![]()
![]()
![]()
![]()
![]()


Overview
Feast is an open source feature store for machine learning. Feast is the fastest path to productionizing analytic data for model training and online inference.
Please see our documentation for more information about the project.
📐
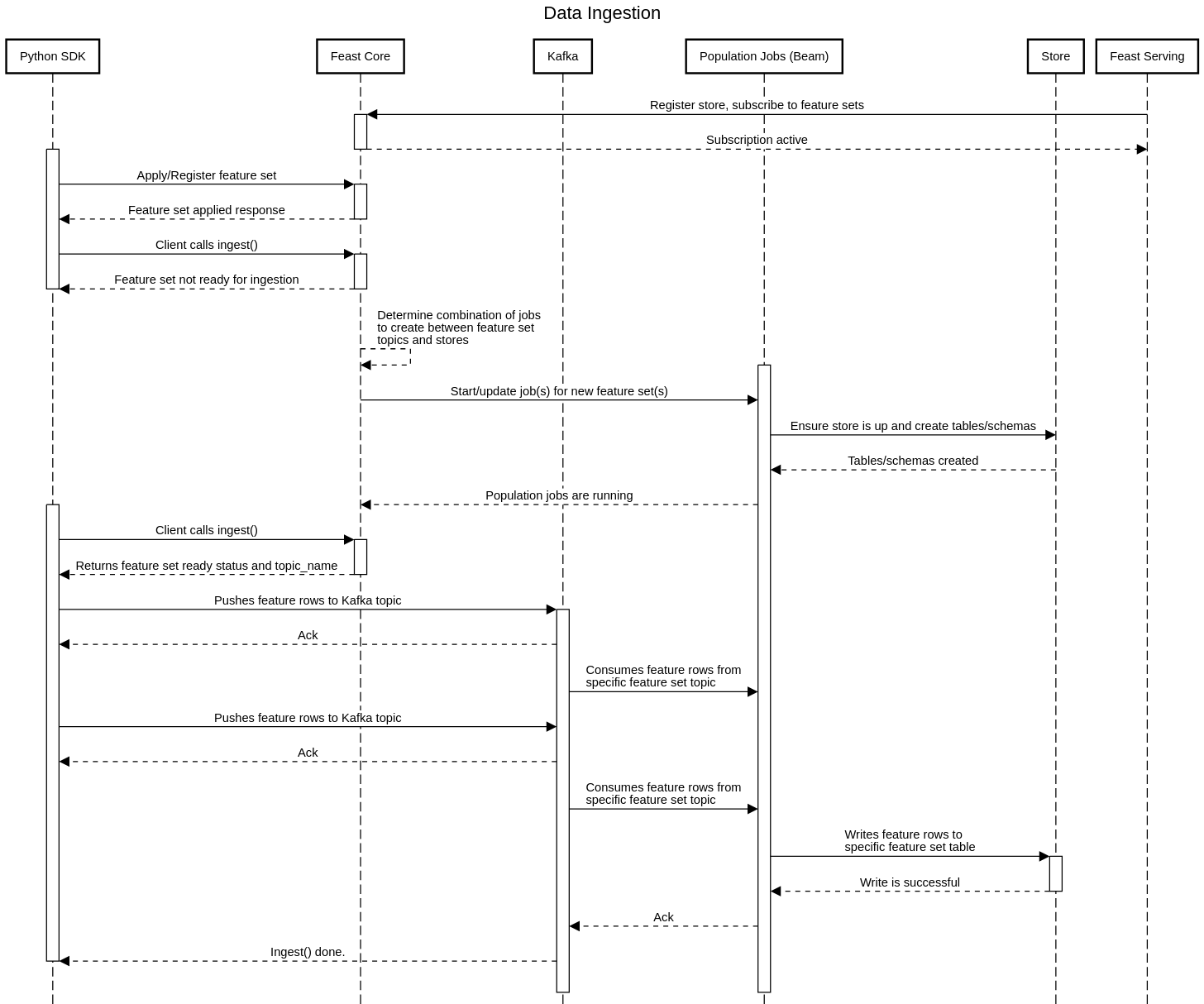
Architecture

