Laporan Proyek Machine Learning - Azhar Rizki Zulma
Project Overview
Domain proyek yang dipilih dalam proyek machine learning ini adalah mengenai hiburan dengan judul proyek "Movie Recommendation System".
Latar Belakang
Hiburan merupakan kebutuhan terbelakang manusia, mengapa demikian? Karena hiburan bukanlah sebuah kebutuhan pokok yang wajib dipenuhi oleh setiap manusia, begitulah pikir orang terdahulu. Seiring berjalannya waktu orang-orang mulai menganggap hiburan merupakan sebuah kebutuhan yang wajib dipenuhi oleh setiap orang. Terutama semenjak memasuki abad 21, di mana terjadi perkembangan yang pesat pada dunia hiburan. Khususnya pada dunia pertelevisian dan film. Dari era televisi hitam putih, hingga menginjak ke era warna-warni. Bahkan mulai bermunculan televisi hologram dan layanan streaming yang disesuaikan dengan kesukaan pengguna. Penggunaan layanan streaming saat ini meningkat cukup pesat. Dan baru-baru ini pun semakin meningkat akibat pandemi yang berkepanjangan ini.
Dari latar belakang itulah penulis mengambil topik ini sebagai domain proyek machine learning yang penulis kerjakan. Selain dari latar belakang diatas, tujuan lain dibuatnya proyek machine learning ini ialah membuat sebuah model untuk proyek aplikasi yang sedang penulis kembangkan. Diharapkan model ini nantinya akan berguna pada aplikasi yang penulis kembangkan dan mendapatkan hasil keluaran berupa aplikasi yang berkualitas sesuai dengan yang penulis harapkan.
Business Understanding
Sistem rekomendasi adalah suatu aplikasi yang digunakan untuk memberikan rekomendasi dalam membuat suatu keputusan yang diinginkan pengguna. Untuk meningkatkan user experience dalam menemukan judul film yang menarik dan yang sesuai dengan yang pengguna inginkan, maka sistem rekomendasi adalah pilihan yang tepat untuk diterapkan. Dengan adanya sistem rekomendasi, user experience tentu akan lebih baik karena pengguna bisa mendapatkan rekomendasi judul film yang ingin diharapkan.
Problem Statement
Berdasarkan pada latar belakang di atas, permasalahan yang dapat diselesaikan pada proyek ini adalah sebagai berikut:
- Bagaimana cara melakukan pengolahan data yang baik sehingga dapat digunakan untuk membuat model sistem rekomendasi yang baik?
- Bagaimana cara membangun model machine learning untuk merekomendasikan sebuah film yang mungkin disukai pengguna?
Goal
Tujuan dibuatnya proyek ini adalah sebagai berikut:
- Melakukan pengolahan data yang baik agar dapat digunakan dalam membangun model sistem rekomendasi yang baik.
- Membangun model machine learning untuk merekomendasikan sebuah film yang kemungkinan disukai pengguna.
Solution
Untuk menyelesaikan masalah ini, penulis akan menggunakan 2 solusi algoritma yaitu content-based filtering dan collaborative filtering. Berikut adalah penjelasan teknik-teknik yang akan digunakan untuk masalah ini:
- Content-Based Filtering merupakan cara untuk memberi rekomendasi bedasarkan genre atau fitur pada item yang disukai oleh pengguna. Content-based filtering mempelajari profil minat pengguna baru berdasarkan data dari objek yang telah dinilai pengguna.
- Collaborative Filtering merupakan cara untuk memberi rekomendasi bedasarkan penilaian komunitas pengguna atau biasa disebut dengan rating. Collaborative filtering tidak memerlukan atribut untuk setiap itemnya seperti pada sistem berbasis konten.
