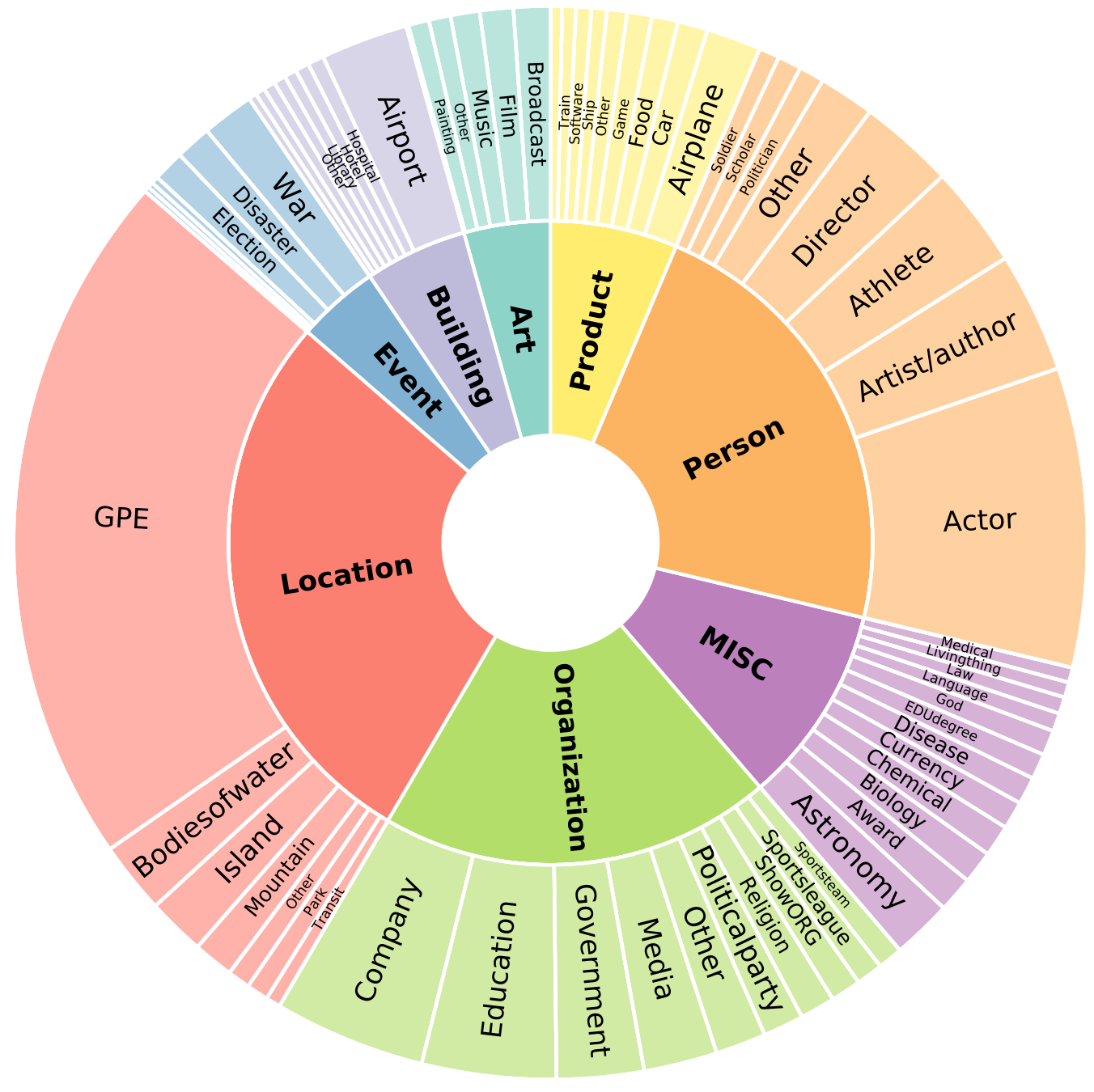
Inside data/episode-data/inter/ I see lot of training, test and dev data. I may be asking few silly questions , please pardon.
I was exploring train_5_5.jsonl. What does train_5_5.jsonl signifies? Does it has to do anything with support and query set?