The above architecture is the minimal Feast deployment. Want to run the full Feast on GCP/AWS? Click here.
🐣
Getting Started
1. Install Feast
pip install feast
2. Create a feature repository
feast init my_feature_repo
cd my_feature_repo
3. Register your feature definitions and set up your feature store
feast apply
4. Build a training dataset
from feast import FeatureStore
import pandas as pd
from datetime import datetime
entity_df = pd.DataFrame.from_dict({
"driver_id": [1001, 1002, 1003, 1004],
"event_timestamp": [
datetime(2021, 4, 12, 10, 59, 42),
datetime(2021, 4, 12, 8, 12, 10),
datetime(2021, 4, 12, 16, 40, 26),
datetime(2021, 4, 12, 15, 1 , 12)
]
})
store = FeatureStore(repo_path=".")
training_df = store.get_historical_features(
entity_df=entity_df,
features = [
'driver_hourly_stats:conv_rate',
'driver_hourly_stats:acc_rate',
'driver_hourly_stats:avg_daily_trips'
],
).to_df()
print(training_df.head())
# Train model
# model = ml.fit(training_df)
event_timestamp driver_id conv_rate acc_rate avg_daily_trips
0 2021-04-12 08:12:10+00:00 1002 0.713465 0.597095 531
1 2021-04-12 10:59:42+00:00 1001 0.072752 0.044344 11
2 2021-04-12 15:01:12+00:00 1004 0.658182 0.079150 220
3 2021-04-12 16:40:26+00:00 1003 0.162092 0.309035 959
5. Load feature values into your online store
CURRENT_TIME=$(date -u +"%Y-%m-%dT%H:%M:%S")
feast materialize-incremental $CURRENT_TIME
Materializing feature view driver_hourly_stats from 2021-04-14 to 2021-04-15 done!
6. Read online features at low latency
from pprint import pprint
from feast import FeatureStore
store = FeatureStore(repo_path=".")
feature_vector = store.get_online_features(
features=[
'driver_hourly_stats:conv_rate',
'driver_hourly_stats:acc_rate',
'driver_hourly_stats:avg_daily_trips'
],
entity_rows=[{"driver_id": 1001}]
).to_dict()
pprint(feature_vector)
# Make prediction
# model.predict(feature_vector)
{
"driver_id": [1001],
"driver_hourly_stats__conv_rate": [0.49274],
"driver_hourly_stats__acc_rate": [0.92743],
"driver_hourly_stats__avg_daily_trips": [72]
}
📦
Functionality and Roadmap
The list below contains the functionality that contributors are planning to develop for Feast
- Items below that are in development (or planned for development) will be indicated in parentheses.
- We welcome contribution to all items in the roadmap!
- Want to influence our roadmap and prioritization? Submit your feedback to this form.
- Want to speak to a Feast contributor? We are more than happy to jump on a call. Please schedule a time using Calendly.
- Data Sources
- Redshift source
- BigQuery source
- Parquet file source
- Synapse source (community plugin)
- Hive (community plugin)
- Postgres (community plugin)
- Kafka source (with push support into the online store)
- Snowflake source (Planned for Q4 2021)
- HTTP source
- Offline Stores
- Redshift
- BigQuery
- Synapse (community plugin)
- Hive (community plugin)
- Postgres (community plugin)
- In-memory / Pandas
- Custom offline store support
- Snowflake (Planned for Q4 2021)
- Trino (Planned for Q4 2021)
- Online Stores
- Streaming
- Custom streaming ingestion job support
- Push based streaming data ingestion
- Streaming ingestion on AWS
- Streaming ingestion on GCP
- Feature Engineering
- On-demand Transformations (Alpha release. See RFC)
- Batch transformation (SQL)
- Streaming transformation
- Deployments
- AWS Lambda (Alpha release. See RFC)
- Cloud Run
- Kubernetes
- KNative
- Feature Serving
- Data Quality Management
- Data profiling and validation (Great Expectations) (Planned for Q4 2021)
- Metric production
- Training-serving skew detection
- Drift detection
- Alerting
- Feature Discovery and Governance
- Python SDK for browsing feature registry
- CLI for browsing feature registry
- Model-centric feature tracking (feature services)
- REST API for browsing feature registry
- Feast Web UI (Planned for Q4 2021)
- Feature versioning
- Amundsen integration
🎓
Important Resources
Please refer to the official documentation at Documentation
👋
Contributing
Feast is a community project and is still under active development. Please have a look at our contributing and development guides if you want to contribute to the project:
- Contribution Process for Feast
- Development Guide for Feast
- Development Guide for the Main Feast Repository
✨
Contributors
Thanks goes to these incredible people:

















 2 Aug 22, 2022
2 Aug 22, 2022
 0 Jan 5, 2022
0 Jan 5, 2022
 6 Oct 2, 2022
6 Oct 2, 2022
 59 Dec 5, 2022
59 Dec 5, 2022
 0 Feb 14, 2022
0 Feb 14, 2022
 14 Jan 4, 2023
14 Jan 4, 2023
 6.1k Jan 5, 2023
6.1k Jan 5, 2023
 168 Dec 30, 2022
168 Dec 30, 2022
 28 May 31, 2022
28 May 31, 2022
 21.8k Jan 9, 2023
21.8k Jan 9, 2023
 8.1k Jan 6, 2023
8.1k Jan 6, 2023
 2.4k Dec 31, 2022
2.4k Dec 31, 2022
 374 Dec 15, 2022
374 Dec 15, 2022
 326 Jan 3, 2023
326 Jan 3, 2023
 7 Dec 18, 2021
7 Dec 18, 2021
 0 Feb 23, 2022
0 Feb 23, 2022
 84 Nov 25, 2022
84 Nov 25, 2022