Data Understanding
-
Informasi Dataset
Dataset yang digunakan pada proyek ini yaitu dataset film lengkap dengan genre dan rating, informasi lebih lanjut mengenai dataset tersebut dapat lihat pada tabel berikut:Jenis Keterangan Sumber Dataset: Kaggle Dataset Owner Sunil Gautam Lisensi - Kategori Movies & TV Shows Usability 5.3 Jenis dan Ukuran Berkas ZIP (3.3 MB) Jumlah File Dataset 4 File (CSV)
Berikut ini file dataset- links.csv
- ratings.csv
- movies.csv
- tags.csv
Pada proyek ini penulis hanya menggunakan 2 file dataset yaitu:
-
movies.csv
Jumlah Data 9742, dan memiliki 3 kolom
Untuk penjelasan mengenai variabel-variabel pada dataset dapat dilihat pada poin-poin berikut ini:movieId: ID dari film
movieId memiliki 9742 data unik.title: Judul dari film
title memiliki 9737 data unik.genres: Genre dari film
genres memiliki 951 data unik.
-
ratings.csv
Jumlah Data 100836, dan memiliki 4 kolom
Untuk penjelasan mengenai variabel-variabel pada dataset dapat dilihat pada poin-poin berikut ini:userId: ID pengguna pemberi rating
userId memiliki 610 data unik.movieId: ID film yang di rating
movieId memiliki 9724 data unik.rating: Rating dari film
rating memiliki 10 data unik. dengan range 0 - 5 dan skala 0.5timestamp= Waktu rating terekam
timestamp memiliki 85043 data unik.
-
Sebaran atau Distribusi Data pada Fitur yang Digunakan
Berikut merupakan visualisasi data yang menunjukkan sebaran/distribusi data pada beberapa variabel yang akan penulis gunakan nanti:
Distribusi tahun rilis film:

Dapat dilihat pada grafik di atas rata-rata rilis sebuah film berkisar antara tahun 1990-2000 ke atas, distribusi terbanyak terjadi di atas tahun 2000, di mana distribusi film cenderung mengalami kenaikan secara signifikan setiap berjalannya waktu.
Distribusi total jumlah genre:
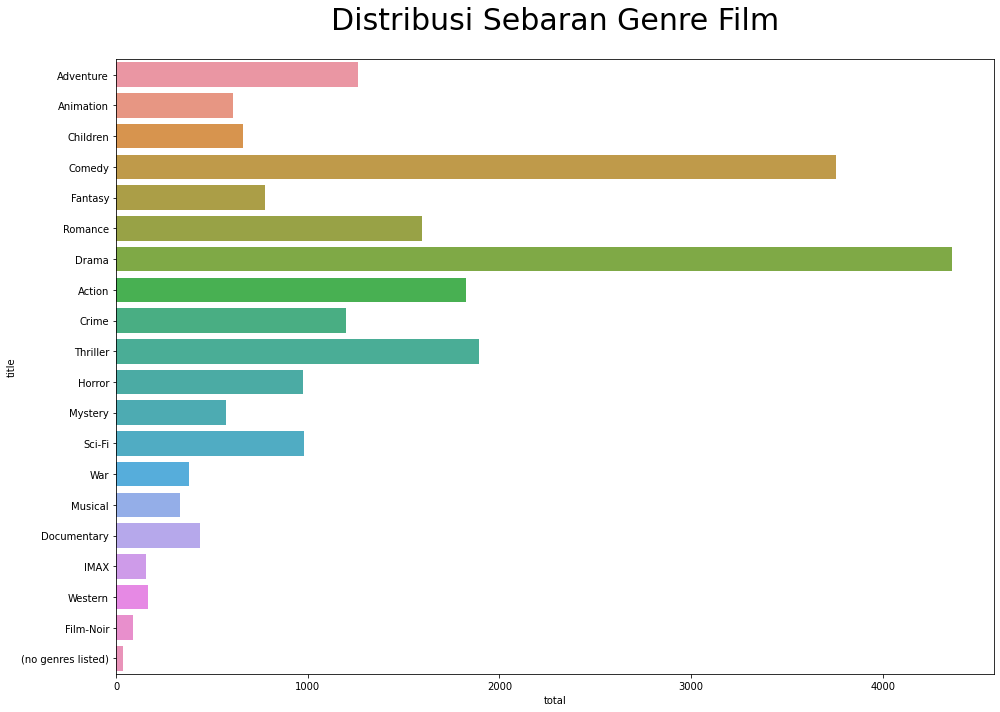
Terlihat pada gambar di atas ada 20 kategori atau genre di dalam data ini. genre
