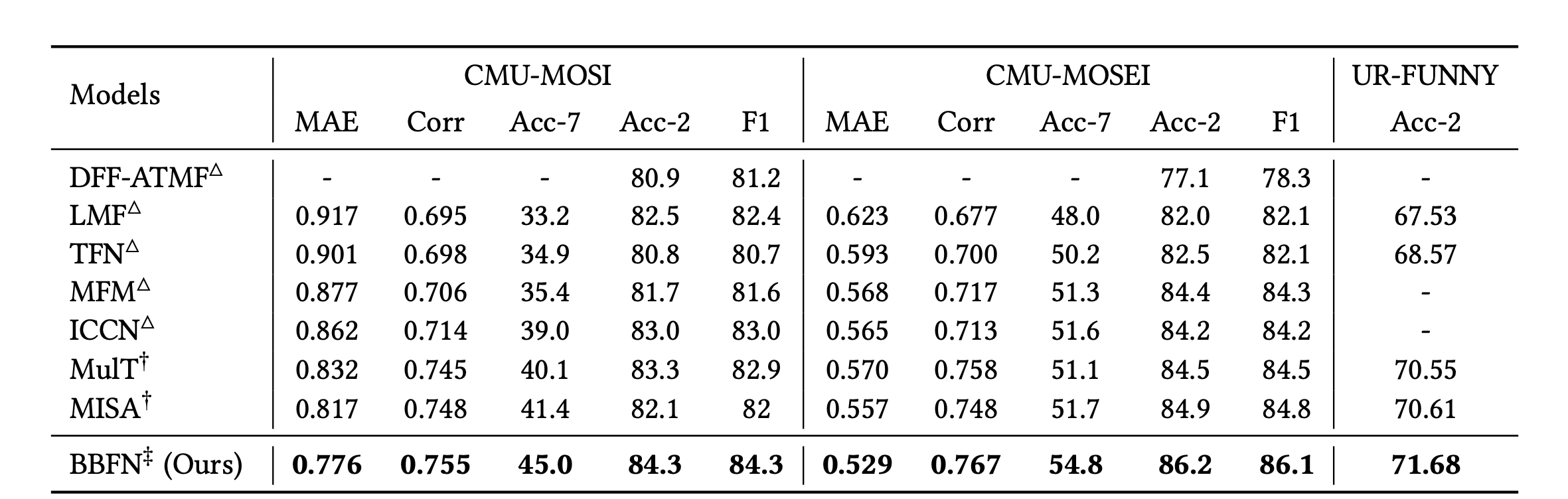
Results
Results on the test set of CMU-MOSI and CMU-MOSEI dataset. Notation: △ indicates results in the corresponding line are excerpted from previous papers; † means the results are reproduced with publicly visible source code and applicable hyperparameter setting; ‡ shows the results have experienced paired t-test with 𝑝 < 0.05 and demonstrate significant improvement over MISA, the state-of-the-art model.
Usage
- Set up conda environemnt
conda env create -f environment.yml
conda activate BBFN
-
Install CMU Multimodal SDK
-
Set
sdk_dirinsrc/config.pyto the path of CMU-MultimodalSDK -
Train the model
cd src
python main.py --dataset --data_path
We provide a script scripts/run.sh for your reference.
Citation
Please cite our paper if you find our work useful for your research:
@article{han2021bi,
title={Bi-Bimodal Modality Fusion for Correlation-Controlled Multimodal Sentiment Analysis},
author={Han, Wei and Chen, Hui and Gelbukh, Alexander and Zadeh, Amir and Morency, Louis-philippe and Poria, Soujanya},
journal={ICMI 2021},
year={2021}
}
Contact
Should you have any question, feel free to contact me through [email protected]
Hfusion
Codes for the paper Multimodal sentiment analysis using hierarchical fusion with context modeling
How to run
python3 hfusion.py
Requirements
Keras >= 2.0, Tensorflow >= 1.7, Numpy, Scikit-learn
Citation
Majumder, N., Hazarika, D., Gelbukh, A., Cambria, E. and Poria, S., 2018. Multimodal sentiment analysis using hierarchical fusion with context modeling. Knowledge-Based Systems, 161, pp.124-133.
Attention-based multimodal fusion for sentiment analysis
Attention-based multimodal fusion for sentiment analysis
Code for the paper
Context-Dependent Sentiment Analysis in User-Generated Videos (ACL 2017).
Multi-level Multiple Attentions for Contextual Multimodal Sentiment Analysis(ICDM 2017).
")
Preprocessing
Edit: the create_data.py is obsolete. The pre-processed datasets have already been provided in the dataset/ folder in the repo. Use them directly.
As data is typically present in utterance format, we combine all the utterances belonging to a video using the following code
python create_data.py
Note: This will create speaker independent train and test splits In dataset/mosei, extract the zip into a folder named 'raw'. Also, extract 'unimodal_mosei_3way.pickle.zip'
Running the model
Sample command:
With attention-based fusion:
python run.py --unimodal True --fusion True
python run.py --unimodal False --fusion True
Without attention-based and with concatenation-based fusion:
python run.py --unimodal True --fusion False
python run.py --unimodal False --fusion False
Utterance level attention:
python run.py --unimodal False --fusion True --attention_2 True
python run.py --unimodal False --fusion True --attention_2 True
Note:
- Keeping the unimodal flag as True (default False) shall train all unimodal lstms first (level 1 of the network mentioned in the paper)
- Setting --fusion True applies only to multimodal network.
