Hi kelly, I read the code and find that the get_data_loader function get the same batch samples every iteration, is that you want? (sorry, I'm not familiar with the maml algorithm.)
below is the samples got from the get_data_loader funtion.
('test train loader: ', ['../data/omniglot/images_evaluation/Kannada/character01/1205_20.png',
'../data/omniglot/images_evaluation/Manipuri/character05/1323_07.png',
'../data/omniglot/images_evaluation/Angelic/character06/0970_19.png',
'../data/omniglot/images_evaluation/ULOG/character14/1611_15.png',
'../data/omniglot/images_evaluation/Keble/character02/1247_11.png',
'../data/omniglot/images_evaluation/Kannada/character05/1209_20.png',
'../data/omniglot/images_evaluation/Sylheti/character05/1507_12.png',
'../data/omniglot/images_evaluation/Manipuri/character15/1333_01.png',
'../data/omniglot/images_evaluation/Kannada/character27/1231_08.png',
'../data/omniglot/images_evaluation/Mongolian/character30/1388_20.png',
'../data/omniglot/images_evaluation/Keble/character07/1252_12.png',
'../data/omniglot/images_evaluation/Tibetan/character05/1560_19.png',
'../data/omniglot/images_evaluation/Glagolitic/character14/1128_04.png',
'../data/omniglot/images_evaluation/Ge_ez/character06/1094_07.png',
'../data/omniglot/images_evaluation/Avesta/character05/1067_17.png',
'../data/omniglot/images_evaluation/Malayalam/character05/1276_16.png',
'../data/omniglot/images_evaluation/Aurek-Besh/character03/1039_18.png',
'../data/omniglot/images_evaluation/Syriac_(Serto)/character14/1493_07.png',
'../data/omniglot/images_evaluation/Keble/character16/1261_09.png',
'../data/omniglot/images_evaluation/Aurek-Besh/character13/1049_15.png'])
('test train loader: ', ['../data/omniglot/images_evaluation/Syriac_(Serto)/character14/1493_07.png',
'../data/omniglot/images_evaluation/Sylheti/character05/1507_12.png',
'../data/omniglot/images_evaluation/Keble/character16/1261_09.png',
'../data/omniglot/images_evaluation/Ge_ez/character06/1094_07.png',
'../data/omniglot/images_evaluation/Tibetan/character05/1560_19.png',
'../data/omniglot/images_evaluation/Manipuri/character05/1323_07.png',
'../data/omniglot/images_evaluation/Kannada/character05/1209_20.png',
'../data/omniglot/images_evaluation/Manipuri/character15/1333_01.png',
'../data/omniglot/images_evaluation/Avesta/character05/1067_17.png',
'../data/omniglot/images_evaluation/ULOG/character14/1611_15.png',
'../data/omniglot/images_evaluation/Glagolitic/character14/1128_04.png',
'../data/omniglot/images_evaluation/Malayalam/character05/1276_16.png',
'../data/omniglot/images_evaluation/Aurek-Besh/character13/1049_15.png',
'../data/omniglot/images_evaluation/Kannada/character01/1205_20.png',
'../data/omniglot/images_evaluation/Keble/character02/1247_11.png',
'../data/omniglot/images_evaluation/Angelic/character06/0970_19.png',
'../data/omniglot/images_evaluation/Aurek-Besh/character03/1039_18.png',
'../data/omniglot/images_evaluation/Mongolian/character30/1388_20.png',
'../data/omniglot/images_evaluation/Kannada/character27/1231_08.png',
'../data/omniglot/images_evaluation/Keble/character07/1252_12.png'])
('test train loader: ', ['../data/omniglot/images_evaluation/Kannada/character05/1209_20.png',
'../data/omniglot/images_evaluation/Malayalam/character05/1276_16.png',
'../data/omniglot/images_evaluation/Manipuri/character05/1323_07.png',
'../data/omniglot/images_evaluation/Tibetan/character05/1560_19.png',
'../data/omniglot/images_evaluation/Kannada/character27/1231_08.png',
'../data/omniglot/images_evaluation/Ge_ez/character06/1094_07.png',
'../data/omniglot/images_evaluation/Keble/character16/1261_09.png',
'../data/omniglot/images_evaluation/Kannada/character01/1205_20.png',
'../data/omniglot/images_evaluation/Glagolitic/character14/1128_04.png',
'../data/omniglot/images_evaluation/Angelic/character06/0970_19.png',