Dramayang paling banyak dan diikuti oleh genreComedylalu ada beberapa film yang tidak memiliki genreno genres listed10 film yang memiliki rating tertinggi:
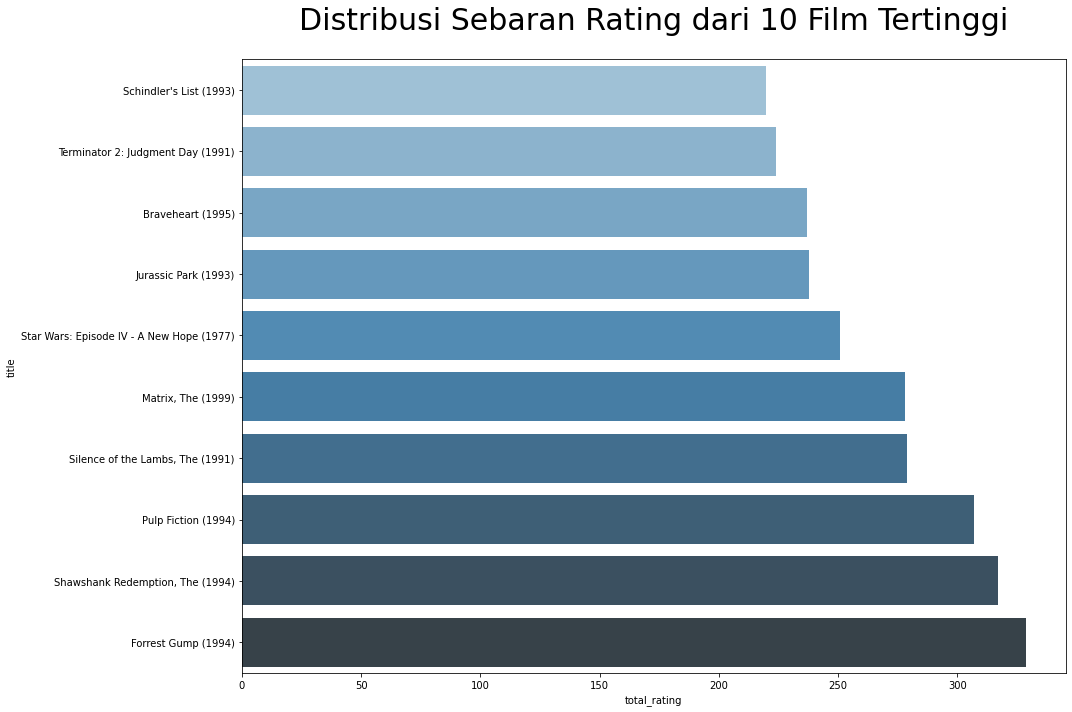
Terlihat pada grafik, bahwa film yang memiliki rating tertinggi adalah Forrest Gump yang rilis pada tahun 1994

Data Preparation
Data preparation diperlukan untuk mempersiapkan data agar ketika nanti dilakukan proses pengembangan model diharapkan akurasi model akan semakin baik dan meminimalisir terjadinya bias pada data. Berikut ini merupakan tahapan-tahapan dalam melakukan pra-pemrosesan data:
-
Melakukan Penanganan Missing Value
Penanganan yang penulis lakukan pada missing value yaitu dengan melakukan drop data. Tetapi karena dataset yang digunakan cukup bersih, missing value hanya terdapat ketika proses penggabungan dataset. -
Melakukan Sorting Data Rating berdasarkan ID Pengguna
Melakukan pengurutan data rating berdasarkan ID Pengguna agar mempermudah dalam melakukan penghapusan data duplikat nantinya. -
Menghapus Data Duplikat
Melakukan penghapusan data duplikat agar tidak terjadi bias pada data nantinya. -
Melakukan penggabungan Data
Melakukan penggabungan data yang sudah diolah sebelumnya untuk membangun model. lalu menghapus data yang memiliki missing value pada variabel genre dan melihat jumlah data setelah digabungkan, terlihat data memiliki 100830 baris dengan 5 kolom. -
Melakukan Normalisasi Nilai Rating
Untuk menghasilkan rekomendasi yang sesuai dan akurat maka pada tahap ini diperlukan sebuah normalisasi pada data nilai rating dengan menggunakan formula MinMax pada data rating sebelum memasuki tahap modelling. -
Melakukan Splitting Dataset
Untuk melatih model maka penulis perlu melakukan pembagian dataset latih dan juga dataset validasi, untuk dataset latih penulis berikan 80% dari total keseluruhan jumlah data sedangkan dataset validasi sebesar 20% dari keseluruhan data. Hal ini diperlukan untuk pengembangan pada model Collaborative Filtering nantinya.