Datasets:
We provide results on the MOSI, MOSEI and IEMOCAP datasets.
Please cite the creators.
We are adding more datasets, stay tuned.
Use --data [mosi|mosei|iemocap] and --classes [2|3|6] in the above commands to test different configurations on different datasets.
mosi: 2 classes
mosei: 3 classes
iemocap: 6 classes
Example:
python run.py --unimodal False --fusion True --attention_2 True --data mosei --classes 3
Dataset details
MOSI:
2 classes: Positive/Negative
Raw Features: (Pickle files)
Audio: dataset/mosi/raw/audio_2way.pickle
Text: dataset/mosi/raw/text_2way.pickle
Video: dataset/mosi/raw/video_2way.pickle
Each file contains:
train_data, train_label, test_data, test_label, maxlen, train_length, test_length
train_data - np.array of dim (62, 63, feature_dim)
train_label - np.array of dim (62, 63, 2)
test_data - np.array of dim (31, 63, feature_dim)
test_label - np.array of dim (31, 63, 2)
maxlen - max utterance length int of value 63
train_length - utterance length of each video in train data.
test_length - utterance length of each video in test data.
Train/Test split: 62/31 videos. Each video has utterances. The videos are padded to 63 utterances.
IEMOCAP:
6 classes: happy/sad/neutral/angry/excited/frustrated
Raw Features: dataset/iemocap/raw/IEMOCAP_features_raw.pkl (Pickle files)
The file contains:
videoIDs[vid] = List of utterance IDs in this video in the order of occurance
videoSpeakers[vid] = List of speaker turns. e.g. [M, M, F, M, F]. here M = Male, F = Female
videoText[vid] = List of textual features for each utterance in video vid.
videoAudio[vid] = List of audio features for each utterance in video vid.
videoVisual[vid] = List of visual features for each utterance in video vid.
videoLabels[vid] = List of label indices for each utterance in video vid.
videoSentence[vid] = List of sentences for each utterance in video vid.
trainVid = List of videos (videos IDs) in train set.
testVid = List of videos (videos IDs) in test set.
Refer to the file dataset/iemocap/raw/loadIEMOCAP.py for more information. We use this data to create a speaker independent train and test splits in the format. (videos x utterances x features)
Train/Test split: 120/31 videos. Each video has utterances. The videos are padded to 110 utterances.
MOSEI:
3 classes: positive/negative/neutral
Raw Features: (Pickle files)
Audio: dataset/mosei/raw/audio_3way.pickle
Text: dataset/mosei/raw/text_3way.pickle
Video: dataset/mosei/raw/video_3way.pickle
The file contains: train_data, train_label, test_data, test_label, maxlen, train_length, test_length
train_data - np.array of dim (2250, 98, feature_dim)
train_label - np.array of dim (62, 63, 2)
test_data - np.array of dim (31, 63, feature_dim)
test_label - np.array of dim (31, 63, 2)
maxlen - max utterance length int of value 98
train_length - utterance length of each video in train data.
test_length - utterance length of each video in test data.
Train/Test split: 2250/678 videos. Each video has utterances. The videos are padded to 98 utterances.
Citation
If using this code, please cite our work using :
@inproceedings{soujanyaacl17,
title={Context-dependent sentiment analysis in user-generated videos},
author={Poria, Soujanya and Cambria, Erik and Hazarika, Devamanyu and Mazumder, Navonil and Zadeh, Amir and Morency, Louis-Philippe},
booktitle={Association for Computational Linguistics},
year={2017}
}
@inproceedings{poriaicdm17,
author={S. Poria and E. Cambria and D. Hazarika and N. Mazumder and A. Zadeh and L. P. Morency},
booktitle={2017 IEEE International Conference on Data Mining (ICDM)},
title={Multi-level Multiple Attentions for Contextual Multimodal Sentiment Analysis},
year={2017},
pages={1033-1038},
keywords={data mining;feature extraction;image classification;image fusion;learning (artificial intelligence);sentiment analysis;attention-based networks;context learning;contextual information;contextual multimodal sentiment;dynamic feature fusion;multilevel multiple attentions;multimodal sentiment analysis;recurrent model;utterances;videos;Context modeling;Feature extraction;Fuses;Sentiment analysis;Social network services;Videos;Visualization},
doi={10.1109/ICDM.2017.134},
month={Nov},}
Credits
Gangeshwar Krishnamurthy ([email protected]; Github: @gangeshwark)
Context-Dependent Sentiment Analysis in User Generated Videos
Code for the paper Context-Dependent Sentiment Analysis in User-Generated Videos (ACL 2017).
Requirements
Code is written in Python (2.7) and requires Keras (2.0.6) with Theano backend.
Description
In this paper, we propose a LSTM-based model that enables utterances to capture contextual information from their surroundings in the same video, thus aiding the classification process in multimodal sentiment analysis.

This repository contains the code for the mentioned paper. Each contextual LSTM (Figure 2 in the paper) is implemented as shown in above figure. For more details, please refer to the paper.
Note: Unlike the paper, we haven't used an SVM on the penultimate layer. This is in effort to keep the whole network differentiable at some performance cost.