Here is one example:
I see support has 14 sentences and Query has 15 sentences..
So, this one example mentioned below : support and query is fed into model as single example? Support is used to train the model? Then why Query is used?? I am seeing this training data structure for the first time. Could you give me more insights in lay man terms how training happens?
{
"support":
{"word":
[
["averostra", ",", "or", "``", "bird", "snouts", "''", ",", "is", "a", "clade", "that", "includes", "most", "theropod", "dinosaurs", "that", "have", "a", "promaxillary", "fenestra", "(", "``", "fenestra", "promaxillaris", "``", ")", ",", "an", "extra", "opening", "in", "the", "front", "outer", "side", "of", "the", "maxilla", ",", "the", "bone", "that", "makes", "up", "the", "upper", "jaw", "."],
["since", "that", "time", ",", "the", "squadron", "made", "several", "extended", "indian", "ocean", ",", "mediterranean", "sea", ",", "and", "north", "atlantic", "deployments", "as", "part", "of", "cvw-1", "/", "cv-66", ",", "until", "the", "decommissioning", "of", "uss", "``", "america", "''", "in", "1996", "."],
["the", "alpha-gal", "allergy", "is", "believed", "to", "result", "from", "tick", "bites", "."],
["interaction", "was", "shown", "to", "occur", "with", "the", "dna", "-directed", "rna", "polymerase", "ii", "subunit", ",", "rpb1", ",", "of", "rna", "polymerase", "ii", "during", "both", "mitosis", "and", "interphase", "."],
["he", "is", "also", "responsible", "for", "programming", "on", "diablo", "ii", ",", "the", "development", "of", "the", "battle.net", "game", "server", "network", ",", "and", "the", "quake", "2", "mod", "loki", "'s", "minions", "capture", "the", "flag", "."],
["minix", "was", "first", "released", "in", "1987", ",", "with", "its", "complete", "source", "code", "made", "available", "to", "universities", "for", "study", "in", "courses", "and", "research", "."],
["terminal", "island", "is", "a", "low", "snow-covered", "island", "off", "the", "north", "tip", "of", "alexander", "island", ",", "in", "the", "bellingshausen", "sea", "west", "of", "palmer", "land", ",", "antarctic", "peninsula", "."],
["among", "these", "were", "net/one", ",", "3+", ",", "banyan", "vines", "and", "novell", "'s", "ipx", "/", "spx", "."],
["in", "1933\u20131970", ",", "a", "summer", "camp", "on", "south", "bass", "island", "operated", "for", "episcopal", "and", "anglican", "choristers", "."],
["she", "is", "also", "the", "only", "cam", "ship", "whose", "fighter", "pilot", "died", "in", "action", "after", "his", "aircraft", "was", "launched", "from", "the", "ship", "."],
["the", "department", "of", "social", "welfare", "and", "development", "(", "dswd", ")", "has", "distributed", "relief", "goods", "to", "residents", "of", "boracay", "while", "the", "island", "is", "closed", "to", "tourists", "."],
["``", "rainbow", "``", "was", "scrapped", "in", "1940", "."],
["it", "is", "the", "leading", "firm", "for", "the", "charlotte", "douglas", "international", "airport", "airfield", "expansion", ",", "the", "new", "dallas", "fort", "worth", "international", "airport", "southwest", "end-around", "taxiway", ",", "and", "master", "plan", "updates", "at", "philadelphia", "international", "airport", "and", "san", "antonio", "international", "airport", "."],
["the", "event", "held", "at", "solberg-hunterdon", "airport", "is", "the", "largest", "summertime", "hot", "air", "balloon", "festival", "in", "north", "america", "."]