Modeling and Result
Pada proyek ini, Proses modeling dalam proyek ini menggunakan metode Neural Network dan Cosine Similarity. Model Deep Learning akan penulis gunakan untuk Sistem Rekomendasi berbasis Collaborative Filtering yang mana model ini akan menghasilkan rekomendasi untuk satu pengguna. Cosine Similarity akan penulis gunakan untuk Sistem Rekomendasi berbasis Content-Based Filtering yang akan menghitung kemiripan antara satu film dengan lainnya berdasarkan fitur yang terdapat pada satu film. Berikut penjelasan tahapannya:
Content Based Filtering
Pada modeling Content Based Filtering, langkah pertama yang dilakukan ialah penulis menggunakan TF-IDF Vectorizer untuk menemukan representasi fitur penting dari setiap genre film. Fungsi yang penulis gunakan adalah tfidfvectorizer() dari library sklearn. Selanjutnya penulis melakukan fit dan transformasi ke dalam bentuk matriks. Keluarannya adalah matriks berukuran (9737, 23). Nilai 9737 merupakan ukuran data dan 23 merupakan matriks genre film.
Untuk menghitung derajat kesamaan (similarity degree) antar movie, penulis menggunakan teknik cosine similarity dengan fungsi cosine_similarity dari library sklearn. Berikut dibawah ini adalah rumusnya:

Langkah selanjutnya yaitu menggunakan argpartition untuk mengambil sejumlah nilai k tertinggi dari similarity data kemudian mengambil data dari bobot (tingkat kesamaan) tertinggi ke terendah. Kemudian menguji akurasi dari sistem rekomendasi ini untuk menemukan rekomendasi movies yang mirip dari film yang ingin dicari.
-
Kelebihan
- Semakin banyak informasi yang diberikan pengguna, semakin baik akurasi sistem rekomendasi.
-
Kekurangan
- Hanya dapat digunakan untuk fitur yang sesuai, seperti film, dan buku.
- Tidak mampu menentukan profil dari user baru.
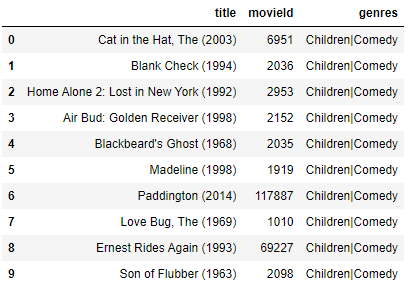
Berikut ini adalah konten yang dijadikan referensi untuk menentukan 10 rekomendasi film tertinggi yang memiliki kesamaan genre yang sama:

Terlihat pada tabel diatas bahwasannya saya akan menguji coba model berdasarkan judul film "Daddy Day Care (2003)" dengan genre Children & Comedy.