Dataset
We provide results on the MOSI dataset
Please cite the creators
Preprocessing
As data is typically present in utterance format, we combine all the utterances belonging to a video using the following code
python create_data.py
Note: This will create speaker independent train and test splits
Running sc-lstm
Sample command:
python lstm.py --unimodal True
python lstm.py --unimodal False
Note: Keeping the unimodal flag as True (default False) shall train all unimodal lstms first (level 1 of the network mentioned in the paper)
Citation
If using this code, please cite our work using :
@inproceedings{soujanyaacl17,
title={Context-dependent sentiment analysis in user-generated videos},
author={Poria, Soujanya and Cambria, Erik and Hazarika, Devamanyu and Mazumder, Navonil and Zadeh, Amir and Morency, Louis-Philippe},
booktitle={Association for Computational Linguistics},
year={2017}
}
Credits
Devamanyu Hazarika, Soujanya Poria
Contextual Inter-modal Attention for Multimodal Sentiment Analysis
Code for the paper Contextual Inter-modal Attention for Multi-modal Sentiment Analysis (EMNLP 2018).
Dataset
We provide results on the MOSI dataset.
Please cite the creators.
Requirements:
Python 3.5
Keras (Tensorflow backend) 2.2.4
Scikit-learn 0.20.0
Experiments
python create_data.py
python trimodal_attention_models.py
Citation
If you use this code in your research, please cite our work using:
@inproceedings{ghosal2018contextual,
title={Contextual Inter-modal Attention for Multi-modal Sentiment Analysis},
author={Ghosal, Deepanway and Akhtar, Md Shad and Chauhan, Dushyant and Poria, Soujanya and Ekbal, Asif and Bhattacharyya, Pushpak},
booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
pages={3454--3466},
year={2018}
}
Credits
Some of the functionalities in this repo are borrowed from https://github.com/soujanyaporia/contextual-utterance-level-multimodal-sentiment-analysis
Authors
Deepanway Ghosal, Soujanya Poria
Tensor Fusion Network (TFN)
IMPORTANT NOTICE
The CMU-MultimodalSDK on which this repo depend has drastically changed its API since this code is written. Hence the code in this repo cannot be run off-the-shelf anymore. However, the code for the model itself can still be of reference.
Tensor Fusion Networks
This is a PyTorch implementation of:
Zadeh, Amir, et al. "Tensor fusion network for multimodal sentiment analysis." EMNLP 2017 Oral.
It requires PyTorch and the CMU Multimodal Data SDK (https://github.com/A2Zadeh/CMU-MultimodalDataSDK) to function properly. The training data (CMU-MOSI dataset) will be automatically downloaded if you run the script for the first time.
The model is defined in model.py, and the training script is train.py. Here's a list of commandline arguments for train.py:
--dataset: default is 'MOSI', currently don't really support other datasets. Just ignore this option
--epochs: max number of epochs, default is 50
--batch_size: batch size, default is 32
--patience: specifies the early stopping condition, similar to that in Keras, default 20
--cuda: whether or not to use GPU, default False
--model_path: a string that specifies the location for storing trained models, default='models'
--max_len: max sequence length when preprocessing data, default=20
In a nutshell, you can train the model using the following command:
python train.py --epochs 100 --patience 10
The script starts with a randomly selected set of hyper-parameters. If you want to tune it, you can change them yourself in the script.
Citation
If you use this code in your research, please cite our work using:
@inproceedings{tensoremnlp17,
title={Tensor Fusion Network for Multimodal Sentiment Analysis},
author={Zadeh, Amir and Chen, Minghai and Poria, Soujanya and Cambria, Erik and Morency, Louis-Philippe},
booktitle={Empirical Methods in Natural Language Processing, EMNLP},
year={2017}
}
Low rank Multimodal Fusion
This is the repository for "Efficient Low-rank Multimodal Fusion with Modality-Specific Factors", Liu and Shen, et. al. ACL 2018.
Dependencies
Python 2.7 (now experimentally has Python 3.6+ support)
torch=0.3.1
sklearn
numpy
You can install the libraries via python -m pip install -r requirements.txt.
Data for Experiments
The processed data for the experiments (CMU-MOSI, IEMOCAP, POM) can be downloaded here:
https://drive.google.com/open?id=1CixSaw3dpHESNG0CaCJV6KutdlANP_cr
To run the code, you should download the pickled datasets and put them in the data directory.
Note that there might be NaN values in acoustic features, you could replace them with 0s.
Training Your Model
To run the code for experiments (grid search), use the scripts train_xxx.py. They have some commandline arguments as listed here:
`--run_id`: an user-specified unique ID to ensure that saved results/models don't override each other.
`--epochs`: the number of maximum epochs in training. Since early-stopping is used to prevent overfitting, in actual training the number of epochs could be less than what you specify here.
`--patience`: if the model performance does not improve in `--patience` many validation evaluations consecutively, the training will early-stop.
`output_dim`: output dimension of the model. Default value in each script should work.
`signiture`: an optional string that's added to the output file name. Intended to use as some sort of comment.
`cuda`: whether or not to use GPU in training. If not specified, will use CPU.
`data_path`: the path to the data directory. Defaults to './data', but if you prefer storing the data else where you can change this.
`model_path`: the path to the directory where models will be saved.
`output_path`: the path to the directory where the grid search results will be saved.
`max_len`: the maximum length of training data sequences. Longer/shorter sequences will be truncated/padded.
`emotion`: (exclusive for IEMOCAP) specifies which emotion category you want to train the model to predict. Can be 'happy', 'sad', 'angry', 'neutral'.
An example would be
python train_mosi.py --run_id 19260817 --epochs 50 --patience 20 --output_dim 1 --signiture test_run_big_model
Hyperparameters
Some hyper parameters for reproducing the results in the paper are in the hyperparams.txt file.
