A Straightforward Framework For Video Retrieval Using CLIP
This repository contains the basic code for feature extraction and replication of results.
this work has been submitted to the Mexican Conference of Pattern Recognition (MCPR 2021).
If you consider this work useful please cite as:
@misc{portilloquintero2021straightforward,
title={A Straightforward Framework For Video Retrieval Using CLIP},
author={Jesús Andrés Portillo-Quintero and José Carlos Ortiz-Bayliss and Hugo Terashima-Marín},
year={2021},
eprint={2102.12443},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
![[2021 MultiMedia] CONQUER: Contextual Query-aware Ranking for Video Corpus Moment Retrieval](https://github.com/houzhijian/CONQUER/raw/master/figures/problem_definition.png)
 23 Dec 26, 2022
23 Dec 26, 2022

 56 Dec 22, 2022
56 Dec 22, 2022
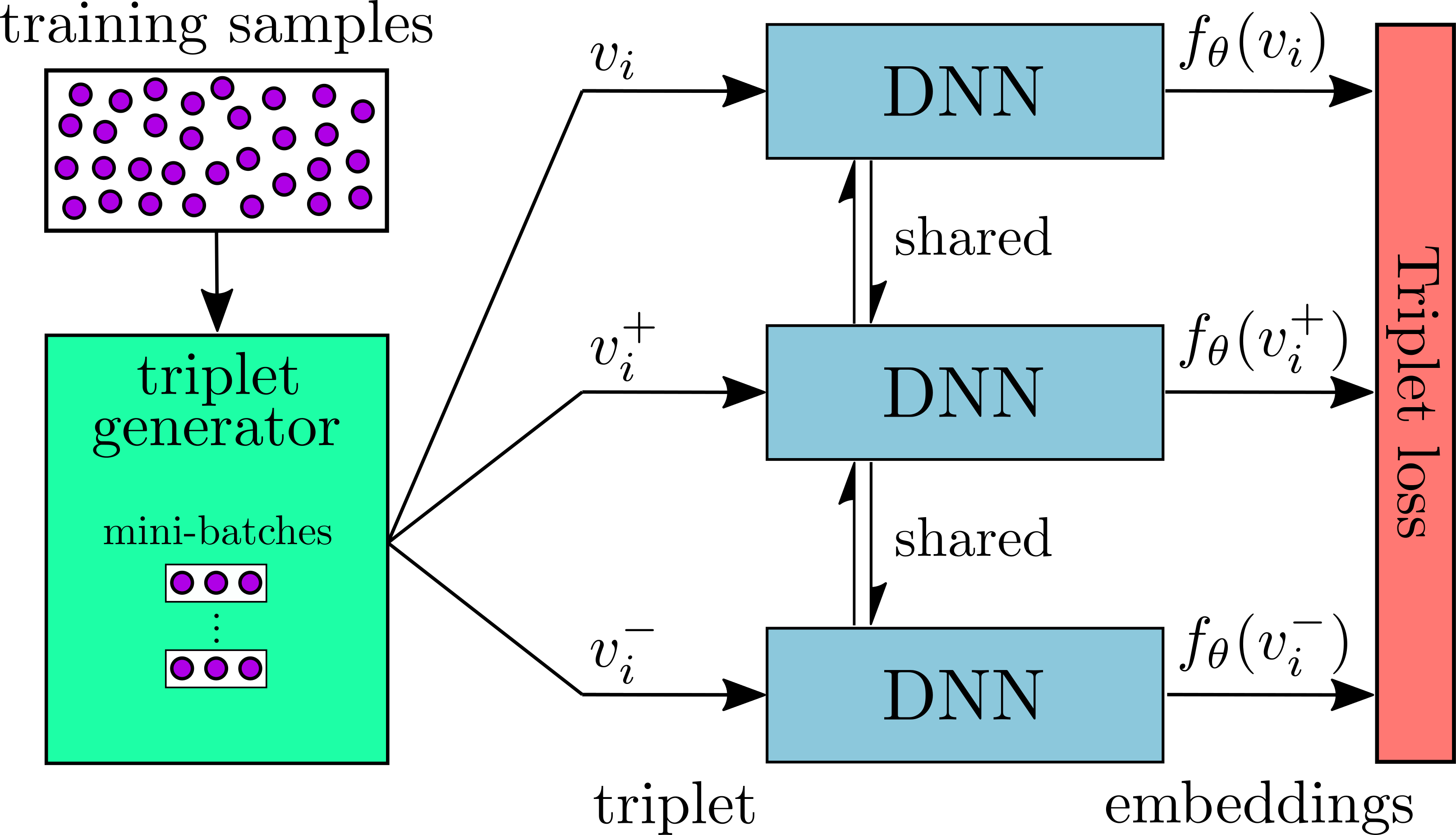
 2 Jan 24, 2022
2 Jan 24, 2022
![[arXiv22] Disentangled Representation Learning for Text-Video Retrieval](https://github.com/foolwood/DRL/raw/main/demo/pipeline.png)
 49 Dec 18, 2022
49 Dec 18, 2022
 84 Jan 4, 2023
84 Jan 4, 2023

 1 Jan 23, 2022
1 Jan 23, 2022

 187 Dec 24, 2022
187 Dec 24, 2022

 4.4k Jan 3, 2023
4.4k Jan 3, 2023
 172 Dec 22, 2022
172 Dec 22, 2022


 191 Dec 31, 2022
191 Dec 31, 2022
 75 Dec 29, 2022
75 Dec 29, 2022
 47 Dec 16, 2022
47 Dec 16, 2022
 36 Oct 18, 2022
36 Oct 18, 2022
 163 Dec 26, 2022
163 Dec 26, 2022
 2.3k Jan 4, 2023
2.3k Jan 4, 2023
 23 Oct 26, 2022
23 Oct 26, 2022
 75 Oct 21, 2021
75 Oct 21, 2021
 225 Dec 25, 2022
225 Dec 25, 2022