Berikut ini adalah hasil rekomendasi tertinggi dari model Content Based Filtering berdasarkan referensi film diatas:
Collaborative Filtering
Pada modeling Collaborative Filtering penulis menggunakan data hasil gabungan dari dua datasets yaitu movies.csv & ratings.csv. Langkah pertama adalah melakukan encode data userId & movieId setelah di encode lakukan mapping ke dalam data yang digunakan dan juga mengubah nilai rating menjadi float. Selanjutnya ialah membagi data untuk training sebesar 80% dan validasi sebesar 20%.
Lakukan proses embedding terhadap data film dan pengguna. Lalu lakukan operasi perkalian dot product antara embedding pengguna dan film. Selain itu, penulis juga menambahkan bias untuk setiap pengguna dan film. Skor kecocokan ditetapkan dalam skala [0,1] dengan fungsi aktivasi sigmoid. Untuk mendapatkan rekomendasi film, penulis mengambil sampel user secara acak dan mendefinisikan variabel movie_not_watched yang merupakan daftar film yang belum pernah ditonton oleh pengguna.
-
Kelebihan
- Tidak memerlukan atribut untuk setiap itemnya.
- Dapat membuat rekomendasi tanpa harus selalu menggunakan dataset yang lengkap.
- Unggul dari segi kecepatan dan skalabilitas.
- Rekomendasi tetap akan berkerja dalam keadaan dimana konten sulit dianalisi sekalipun
-
Kekurangan
- Membutuhkan parameter rating, sehingga jika ada item baru sistem tidak akan merekomendasikan item tersebut.
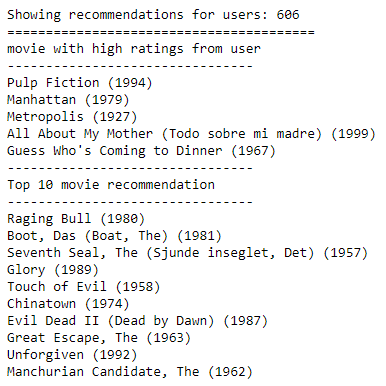
Berikut ini adalah hasil rekomendasi film tertinggi terhadap user 606:
Evaluation
Evaluasi yang akan penulis lakukan disini yaitu evaluasi dengan Mean Absolute Error (MAE) dan Root Mean Squared Error (RMSE) pada Collaborative Filtering dan Precision Content Based Filtering
Content Based Filtering
Pada evaluasi model ini penulis menggunakan metrik precision content based filtering untuk menghitung precision model sistem telah dibuat sebelumnya. Berikut ini adalah hasil analisisnya:
Precision Metric Formula:
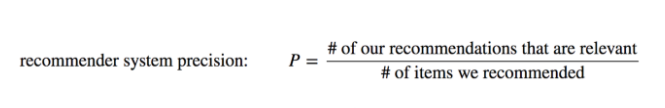
Precision Metric Test:
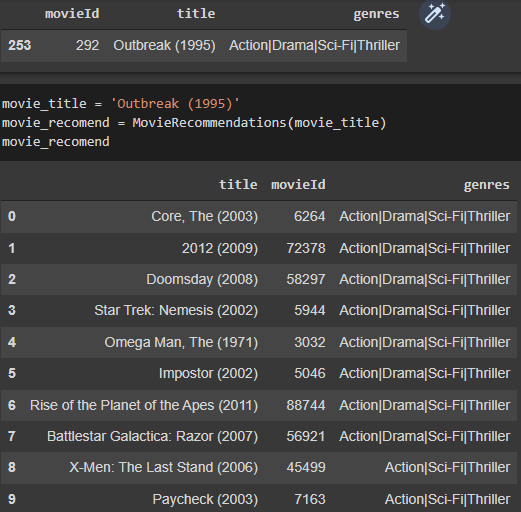
Langkah pertama adalah melakukan pengecekan data film berdasarkan title. Dapat dilihat bahwa judul film Outbreak (1995) memiliki 4 genre yaitu Action, Drama, Sci-Fi, dan Thriller. Lalu dari hasil rekomendasi di atas, diketahui bahwa Outbreak (1995) memiliki 4 genre. Dari 10 item yang direkomendasikan, 8 item memiliki kategori 4 genre yang sama (similar). Artinya, precision sistem kita sebesar 8/10 atau sebesar 80%.