Citation
@misc{liu2018efficient,
title={Efficient Low-rank Multimodal Fusion with Modality-Specific Factors},
author={Zhun Liu and Ying Shen and Varun Bharadhwaj Lakshminarasimhan and Paul Pu Liang and Amir Zadeh and Louis-Philippe Morency},
year={2018},
eprint={1806.00064},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
Dataset
MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation
Note
Leaderboard

Updates
10/10/2020: New paper and SOTA in Emotion Recognition in Conversations on the MELD dataset. Refer to the directory COSMIC for the code. Read the paper -- COSMIC: COmmonSense knowledge for eMotion Identification in Conversations.
22/05/2019: MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation has been accepted as a full paper at ACL 2019. The updated paper can be found here - https://arxiv.org/pdf/1810.02508.pdf
22/05/2019: Dyadic MELD has been released. It can be used to test dyadic conversational models.
15/11/2018: The problem in the train.tar.gz has been fixed.
Research Works using MELD
Zhang, Yazhou, Qiuchi Li, Dawei Song, Peng Zhang, and Panpan Wang. "Quantum-Inspired Interactive Networks for Conversational Sentiment Analysis." IJCAI 2019.
Zhang, Dong, Liangqing Wu, Changlong Sun, Shoushan Li, Qiaoming Zhu, and Guodong Zhou. "Modeling both Context-and Speaker-Sensitive Dependence for Emotion Detection in Multi-speaker Conversations." IJCAI 2019.
Ghosal, Deepanway, Navonil Majumder, Soujanya Poria, Niyati Chhaya, and Alexander Gelbukh. "DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation." EMNLP 2019.
Introduction
Multimodal EmotionLines Dataset (MELD) has been created by enhancing and extending EmotionLines dataset. MELD contains the same dialogue instances available in EmotionLines, but it also encompasses audio and visual modality along with text. MELD has more than 1400 dialogues and 13000 utterances from Friends TV series. Multiple speakers participated in the dialogues. Each utterance in a dialogue has been labeled by any of these seven emotions -- Anger, Disgust, Sadness, Joy, Neutral, Surprise and Fear. MELD also has sentiment (positive, negative and neutral) annotation for each utterance.
Example Dialogue

Dataset Statistics
| Statistics | Train | Dev | Test |
|---|---|---|---|
| # of modality | {a,v,t} | {a,v,t} | {a,v,t} |
| # of unique words | 10,643 | 2,384 | 4,361 |
| Avg. utterance length | 8.03 | 7.99 | 8.28 |
| Max. utterance length | 69 | 37 | 45 |
| Avg. # of emotions per dialogue | 3.30 | 3.35 | 3.24 |
| # of dialogues | 1039 | 114 | 280 |
| # of utterances | 9989 | 1109 | 2610 |
| # of speakers | 260 | 47 | 100 |
| # of emotion shift | 4003 | 427 | 1003 |
| Avg. duration of an utterance | 3.59s | 3.59s | 3.58s |
Please visit https://affective-meld.github.io for more details.
Dataset Distribution
| Train | Dev | Test | |
|---|---|---|---|
| Anger | 1109 | 153 | 345 |
| Disgust | 271 | 22 | 68 |
| Fear | 268 | 40 | 50 |
| Joy | 1743 | 163 | 402 |
| Neutral | 4710 | 470 | 1256 |
| Sadness | 683 | 111 | 208 |
| Surprise | 1205 | 150 | 281 |
Purpose
Multimodal data analysis exploits information from multiple-parallel data channels for decision making. With the rapid growth of AI, multimodal emotion recognition has gained a major research interest, primarily due to its potential applications in many challenging tasks, such as dialogue generation, multimodal interaction etc. A conversational emotion recognition system can be used to generate appropriate responses by analysing user emotions. Although there are numerous works carried out on multimodal emotion recognition, only a very few actually focus on understanding emotions in conversations. However, their work is limited only to dyadic conversation understanding and thus not scalable to emotion recognition in multi-party conversations having more than two participants. EmotionLines can be used as a resource for emotion recognition for text only, as it does not include data from other modalities such as visual and audio. At the same time, it should be noted that there is no multimodal multi-party conversational dataset available for emotion recognition research. In this work, we have extended, improved, and further developed EmotionLines dataset for the multimodal scenario. Emotion recognition in sequential turns has several challenges and context understanding is one of them. The emotion change and emotion flow in the sequence of turns in a dialogue make accurate context modelling a difficult task. In this dataset, as we have access to the multimodal data sources for each dialogue, we hypothesise that it will improve the context modelling thus benefiting the overall emotion recognition performance. This dataset can also be used to develop a multimodal affective dialogue system. IEMOCAP, SEMAINE are multimodal conversational datasets which contain emotion label for each utterance. However, these datasets are dyadic in nature, which justifies the importance of our Multimodal-EmotionLines dataset. The other publicly available multimodal emotion and sentiment recognition datasets are MOSEI, MOSI, MOUD. However, none of those datasets is conversational.
Dataset Creation
The first step deals with finding the timestamp of every utterance in each of the dialogues present in the EmotionLines dataset. To accomplish this, we crawled through the subtitle files of all the episodes which contains the beginning and the end timestamp of the utterances. This process enabled us to obtain season ID, episode ID, and timestamp of each utterance in the episode. We put two constraints whilst obtaining the timestamps: (a) timestamps of the utterances in a dialogue must be in increasing order, (b) all the utterances in a dialogue have to belong to the same episode and scene. Constraining with these two conditions revealed that in EmotionLines, a few dialogues consist of multiple natural dialogues. We filtered out those cases from the dataset. Because of this error correction step, in our case, we have the different number of dialogues as compare to the EmotionLines. After obtaining the timestamp of each utterance, we extracted their corresponding audio-visual clips from the source episode. Separately, we also took out the audio content from those video clips. Finally, the dataset contains visual, audio, and textual modality for each dialogue.