],
"label":
[
["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "other-biologything", "other-biologything", "O", "O", "other-biologything", "other-biologything", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "other-biologything", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"],
["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "product-ship", "O", "product-ship", "O", "O", "O", "O", "O", "product-ship", "product-ship", "product-ship", "product-ship", "O", "O", "O"],
["O", "O", "O", "O", "O", "O", "O", "O", "other-biologything", "O", "O"],
["O", "O", "O", "O", "O", "O", "O", "other-biologything", "O", "other-biologything", "other-biologything", "other-biologything", "O", "O", "other-biologything", "O", "O", "other-biologything", "other-biologything", "other-biologything", "O", "O", "O", "O", "O", "O"],
["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "product-software", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"],
["product-software", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"],
["location-island", "location-island", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "location-island", "location-island", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "location-island", "location-island", "O"],
["O", "O", "O", "product-software", "O", "product-software", "O", "product-software", "product-software", "O", "product-software", "product-software", "product-software", "O", "product-software", "O"],
["O", "O", "O", "O", "O", "O", "O", "location-island", "location-island", "location-island", "O", "O", "O", "O", "O", "O", "O"],
["O", "O", "O", "O", "O", "product-ship", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"],
["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "location-island", "O", "O", "O", "O", "O", "O", "O", "O"],
["O", "product-ship", "O", "O", "O", "O", "O", "O"],
["O", "O", "O", "O", "O", "O", "O", "building-airport", "building-airport", "building-airport", "building-airport", "O", "O", "O", "O", "O", "building-airport", "building-airport", "building-airport", "building-airport", "building-airport", "O", "O", "O", "O", "O", "O", "O", "O", "O", "building-airport", "building-airport", "building-airport", "O", "building-airport", "building-airport", "building-airport", "building-airport", "O"],
["O", "O", "O", "O", "building-airport", "building-airport", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]
]
},
"query":
{"word":
[
["the", "final", "significant", "change", "in", "the", "life", "of", "the", "coco", "2", "(", "models", "26-3134b", ",", "26-3136b", ",", "and", "26-3127b", ";", "16", "kb", "standard", ",", "16", "kb", "extended", ",", "and", "64", "kb", "extended", "respectively", ")", "was", "to", "use", "the", "enhanced", "vdg", ",", "the", "mc6847t1", ",", "allowing", "lowercase", "characters", "and", "changing", "the", "text", "screen", "border", "color", "."],
["the", "reno-tahoe", "international", "airport", "reno-tahoe", "international", "airport", "(", "formerly", "known", "as", "the", "reno", "cannon", "international", "airport", ")", "is", "the", "other", "major", "airport", "in", "the", "state", "."],
["it", "was", "built", "by", "cole", "palen", "for", "flight", "in", "his", "weekend", "airshows", "as", "early", "as", "1967", "and", "actively", "flown", "(", "mostly", "by", "cole", "palen", ")", "within", "the", "weekend", "airshows", "at", "old", "rhinebeck", "until", "the", "late", "1980s", "."],
["lambert", "land", "is", "bounded", "in", "the", "north", "by", "the", "nioghalvfjerd", "fjord", ",", "in", "the", "east", "by", "the", "greenland", "sea", "and", "in", "the", "south", "by", "the", "zachariae", "isstrom", "."],
["started", "police", "operations", "with", "4", "cessna", "cu", "206g", "officially", "on", "7", "april", "1980", "with", "operations", "focused", "in", "peninsula", "of", "malaysi", "a", "."],
["mysore", "airport", "is", "away", ",", "followed", "by", "kozhikode", "international", "airport", "at", "and", "bengaluru", "international", "airport", "at", "."],
["the", "egg-shaped", "qaqaarissorsuaq", "island", "is", "located", "in", "tasiusaq", "bay", ",", "in", "the", "central", "part", "of", "upernavik", "archipelago", "."],
["where", "they", "inserted", "nife", "hydrogenase", "into", "polypyrrole", "films", "and", "to", "provide", "proper", "contact", "to", "the", "electrode", ",", "there", "were", "redox", "mediators", "entrapped", "into", "the", "film", "."],
["the", "nt-3", "protein", "is", "found", "within", "the", "thymus", ",", "spleen", ",", "intestinal", "epithelium", "but", "its", "role", "in", "the", "function", "of", "each", "organ", "is", "still", "unknown", "."],
