Discretization Robust Correspondence Benchmark
One challenge of machine learning on 3D surfaces is that there are many different representations/samplings ("discretizations") which all encode the same underlying shape---consider e.g. different triangle meshes of a surface. We expect models to generalize across these representations; the purpose of this benchmark is to measure generalization of 3D machine learning models across different discretizations
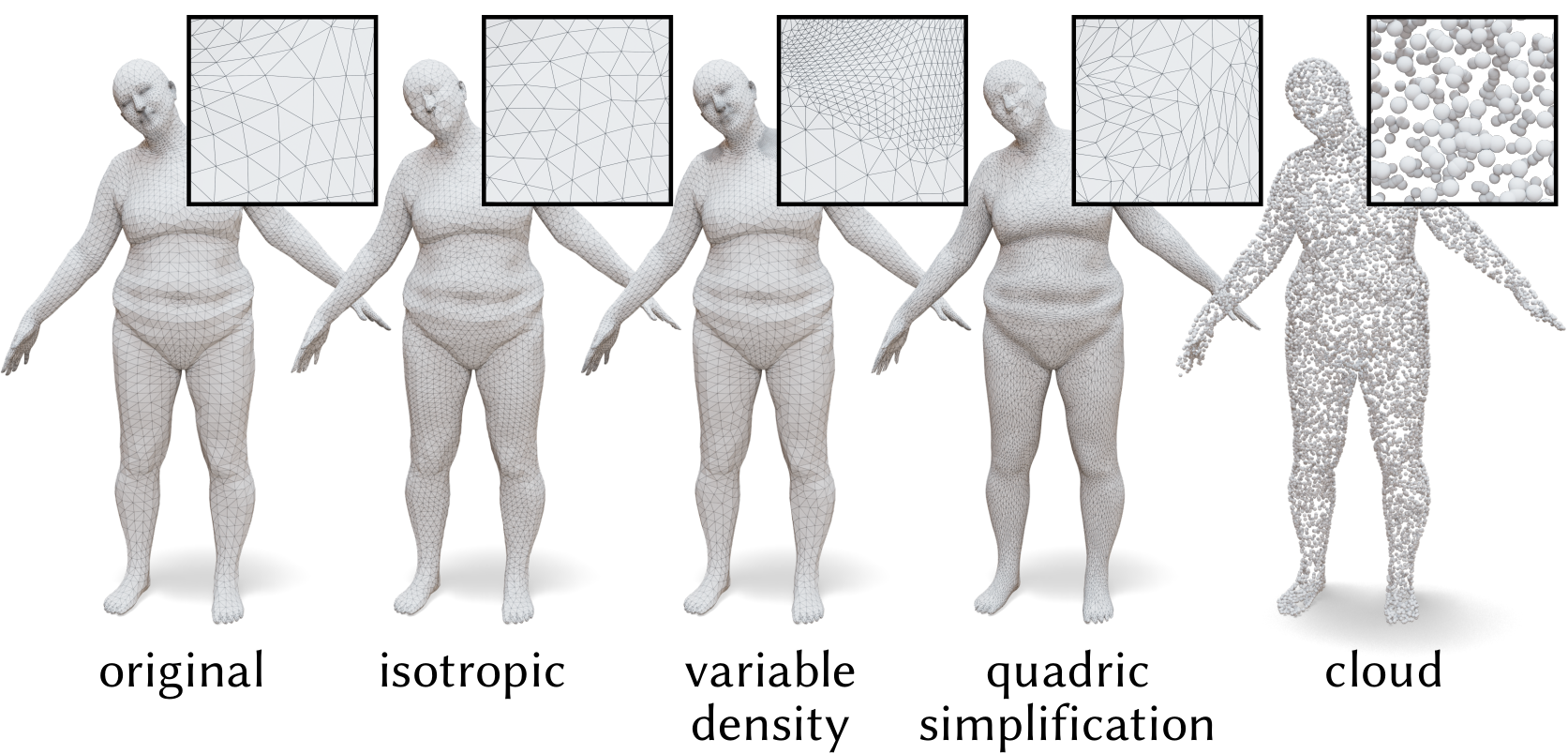
This benchmark contains test meshes of human bodies, derived from the MPI-FAUST dataset, remeshed/resampled according to several policies. The task is to predict correspondence, defined by predicting the nearest vertex index on the template mesh. We intentionally provide test data only. The intent of this benchmark is that methods train on the ordinary FAUST template meshes, then evaluate on this dataset. This measures the ability of the method to generalize to new, unseen discretizations of shapes.
From: DiffusionNet: Discretization Agnostic Learning on Surfaces, Nicholas Sharp, Souhaib Attaiki, Keenan Crane, Maks Ovsjanikov, conditionally accepted to ACM ToG 2021.