Paper
The paper explaining this dataset can be found - https://arxiv.org/pdf/1810.02508.pdf
Download the data
Please visit - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz to download the raw data. Data are stored in .mp4 format and can be found in XXX.tar.gz files. Annotations can be found in https://github.com/declare-lab/MELD/tree/master/data/MELD.
Description of the .csv files
Column Specification
| Column Name | Description |
|---|---|
| Sr No. | Serial numbers of the utterances mainly for referencing the utterances in case of different versions or multiple copies with different subsets |
| Utterance | Individual utterances from EmotionLines as a string. |
| Speaker | Name of the speaker associated with the utterance. |
| Emotion | The emotion (neutral, joy, sadness, anger, surprise, fear, disgust) expressed by the speaker in the utterance. |
| Sentiment | The sentiment (positive, neutral, negative) expressed by the speaker in the utterance. |
| Dialogue_ID | The index of the dialogue starting from 0. |
| Utterance_ID | The index of the particular utterance in the dialogue starting from 0. |
| Season | The season no. of Friends TV Show to which a particular utterance belongs. |
| Episode | The episode no. of Friends TV Show in a particular season to which the utterance belongs. |
| StartTime | The starting time of the utterance in the given episode in the format 'hh:mm:ss,ms'. |
| EndTime | The ending time of the utterance in the given episode in the format 'hh:mm:ss,ms'. |
The files
- /data/MELD/train_sent_emo.csv - contains the utterances in the training set along with Sentiment and Emotion labels.
- /data/MELD/dev_sent_emo.csv - contains the utterances in the dev set along with Sentiment and Emotion labels.
- /data/MELD/test_sent_emo.csv - contains the utterances in the test set along with Sentiment and Emotion labels.
- /data/MELD_Dyadic/train_sent_emo_dya.csv - contains the utterances in the training set of the dyadic variant of MELD along with Sentiment and Emotion labels. For getting the video clip corresponding to a particular utterance refer to the columns 'Old_Dialogue_ID' and 'Old_Utterance_ID'.
- /data/MELD_Dyadic/dev_sent_emo_dya.csv - contains the utterances in the dev set of the dyadic variant along with Sentiment and Emotion labels. For getting the video clip corresponding to a particular utterance refer to the columns 'Old_Dialogue_ID' and 'Old_Utterance_ID'.
- /data/MELD_Dyadic/test_sent_emo_dya.csv - contains the utterances in the test set of the dyadic variant along with Sentiment and Emotion labels. For getting the video clip corresponding to a particular utterance refer to the columns 'Old_Dialogue_ID' and 'Old_Utterance_ID'.
Description of Pickle Files
There are 13 pickle files comprising of the data and features used for training the baseline models. Following is a brief description of each of the pickle files.
Data pickle files:
- data_emotion.p, data_sentiment.p - These are the primary data files which contain 5 different elements stored as a list.
- data: It consists of a dictionary with the following key/value pairs.
- text: original sentence.
- split: train/val/test - denotes the which split the tuple belongs to.
- y: label of the sentence.
- dialog: ID of the dialog the utterance belongs to.
- utterance: utterance number of the dialog ID.
- num_words: number of words in the utterance.
- W: glove embedding matrix
- vocab: the vocabulary of the dataset
- word_idx_map: mapping of each word from vocab to its index in W.
- max_sentence_length: maximum number of tokens in an utterance in the dataset.
- label_index: mapping of each label (emotion or sentiment) to its assigned index, eg. label_index['neutral']=0
- data: It consists of a dictionary with the following key/value pairs.
import pickle
data, W, vocab, word_idx_map, max_sentence_length, label_index = pickle.load(open(filepath, 'rb'))
- text_glove_average_emotion.pkl, text_glove_average_sentiment.pkl - It consists of 300 dimensional textual feature vectors of each utterance initialized as the average of the Glove embeddings of all tokens per utterance. It is a list comprising of 3 dictionaries for train, val and the test set with each dictionary indexed in the format dia_utt, where dia is the dialogue id and utt is the utterance id. For eg. train_text_avg_emb['0_0'].shape = (300, )
import pickle
train_text_avg_emb, val_text_avg_emb, test_text_avg_emb = pickle.load(open(filepath, 'rb'))
- audio_embeddings_feature_selection_emotion.pkl,audio_embeddings_feature_selection_sentiment.pkl - It consists of 1611/1422 dimensional audio feature vectors of each utterance trained for emotion/sentiment classification. These features are originally extracted from openSMILE and then followed by L2-based feature selection using SVM. It is a list comprising of 3 dictionaries for train, val and the test set with each dictionary indexed in the format dia_utt, where dia is the dialogue id and utt is the utterance id. For eg. train_audio_emb['0_0'].shape = (1611, ) or (1422, )
import pickle
train_audio_emb, val_audio_emb, test_audio_emb = pickle.load(open(filepath, 'rb'))
Model output pickle files:
- text_glove_CNN_emotion.pkl, text_glove_CNN_sentiment.pkl - It consists of 100 dimensional textual features obtained after training on a CNN-based network for emotion/sentiment calssification. It is a list comprising of 3 dictionaries for train, val and the test set with each dictionary indexed in the format dia_utt, where dia is the dialogue id and utt is the utterance id. For eg. train_text_CNN_emb['0_0'].shape = (100, )
import pickle
train_text_CNN_emb, val_text_CNN_emb, test_text_CNN_emb = pickle.load(open(filepath, 'rb'))
- text_emotion.pkl, text_sentiment.pkl - These files contain the contextual feature representations as produced by the uni-modal bcLSTM model. It consists of 600 dimensional textual feature vector for each utterance for emotion/sentiment classification stored as a dictionary indexed with dialogue id. It is a list comprising of 3 dictionaries for train, val and the test set. For eg. train_text_emb['0'].shape = (33, 600), where 33 is the maximum number of utterances in a dialogue. Dialogues with less utterances are padded with zero-vectors.