["ted", "insists", "that", "he", "will", "have", "a", "better", "chance", "at", "winning", "since", "the", "guest", "judge", ",", "tv", "presenter", "henry", "sellers", ",", "is", "staying", "at", "the", "craggy", "island", "parochial", "house", "."],
["mdm2", "binds", "and", "ubiquitinates", "p53", ",", "facilitating", "it", "for", "degradation", "."],
["neuraminidase", "inhibitors", "for", "human", "neuraminidase", "(", "hneu", ")", "have", "the", "potential", "to", "be", "useful", "drugs", "as", "the", "enzyme", "plays", "a", "role", "in", "several", "signaling", "pathways", "in", "cells", "and", "is", "implicated", "in", "diseases", "such", "as", "diabetes", "and", "cancer", "."], ["at", "it", "was", "long", "enough", "to", "accommodate", "the", "belle", "steamers", "that", "carried", "trippers", "along", "the", "coast", "at", "that", "time", "."],
["these", "guerrilla", "sub", "missions", "originated", "at", "brisbane", "'s", ",", "capricorn", "wharf", "or", "mios", "woendi", "."],
["because", "it", "was", "originally", "an", "island", "well", "within", "lake", "texcoco", ",", "iztacalco", "was", "settled", "by", "humans", "later", "than", "the", "rest", "of", "the", "valley", "of", "mexico", "."],
["the", "nordic", "countries", "had", "developed", "the", "skerry", "cruiser", "classes", "and", "the", "international", "rule", "classes", "had", "adopted", "in", "1919", "a", "new", "edition", "of", "the", "rule", "which", "was", "not", "yet", "implemented", "in", "the", "countries", "."]
],
"label": [["O", "O", "O", "O", "O", "O", "O", "O", "O", "product-software", "product-software", "O", "O", "product-software", "O", "product-software", "O", "O", "product-software", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "product-software", "O", "O", "product-software", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["building-airport", "building-airport", "building-airport", "building-airport", "building-airport", "building-airport", "building-airport", "O", "O", "O", "O", "building-airport", "building-airport", "building-airport", "building-airport", "building-airport", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "building-airport", "building-airport", "O", "O", "O", "O", "O"], ["location-island", "location-island", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "location-island", "location-island", "location-island", "O", "O"], ["building-airport", "building-airport", "O", "O", "O", "O", "O", "building-airport", "building-airport", "building-airport", "O", "O", "building-airport", "building-airport", "building-airport", "O", "O"], ["O", "O", "location-island", "location-island", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["O", "O", "O", "other-biologything", "other-biologything", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["O", "other-biologything", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "location-island", "location-island", "O", "O", "O"], ["other-biologything", "O", "O", "O", "other-biologything", "O", "O", "O", "O", "O", "O"], ["other-biologything", "other-biologything", "other-biologything", "other-biologything", "other-biologything", "O", "other-biologything", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["O", "O", "O", "O", "O", "O", "O", "O", "product-ship", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["O", "O", "O", "O", "O", "O", "product-ship", "product-ship", "O", "product-ship", "product-ship", "O", "product-ship", "product-ship", "O"], ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "location-island", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"], ["O", "O", "O", "O", "O", "O", "product-ship", "product-ship", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]]},
"types": ["other-biologything", "building-airport", "location-island", "product-ship", "product-software"]}












 195 Dec 29, 2022
195 Dec 29, 2022
 220 Dec 31, 2022
220 Dec 31, 2022
 72 Dec 10, 2022
72 Dec 10, 2022
 11 Dec 5, 2022
11 Dec 5, 2022
 80 Dec 8, 2022
80 Dec 8, 2022
 64 Dec 12, 2022
64 Dec 12, 2022
 4 Dec 17, 2021
4 Dec 17, 2021
 36 Dec 2, 2022
36 Dec 2, 2022
 177 Jan 5, 2023
177 Jan 5, 2023
 76 Dec 21, 2022
76 Dec 21, 2022
 17 Nov 22, 2022
17 Nov 22, 2022
 388 Dec 18, 2022
388 Dec 18, 2022
 138 Dec 12, 2022
138 Dec 12, 2022
 181 Dec 27, 2022
181 Dec 27, 2022
 224 Dec 28, 2022
224 Dec 28, 2022
 399 Jan 8, 2023
399 Jan 8, 2023
 233 Dec 29, 2022
233 Dec 29, 2022
 47 Jan 3, 2023
47 Jan 3, 2023
 97 Dec 23, 2022
97 Dec 23, 2022