minnn
by Graham Neubig, Zhisong Zhang, and Divyansh Kaushik
This is an exercise in developing a minimalist neural network toolkit for NLP, part of Carnegie Mellon University's CS11-747: Neural Networks for NLP.
The most important files it contains are the following:
- minnn.py: This is what you'll need to implement. It implements a very minimalist version of a dynamic neural network toolkit (like PyTorch or Dynet). Some code is provided, but important functionality is not included.
- classifier.py: training code for a Deep Averaging Network for text classification using minnn. You can feel free to make any modifications to make it a better model, but the original version of
classifier.pymust also run with yourminnn.pyimplementation. - setup.py: this is blank, but if your classifier implementation needs to do some sort of data downloading (e.g. of pre-trained word embeddings) you can implement this here. It will be run before running your implementation of classifier.py.
- data/: Two datasets, one from the Stanford Sentiment Treebank with tree info removed and another from IMDb reviews.
Assignment Details
Important Notes:
- There is a detailed description of the code structure in structure.md, including a description of which parts you will need to implement.
- The only allowed external library is
numpyorcupy, no other external libraries are allowed. - We will run your code with the following commands, so make sure that whatever your best results are are reproducible using these commands (where you replace
ANDREWIDwith your andrew ID):mkdir -p ANDREWIDpython classifier.py --train=data/sst-train.txt --dev=data/sst-dev.txt --test=data/sst-test.txt --dev_out=ANDREWID/sst-dev-output.txt --test_out=ANDREWID/sst-test-output.txtpython classifier.py --train=data/cfimdb-train.txt --dev=data/cfimdb-dev.txt --test=data/cfimdb-test.txt --dev_out=ANDREWID/cfimdb-dev-output.txt --test_out=ANDREWID/cfimdb-test-output.txt
- Reference accuracies: with our implementation and the default hyper-parameters, the mean(std) of accuracies with 10 different random seeds on sst is dev=0.4045(0.0070), test=0.4069(0.0105), and on cfimdb dev=0.8792(0.0084). If you implement things exactly in our way and use the default random seed and use the same environment (python 3.8 + numpy 1.18 or 1.19), you may get the accuracies of dev=0.4114, test=0.4253, and on cfimdb dev=0.8857.
The submission file should be a zip file with the following structure (assuming the andrew id is ANDREWID):
- ANDREWID/
- ANDREWID/minnn.py
# completed minnn.py - ANDREWID/classifier.py.py
# completed classifier.py with any of your modifications - ANDREWID/sst-dev-output.txt
# output of the dev set for SST data - ANDREWID/sst-test-output.txt
# output of the test set for SST data - ANDREWID/cfimdb-dev-output.txt
# output of the dev set for CFIMDB data - ANDREWID/cfimdb-test-output.txt
# output of the test set for CFIMDB data - ANDREWID/report.pdf
# (optional), report. here you can describe anything particularly new or interesting that you did
Grading information:
- A+: Submissions that implement something new and achieve particularly large accuracy improvements (e.g. 2% over the baseline on SST)
- A: You additionally implement something else on top of the missing pieces, some examples include:
- Implementing another optimizer such as Adam
- Incorporating pre-trained word embeddings, such as those from fasttext
- Changing the model architecture significantly
- A-: You implement all the missing pieces and the original
classifier.pycode achieves comparable accuracy to our reference implementation (about 41% on SST) - B+: All missing pieces are implemented, but accuracy is not comparable to the reference.
- B or below: Some parts of the missing pieces are not implemented.
References
Stanford Sentiment Treebank: https://www.aclweb.org/anthology/D13-1170.pdf
IMDb Reviews: https://openreview.net/pdf?id=Sklgs0NFvr
 6.4k Jan 1, 2023
6.4k Jan 1, 2023

 4.8k Dec 30, 2022
4.8k Dec 30, 2022
 32 Nov 9, 2021
32 Nov 9, 2021
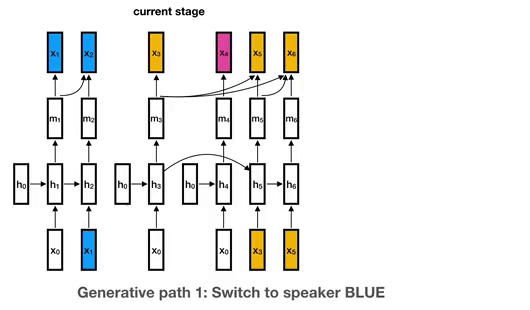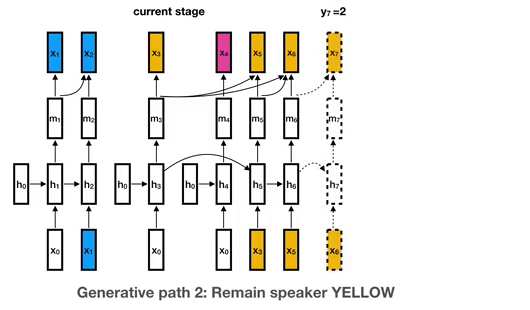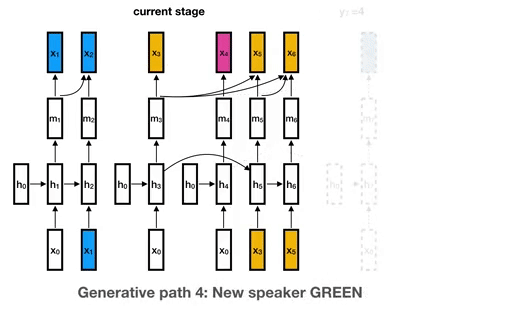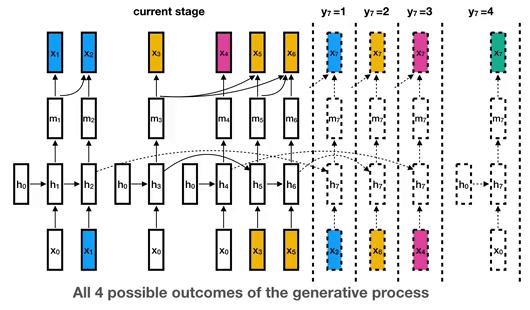

 22 Nov 13, 2022
22 Nov 13, 2022
 20 Dec 29, 2022
20 Dec 29, 2022

 152 Sep 2, 2022
152 Sep 2, 2022



 919 Jan 3, 2023
919 Jan 3, 2023
 121 Jan 5, 2023
121 Jan 5, 2023
 12.8k Jan 3, 2023
12.8k Jan 3, 2023
 17 Nov 22, 2022
17 Nov 22, 2022
 2 Dec 2, 2021
2 Dec 2, 2021
 1 Dec 9, 2021
1 Dec 9, 2021
 2 Jan 20, 2022
2 Jan 20, 2022
 7 Aug 25, 2022
7 Aug 25, 2022
 19 Dec 17, 2022
19 Dec 17, 2022