import pickle
train_text_emb, val_text_emb, test_text_emb = pickle.load(open(filepath, 'rb'))
- audio_emotion.pkl, audio_sentiment.pkl - These files contain the contextual feature representations as produced by the uni-modal bcLSTM model. It consists of 300/600 dimensional audio feature vector for each utterance for emotion/sentiment classification stored as a dictionary indexed with dialogue id. It is a list comprising of 3 dictionaries for train, val and the test set. For eg. train_audio_emb['0'].shape = (33, 300) or (33, 600), where 33 is the maximum number of utterances in a dialogue. Dialogues with less utterances are padded with zero-vectors.
import pickle
train_audio_emb, val_audio_emb, test_audio_emb = pickle.load(open(filepath, 'rb'))
- bimodal_sentiment.pkl - This file contains the contextual feature representations as produced by the bi-imodal bcLSTM model. It consists of 600 dimensional bimodal (text, audio) feature vector for each utterance for sentiment classification stored as a dictionary indexed with dialogue id. It is a list comprising of 3 dictionaries for train, val and the test set. For eg. train_bimodal_emb['0'].shape = (33, 600), where 33 is the maximum number of utterances in a dialogue. Dialogues with less utterances are padded with zero-vectors.
import pickle
train_bimodal_emb, val_bimodal_emb, test_bimodal_emb = pickle.load(open(filepath, 'rb'))
Description of Raw Data
- There are 3 folders (.tar.gz files)-train, dev and test; each of which corresponds to video clips from the utterances in the 3 .csv files.
- In any folder, each video clip in the raw data corresponds to one utterance in the corresponding .csv file. The video clips are named in the format: diaX1_uttX2.mp4, where X1 is the Dialogue_ID and X2 is the Utterance_ID as provided in the corresponding .csv file, denoting the particular utterance.
- For example, consider the video clip dia6_utt1.mp4 in train.tar.gz. The corresponding utterance for this video clip will be in the file train_sent_emp.csv with Dialogue_ID=6 and Utterance_ID=1, which is 'You liked it? You really liked it?'
Reading the Data
There are 2 python scripts provided in './utils/':
- read_meld.py - displays the path of the video file corresponding to an utterance in the .csv file from MELD.
- read_emorynlp - displays the path of the video file corresponding to an utterance in the .csv file from Multimodal EmoryNLP Emotion Detection dataset.
Labelling
For experimentation, all the labels are represented as one-hot encodings, the indices for which are as follows:
- Emotion - {'neutral': 0, 'surprise': 1, 'fear': 2, 'sadness': 3, 'joy': 4, 'disgust': 5, 'anger': 6}. Therefore, the label corresponding to the emotion 'joy' would be [0., 0., 0., 0., 1., 0., 0.]
- Sentiment - {'neutral': 0, 'positive': 1, 'negative': 2}. Therefore, the label corresponding to the sentiment 'positive' would be [0., 1., 0.]
Class Weights
For the baseline on emotion classification, the following class weights were used. The indexing is the same as mentioned above. Class Weights: [4.0, 15.0, 15.0, 3.0, 1.0, 6.0, 3.0].
Run the baseline
Please follow these steps to run the baseline -
- Download the features from here.
- Copy these features into
./data/pickles/ - To train/test the baseline model, run the file:
baseline/baseline.pyas follows:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]- example command to train text unimodal for sentiment classification:
python baseline.py -classify Sentiment -modality text -train - use
python baseline.py -hto get help text for the parameters.
- For pre-trained models, download the model weights from here and place the pickle files inside
./data/models/.
Citation
Please cite the following papers if you find this dataset useful in your research
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation. ACL 2019.
Chen, S.Y., Hsu, C.C., Kuo, C.C. and Ku, L.W. EmotionLines: An Emotion Corpus of Multi-Party Conversations. arXiv preprint arXiv:1802.08379 (2018).
Multimodal EmoryNLP Emotion Recognition Dataset
Description
Multimodal EmoryNLP Emotion Detection Dataset has been created by enhancing and extending EmoryNLP Emotion Detection dataset. It contains the same dialogue instances available in EmoryNLP Emotion Detection dataset, but it also encompasses audio and visual modality along with text. There are more than 800 dialogues and 9000 utterances from Friends TV series exist in the multimodal EmoryNLP dataset. Multiple speakers participated in the dialogues. Each utterance in a dialogue has been labeled by any of these seven emotions -- Neutral, Joyful, Peaceful, Powerful, Scared, Mad and Sad. The annotations are borrowed from the original dataset.