'../data/omniglot/images_evaluation/Aurek-Besh/character03/1039_18.png',
'../data/omniglot/images_evaluation/ULOG/character14/1611_15.png',
'../data/omniglot/images_evaluation/Aurek-Besh/character13/1049_15.png',
'../data/omniglot/images_evaluation/Keble/character02/1247_11.png',
'../data/omniglot/images_evaluation/Sylheti/character05/1507_12.png',
'../data/omniglot/images_evaluation/Avesta/character05/1067_17.png',
'../data/omniglot/images_evaluation/Manipuri/character15/1333_01.png',
'../data/omniglot/images_evaluation/Syriac_(Serto)/character14/1493_07.png',
'../data/omniglot/images_evaluation/Mongolian/character30/1388_20.png',
'../data/omniglot/images_evaluation/Keble/character07/1252_12.png'])
('test train loader: ', ['../data/omniglot/images_evaluation/Keble/character02/1247_11.png',
'../data/omniglot/images_evaluation/ULOG/character14/1611_15.png',
'../data/omniglot/images_evaluation/Tibetan/character05/1560_19.png',
'../data/omniglot/images_evaluation/Kannada/character27/1231_08.png',
'../data/omniglot/images_evaluation/Kannada/character05/1209_20.png',
'../data/omniglot/images_evaluation/Syriac_(Serto)/character14/1493_07.png',
'../data/omniglot/images_evaluation/Aurek-Besh/character03/1039_18.png',
'../data/omniglot/images_evaluation/Avesta/character05/1067_17.png',
'../data/omniglot/images_evaluation/Glagolitic/character14/1128_04.png', '../data/omniglot/images_evaluation/Malayalam/character05/1276_16.png', '../data/omniglot/images_evaluation/Mongolian/character30/1388_20.png', '../data/omniglot/images_evaluation/Manipuri/character15/1333_01.png', '../data/omniglot/images_evaluation/Manipuri/character05/1323_07.png', '../data/omniglot/images_evaluation/Aurek-Besh/character13/1049_15.png', '../data/omniglot/images_evaluation/Sylheti/character05/1507_12.png', '../data/omniglot/images_evaluation/Kannada/character01/1205_20.png', '../data/omniglot/images_evaluation/Ge_ez/character06/1094_07.png', '../data/omniglot/images_evaluation/Keble/character07/1252_12.png', '../data/omniglot/images_evaluation/Keble/character16/1261_09.png', '../data/omniglot/images_evaluation/Angelic/character06/0970_19.png'])
('test train loader: ',
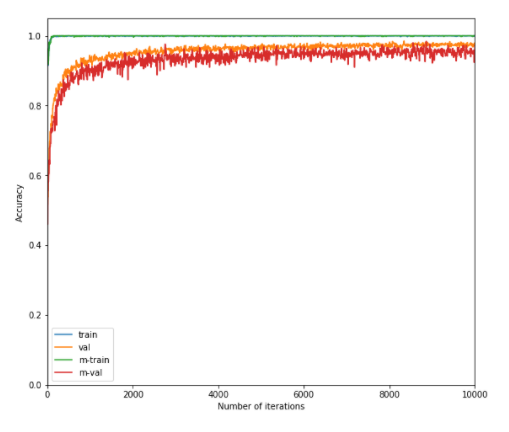
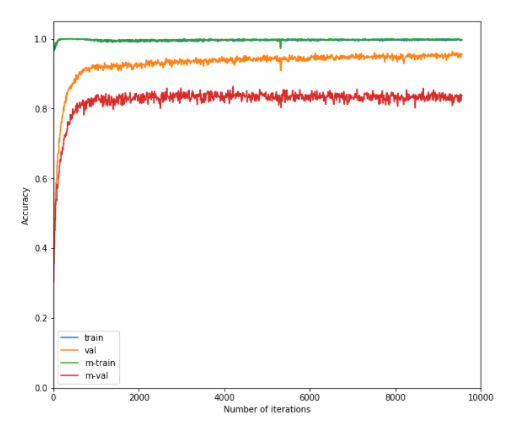

 Line 10, Algorithm2 from the original paper indicates that meta_update is performed using each D'_i. To do so with your code, I think the function meta_update need access to every task sampled, since each task contains its D'_i in your implementation.
https://github.com/katerakelly/pytorch-maml/blob/75907aca148ad053dfaf75fc138319f0d89534a8/src/maml.py#L172
However, it seems that you perform meta_update with a single task, resulting in using only one D'_i of a specific task.
Line 10, Algorithm2 from the original paper indicates that meta_update is performed using each D'_i. To do so with your code, I think the function meta_update need access to every task sampled, since each task contains its D'_i in your implementation.
https://github.com/katerakelly/pytorch-maml/blob/75907aca148ad053dfaf75fc138319f0d89534a8/src/maml.py#L172
However, it seems that you perform meta_update with a single task, resulting in using only one D'_i of a specific task.












 137 Dec 13, 2022
137 Dec 13, 2022
 22 Jan 5, 2023
22 Jan 5, 2023
 113 Dec 27, 2022
113 Dec 27, 2022
 3 Jan 3, 2023
3 Jan 3, 2023
 47 Dec 28, 2022
47 Dec 28, 2022
 112 Oct 23, 2022
112 Oct 23, 2022
 131 Dec 13, 2022
131 Dec 13, 2022
 15 Nov 18, 2022
15 Nov 18, 2022
 14 Nov 13, 2022
14 Nov 13, 2022
 15 Oct 14, 2022
15 Oct 14, 2022
 6 Mar 17, 2022
6 Mar 17, 2022
 3 Dec 27, 2022
3 Dec 27, 2022
 18 Aug 4, 2022
18 Aug 4, 2022
 10 Aug 24, 2022
10 Aug 24, 2022
 15 Nov 21, 2022
15 Nov 21, 2022
 26 Oct 5, 2022
26 Oct 5, 2022
 789 Dec 29, 2022
789 Dec 29, 2022
 8 Oct 14, 2021
8 Oct 14, 2021