Please cite this benchmark as:
@article{sharp2021diffusion,
author = {Sharp, Nicholas and Attaiki, Souhaib and Crane, Keenan and Ovsjanikov, Maks},
title = {DiffusionNet: Discretization Agnostic Learning on Surfaces},
journal = {ACM Trans. Graph.},
volume = {XX},
number = {X},
year = {20XX},
publisher = {ACM},
address = {New York, NY, USA},
}
Remeshing/sampling policies
isoMeshes are isotropically remeshed, to have a roughly uniform distribution of vetices, with approximately equilateral trianglesqesMeshes are first refined to have many more vertices, then simplified back to approximately 2x the original resolution using Quadric Error SimplificationmcMeshes are volumetrically reconstructed, and a mesh is extracted via the marching cubes algorithm.denseMeshes are refined to have nonuniform density by choosing 5 random faces, refining the mesh in the vicinity of the face, then isotropically remeshing.cloudA point cloud, with normals, sampled uniformly from the mesh
In this repository
data/iso/tr_reg_iso_080.plyFAUST test mesh 80, remeshed according to theisostrategytr_reg_iso_080.txtGround-truth correspondence indices, per-vertex- ...
tr_reg_iso_099.plytr_reg_iso_099.txt
qes/tr_reg_qes_080.plytr_reg_qes_080.txt- ...
mc/tr_reg_mc_080.plytr_reg_mc_080.txt- ...
dense/tr_reg_dense_080.plytr_reg_dense_080.txt- ...
cloud/tr_reg_cloud_080.plyA sampled point cloud from FAUST test mesh 80, with normalstr_reg_cloud_080.txtGround-truth correspondence indices, per-point- ...
scripts/Meshlab & Python scripts which were used to generate the data.
Notes about the data
- The meshes are not necessarily high quality! In particular, the
mcmeshes have coincident vertices and degenerate leftover from the marching cubes process. Such artifacts are a common occurence in real data.
Benchmark Task
This benchmark is designed for template correspondence via vertex index prediction. That is, for each vertex (resp., point) in a test shape, we predict the corresponding nearest vertex on a template mesh. The FAUST template mesh has 6890 vertices, so this is essentially a segmentation problem with classes from [0, 6899]. Note that although popular in past work, this categorical formulation is surely not the best notion of correspondence between surfaces. However, it is very simple, and exposes a tendancy to overfit to discretization, which makes it a good choice for this benchmark.
The first 80 original MPI-FAUST template meshes should be used as training data: i.e. tr_reg_000.ply-tr_reg_079.ply. The last 20 shapes are taken as the test set, and remeshed/resampled for the purpose of this benchmark. These original meshes are already deformed templates, so the ground truth vertex labels are simply [0,1,2,3,4...]. We do not host the original data here; you must download it from http://faust.is.tue.mpg.de/.
After training on the first 80 original FAUST meshes, we evaluate on the test meshes, predicting corresponding vertices. Error is measured by the geodesic distance along the template mesh between the predicted vertex and the ground-truth vertex. (% of vertices predicted exactly correct is not really a meaningful metric.) See this repo for a full example of training and eval scripts.
Papers using this dataset
(create a pull request to add more!)
- "DiffusionNet: Discretization Agnostic Learning on Surfaces" by Sharp et al., ACM ToG 2021
License
The scripts which generate the data are available for any use under an MIT license (C) Nicholas Sharp 2021.
The remeshed/sampled meshes are derived from the MPI-FAUST dataset, governed by this license (which allows derivative works).
 81 Nov 26, 2022
81 Nov 26, 2022
 3 Feb 25, 2022
3 Feb 25, 2022
 10 Dec 11, 2022
10 Dec 11, 2022

 136 Dec 12, 2022
136 Dec 12, 2022
![[CVPR'21] FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space](https://github.com/liuquande/FedDG-ELCFS/raw/main/figure/cvpr21_feddg.png)
 178 Jan 6, 2023
178 Jan 6, 2023
 13 Apr 26, 2021
13 Apr 26, 2021
 120 Dec 28, 2022
120 Dec 28, 2022
 13 Nov 30, 2022
13 Nov 30, 2022
 5.7k Jan 9, 2023
5.7k Jan 9, 2023


 14 Nov 28, 2022
14 Nov 28, 2022
 6.1k Jan 5, 2023
6.1k Jan 5, 2023
 23 Oct 9, 2022
23 Oct 9, 2022
 1.1k Dec 24, 2022
1.1k Dec 24, 2022
 44 Dec 27, 2022
44 Dec 27, 2022
 437 Dec 30, 2022
437 Dec 30, 2022
 114 Jul 19, 2022
114 Jul 19, 2022
 71 Dec 30, 2022
71 Dec 30, 2022
 21.8k Jan 9, 2023
21.8k Jan 9, 2023
 6 May 7, 2022
6 May 7, 2022