Dataset Statistics
| Statistics | Train | Dev | Test |
|---|---|---|---|
| # of modality | {a,v,t} | {a,v,t} | {a,v,t} |
| # of unique words | 9,744 | 2,123 | 2,345 |
| Avg. utterance length | 7.86 | 6.97 | 7.79 |
| Max. utterance length | 78 | 60 | 61 |
| Avg. # of emotions per scene | 4.10 | 4.00 | 4.40 |
| # of dialogues | 659 | 89 | 79 |
| # of utterances | 7551 | 954 | 984 |
| # of speakers | 250 | 46 | 48 |
| # of emotion shift | 4596 | 575 | 653 |
| Avg. duration of an utterance | 5.55s | 5.46s | 5.27s |
Dataset Distribution
| Train | Dev | Test | |
|---|---|---|---|
| Joyful | 1677 | 205 | 217 |
| Mad | 785 | 97 | 86 |
| Neutral | 2485 | 322 | 288 |
| Peaceful | 638 | 82 | 111 |
| Powerful | 551 | 70 | 96 |
| Sad | 474 | 51 | 70 |
| Scared | 941 | 127 | 116 |
Data
Video clips of this dataset can be download from this link. The annotation files can be found in https://github.com/SenticNet/MELD/tree/master/data/emorynlp. There are 3 .csv files. Each entry in the first column of these csv files contain an utterance whose corresponding video clip can be found here. Each utterance and its video clip is indexed by the season no., episode no., scene id and utterance id. For example, sea1_ep2_sc6_utt3.mp4 implies the clip corresponds to the utterance with season no. 1, episode no. 2, scene_id 6 and utterance_id 3. A scene is simply a dialogue. This indexing is consistent with the original dataset. The .csv files and the video files are divided into the train, validation and test set in accordance with the original dataset. Annotations have been directly borrowed from the original EmoryNLP dataset (Zahiri et al. (2018)).
Description of the .csv files
Column Specification
| Column Name | Description |
|---|---|
| Utterance | Individual utterances from EmoryNLP as a string. |
| Speaker | Name of the speaker associated with the utterance. |
| Emotion | The emotion (Neutral, Joyful, Peaceful, Powerful, Scared, Mad and Sad) expressed by the speaker in the utterance. |
| Scene_ID | The index of the dialogue starting from 0. |
| Utterance_ID | The index of the particular utterance in the dialogue starting from 0. |
| Season | The season no. of Friends TV Show to which a particular utterance belongs. |
| Episode | The episode no. of Friends TV Show in a particular season to which the utterance belongs. |
| StartTime | The starting time of the utterance in the given episode in the format 'hh:mm:ss,ms'. |
| EndTime | The ending time of the utterance in the given episode in the format 'hh:mm:ss,ms'. |
Note: There are a few utterances for which we were not able to find the start and end time due to some inconsistencies in the subtitles. Such utterances have been omitted from the dataset. However, we encourage the users to find the corresponding utterances from the original dataset and generate video clips for the same.
Citation
Please cite the following papers if you find this dataset useful in your research
S. Zahiri and J. D. Choi. Emotion Detection on TV Show Transcripts with Sequence-based Convolutional Neural Networks. In The AAAI Workshop on Affective Content Analysis, AFFCON'18, 2018.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation. ACL 2019.
MUStARD: Multimodal Sarcasm Detection Dataset
This repository contains the dataset and code for our ACL 2019 paper:
Towards Multimodal Sarcasm Detection (An Obviously Perfect Paper)
We release the MUStARD dataset which is a multimodal video corpus for research in automated sarcasm discovery. The dataset is compiled from popular TV shows including Friends, The Golden Girls, The Big Bang Theory, and Sarcasmaholics Anonymous. MUStARD consists of audiovisual utterances annotated with sarcasm labels. Each utterance is accompanied by its context, which provides additional information on the scenario where the utterance occurs.
Example Instance

Example sarcastic utterance from the dataset along with its context and transcript.
Raw Videos
We provide a Google Drive folder with the raw video clips, including both the utterances and their respective context
Data Format
The annotations and transcripts of the audiovisual clips are available at data/sarcasm_data.json. Each instance in the JSON file is allotted one identifier (e.g. "1_60") which is a dictionary of the following items:
| Key | Value |
|---|---|
utterance |
The text of the target utterance to classify. |
speaker |
Speaker of the target utterance. |
context |
List of utterances (in chronological order) preceding the target utterance. |
context_speakers |
Respective speakers of the context utterances. |
sarcasm |
Binary label for sarcasm tag. |
Example format in JSON:
{
"1_60": {
"utterance": "It's just a privilege to watch your mind at work.",
"speaker": "SHELDON",
"context": [
"I never would have identified the fingerprints of string theory in the aftermath of the Big Bang.",
"My apologies. What's your plan?"
],
"context_speakers": [
"LEONARD",
"SHELDON"
],
"sarcasm": true
}
}
Citation
Please cite the following paper if you find this dataset useful in your research:
@inproceedings{mustard,
title = "Towards Multimodal Sarcasm Detection (An \_Obviously\_ Perfect Paper)",
author = "Castro, Santiago and
Hazarika, Devamanyu and
P{\'e}rez-Rosas, Ver{\'o}nica and
Zimmermann, Roger and
Mihalcea, Rada and
Poria, Soujanya",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = "7",
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
}
Run the code
-
Setup an environment with Conda:
conda env create -f environment.yml conda activate mustard python -c "import nltk; nltk.download('punkt')" -
Download Common Crawl pretrained GloVe word vectors of size 300d, 840B tokens somewhere.
