Make-A-Scene - PyTorch
Pytorch implementation (inofficial) of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors (https://arxiv.org/pdf/2203.13131.pdf)
 Figure 1. from paper
Figure 1. from paper
Note: this is work in progress.
Everyone is happily invited to contribute --> Discord Channel: https://discord.gg/hCRMGRZkC6
We would love to open-source a trained model. The model is a billion parameter model. Training it requires a lot of compute. If anyone can provide computational resources, let us know.
Paper Description:
Make-A-Scene modifies the VQGAN framework. It makes heavy use of using semantic segmentation maps for extra conditioning. This enables more influence on the generation process. Morever, it also conditions on text. The main improvements are the following:
- Segmentation condition: separate VQVAE is trained (VQ-SEG) + loss modified to a weighted binary cross entropy. (3.4)
- VQGAN training (VQ-IMG) is extended by Face-Loss & Object-Loss (3.3 & 3.5)
- Classifier Guidance for the autoregressive transformer (3.7)
Training Pipeline
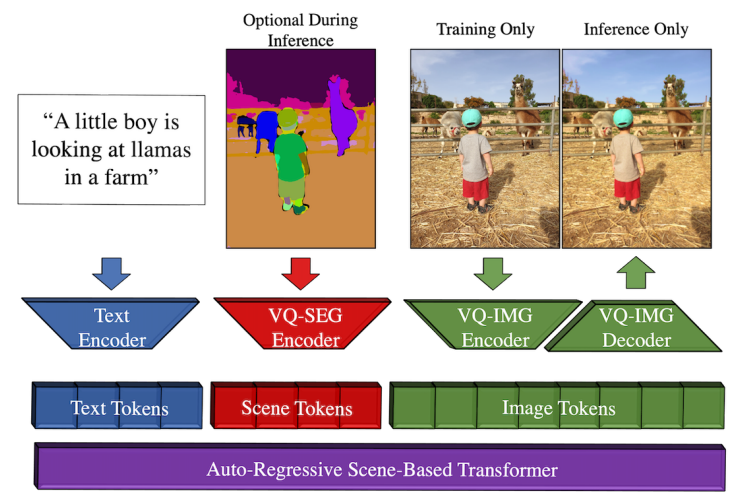 Figure 6. from paper
Figure 6. from paper
What needs to be done?
Refer to the different folders to see details.
Citation
@misc{https://doi.org/10.48550/arxiv.2203.13131,
doi = {10.48550/ARXIV.2203.13131},
url = {https://arxiv.org/abs/2203.13131},
author = {Gafni, Oran and Polyak, Adam and Ashual, Oron and Sheynin, Shelly and Parikh, Devi and Taigman, Yaniv},
title = {Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}

 293 Dec 22, 2022
293 Dec 22, 2022

 283 Dec 27, 2022
283 Dec 27, 2022

 56 Oct 26, 2022
56 Oct 26, 2022

 66 Nov 16, 2022
66 Nov 16, 2022

 104 Jan 5, 2023
104 Jan 5, 2023

 173 Dec 26, 2022
173 Dec 26, 2022

 6 Dec 1, 2021
6 Dec 1, 2021

 24 Jul 7, 2022
24 Jul 7, 2022

 303 Dec 27, 2022
303 Dec 27, 2022




 35 Nov 20, 2022
35 Nov 20, 2022
 183 Jan 3, 2023
183 Jan 3, 2023
 23 Oct 17, 2022
23 Oct 17, 2022
 52 Dec 22, 2022
52 Dec 22, 2022
 762 Jan 8, 2023
762 Jan 8, 2023
 134 Dec 6, 2022
134 Dec 6, 2022
 151 Dec 26, 2022
151 Dec 26, 2022
 604 Dec 14, 2022
604 Dec 14, 2022
 27 Dec 20, 2022
27 Dec 20, 2022