



HiLive
A live streaming chatroom involving multiple modalities, such as voice, gesture, and facial expression.
Introduction
We focus on demonstrating the design, as well as highlighting the advantages and our considerations on design features, using the knowledge and design principles learned in CS3483.
As mentioned in our previous design reports, the project is motivated by the limited chatroom in the live stream. This interface is designed for a better chatroom experience in a live streaming platform based on Twitch, which is a popular video game live streaming platform. It also could be further generalized and adopted by video platforms like YouTube. Viewers usually type some messages in the chatroom and send some emojis to communicate with others and vibrant the atmosphere in the streaming room. However, the monotonous form of interaction has long been criticized by users. Therefore, we propose HiLive, where people can not only send emojis that are generalized according to their recognized facial expression but also say something and send the transcribed message directly without typing it out themselves. With the gesture recognition function, users are no longer bound to the keyboard, therefore, they can have an immersive live streaming interaction experience.
Features
Front Page
The front page levereage the use if Twitch API, and the OAuth authentication system. Users can login and register to the website with Twitch account. And the front page also provides a list of avaliable Live streams for users to click into it.

Recommended Channels Component
The
component is completely reusable, it only takes a data array from the official Twitch API and shuffles the results (Some sort of recommended channels "algorithm")

Facial Expression Recognition
The facial expression recognition to emoji is a interesting feature that can let user interact with streamers directly. We have trained a model with more than 2000 images for different emoji categories. The prdiction outcome is in real-time and can be seen in the demo video we provided. The following figure capture some of the facial expression recognition results.




Speech to Text Component
Speech to Text used the Google Cloud Speech Recognition API to transcribe the voice to text and sent it to the chatroom. The website will capture the users voice with MDN Web Audio API, which means it will streaming the user's voice and activate the speech-to-text once receving the real-time speech data in byte format.
Gesture Recognition Component
The gesture recognition using the repository from Real-time Hand Gesture Recognition with 3D CNNs. Here is the demo video of the outcome.
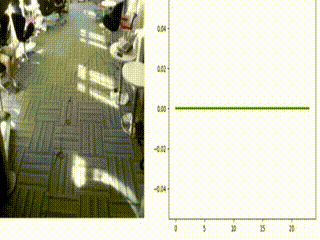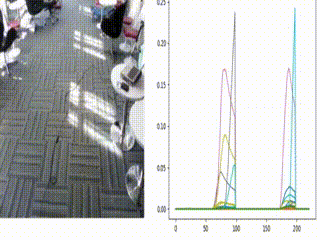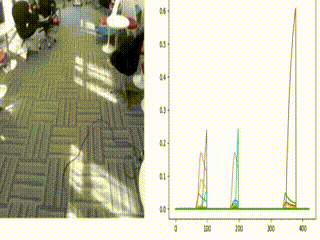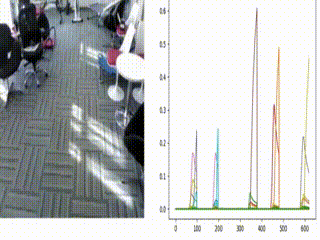
Figure: A real-time simulation of the architecture with input video from EgoGesture dataset (on left side) and real-time (online) classification scores of each gesture (on right side) are shown, where each class is annotated with different color.
Built With:
- Next.JS
- Typescript
- Axios
- Styled-Components
- TwitchAPI
- Deployed to Vercel
Run this locally
To run this project locally, you'll need Node.js installed.
Install dependencies preferably with yarn but you can also use npm install
Create a .env file in the root of the folder based on .env.example.
Run your Next.JS App with yarn dev or npm run dev
Go to localhost:3000 and check out this amazing clone


 2 Feb 14, 2022
2 Feb 14, 2022
 2 Jul 9, 2022
2 Jul 9, 2022
 1.6k Jan 1, 2023
1.6k Jan 1, 2023
 0 Oct 31, 2021
0 Oct 31, 2021
 1 May 13, 2022
1 May 13, 2022
 2 Dec 28, 2021
2 Dec 28, 2021
 2 Feb 25, 2022
2 Feb 25, 2022
 11 May 22, 2022
11 May 22, 2022
 6 Aug 25, 2022
6 Aug 25, 2022
 2 Mar 3, 2022
2 Mar 3, 2022
 108 Dec 29, 2022
108 Dec 29, 2022
 385 Dec 31, 2022
385 Dec 31, 2022
 7.3k Jan 3, 2023
7.3k Jan 3, 2023
 12k Jan 2, 2023
12k Jan 2, 2023
 5 Feb 24, 2022
5 Feb 24, 2022
 225 Dec 31, 2022
225 Dec 31, 2022
 9 Dec 25, 2022
9 Dec 25, 2022
 61 Dec 17, 2022
61 Dec 17, 2022
 7 Mar 25, 2022
7 Mar 25, 2022