-
Download the pre-extracted visual features to the
data/folder (sodata/features/contains the folderscontext_final/andutterances_final/with the features) or extract the visual features yourself. -
Download the pre-extracted BERT features and place the two files directly under the folder
data/(so they aredata/bert-output.jsonlanddata/bert-output-context.jsonl), or [extract the BERT features in another environment with Python 2 and TensorFlow 1.11.0 following "Using BERT to extract fixed feature vectors (like ELMo)" from BERT's repo and running:# Download BERT-base uncased in some dir: wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip # Then put the location in this var: BERT_BASE_DIR=... python extract_features.py \ --input_file=data/bert-input.txt \ --output_file=data/bert-output.jsonl \ --vocab_file=${BERT_BASE_DIR}/vocab.txt \ --bert_config_file=${BERT_BASE_DIR}/bert_config.json \ --init_checkpoint=${BERT_BASE_DIR}/bert_model.ckpt \ --layers=-1,-2,-3,-4 \ --max_seq_length=128 \ --batch_size=8
-
Check the options in
python train_svm.py -hto select a run configuration (or modifyconfig.py) and then run it:python train_svm.py # add the flags you want -
Evaluation: We evaluate using weighted F-score metric in a 5-fold cross validation scheme. The fold indices are available at
data/split_incides.p. Refer to our baseline scripts for more details.
M2H2: A Multimodal Multiparty Hindi Dataset For Humor Recognition in Conversations
The M2H2 dataset is compiled from a famous TV show "Shrimaan Shrimati Phir Se" (Total of 4.46 hours in length) and annotated them manually. We make groups of these samples (utterances) based on their context into scenes. Each utterance in each scene consists of a label indicating humor of that utterance i.e., humor or non-humor. Besides, each utterance is also annotated with its speaker and listener information. In multiparty conversation, listener identification poses a great challenge. In our dataset, we define the listener as the party in the conversation to whom the speaker is replying. Each utterance in each scene is coupled with its context utterances, which are preceding turns by the speakers participating in the conversation. It also contains multi-party conversations that are more challenging to classify than dyadic variants.
Data Format

Text Data
Raw-Text/Ep-NUMBER.tsv acts as a master annotation file which does not only contain the textual data but also contains other metadata as described below. It also contains the manually annotated labels of the utterances. Using the Episode id and scene id, one can map the utterances in the Raw-Text folder to the corresponding audio and visual segments in Raw-Audio and Raw-Visual. This should result in multimodal data. The Label column in the TSV files e.g., Raw-Text/Ep-NUMBER.tsv contains the desired manually annotated labels for each utterance.
The text data are stored in TSV format. Each of the file is named as Raw-Text/Ep-NUMBER.tsv. Here the NUMBER is episode number which one should use to map with the corresponding audio and visual segments. The text data contains the following fields:
Scenes: The scene id. It will match the corresponding audio and visual segments.
SI. No.: Utterance number.
Start_time: Start time of the utterance in the video.
End_time: End time of the utterance in the video.
Utterance: The spoken utterance.
Label: The annotated label of the utterance. This can either be humor or non-humor.
Speaker: The format is "Speaker,listener". It has the form of "Speaker_name,utterance_id" e.g., "Dilruba,u3" which means the speaker is Dilruba and he is responding to utterance no. 3. This is particularly useful to resolve coreferences in a multiparty conversation.
Audio Data
Every episode has a dedicated folder e.g., Raw-Audio/22/ contains all the annotated audio samples for Episode no. 22.
For every episode, each scene has a dedicated folder e.g., Raw-Audio/22/Scene_1 contains all the annotated audio samples for Episode no. 22 Scene 1.
Visual Data
Every episode has a dedicated folder e.g., Raw-Visual/22/ contains all the annotated visual samples for Episode no. 22.
For every episode, each scene has a dedicated folder e.g., Raw-Visual/22/Scene_1 contains all the annotated visual samples for Episode no. 22 Scene 1.
Baselines
Citation
Dushyant Singh Chauhan, Gopendra Vikram Singh, Navonil Majumder, Amir Zadeh,, Asif Ekbal, Pushpak Bhattacharyya, Louis-philippe Morency, and Soujanya Poria. 2021. M2H2: A Multimodal MultipartyHindi Dataset For Humor Recognition in Conversations. In ICMI ’21: 23rd ACM International Conference on Multimodal Interaction, Montreal, Canada. ACM, New York, NY, USA, 5 pages.






 129 Dec 11, 2022
129 Dec 11, 2022
 11 Dec 16, 2022
11 Dec 16, 2022
 298 Jan 7, 2023
298 Jan 7, 2023
 18 Oct 21, 2022
18 Oct 21, 2022
 68 Jan 3, 2023
68 Jan 3, 2023
 10 Jan 1, 2023
10 Jan 1, 2023
 76 Dec 22, 2022
76 Dec 22, 2022
 74 Dec 30, 2022
74 Dec 30, 2022
 68 Dec 28, 2022
68 Dec 28, 2022
 349 Dec 8, 2022
349 Dec 8, 2022
 5 Jan 4, 2023
5 Jan 4, 2023
 2 Oct 5, 2022
2 Oct 5, 2022
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
 47 Jan 1, 2023
47 Jan 1, 2023
 7 Dec 16, 2021
7 Dec 16, 2021
 3 Nov 30, 2021
3 Nov 30, 2021
 89 Jan 4, 2023
89 Jan 4, 2023
 55 Dec 9, 2022
55 Dec 9, 2022