Collaborative Filtering
| Mean Absolute Error (MAE) | Root Mean Squared Error (RMSE) |
|---|---|
| Mengukur besarnya rata-rata kesalahan dalam serangkaian prediksi yang sudah dilatih kepada data yang akan dites, tanpa mempertimbangkan arahnya. Semakin rendah nilai MAE (Mean Absolute Error) maka semakin baik dan akurat model yang dibuat. | Adalah aturan penilaian kuadrat yang juga mengukur besarnya rata-rata kesalahan. Sama seperti MAE, semakin rendahnya nilai root mean square error juga menandakan semakin baik model tersebut dalam melakukan prediksi. |
| Formula Mean Absolute Error (MAE) | Formula Root Mean Squared Error (RMSE) |
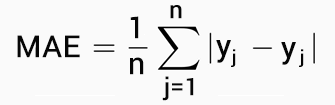 |
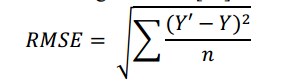 |
| Visualisasi Mean Absolute Error (MAE) | Visualisasi Root Mean Squared Error (RMSE) |
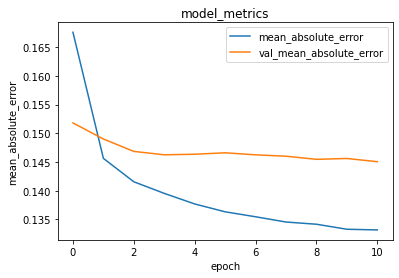 |
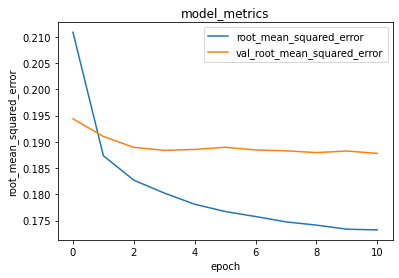 |
| Berdasarkan hasil fitting nilai konvergen metrik MAE berada sedikit dibawah 0.135 untuk training dan sedikit diatas 0.1450 untuk validasi. | Berdasarkan hasil fitting nilai konvergen metrik RMSE berada sedikit diatas 0.170 untuk training dan sedikit dibawah 0.190 untuk validasi. |
Untuk menghasilkan nilai yang konvergen proses fitting memerlukan 15 epoch. Dari hasil perhitungan kedua metrik diatas dapat disimpulkan bahwa model ini memiliki tingkat eror di bawah 20%.
 4.2k Jan 1, 2023
4.2k Jan 1, 2023
 11.6k Jan 2, 2023
11.6k Jan 2, 2023
 4.2k Dec 29, 2022
4.2k Dec 29, 2022
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
 663 Dec 31, 2022
663 Dec 31, 2022
 3.7k Jan 7, 2023
3.7k Jan 7, 2023
 2.3k Jan 5, 2023
2.3k Jan 5, 2023
 6.7k Jan 7, 2023
6.7k Jan 7, 2023
 1.4k Jan 6, 2023
1.4k Jan 6, 2023

 8.1k Dec 30, 2022
8.1k Dec 30, 2022
 19 Oct 3, 2022
19 Oct 3, 2022
 366 Jan 3, 2023
366 Jan 3, 2023
 152 Jan 7, 2023
152 Jan 7, 2023
 5.7k Dec 30, 2022
5.7k Dec 30, 2022
 3.8k Jan 9, 2023
3.8k Jan 9, 2023
 2 Aug 23, 2022
2 Aug 23, 2022
 0 Jan 31, 2022
0 Jan 31, 2022
 3k Jan 8, 2023
3k Jan 8, 2023
 3.1k Dec 28, 2022
3.1k Dec 28, 2022