geobeam adds GIS capabilities to your Apache Beam pipelines.
What does geobeam do?
geobeam enables you to ingest and analyze massive amounts of geospatial data in parallel using Dataflow. geobeam provides a set of FileBasedSource classes that make it easy to read, process, and write geospatial data, and provides a set of helpful Apache Beam transforms and utilities that make it easier to process GIS data in your Dataflow pipelines.
See the Full Documentation for complete API specification.
Requirements
- Apache Beam 2.27+
- Python 3.7+
Note: Make sure the Python version used to run the pipeline matches the version in the built container.
Supported input types
| File format | Data type | Geobeam class |
|---|---|---|
tiff |
raster | GeotiffSource |
shp |
vector | ShapefileSource |
gdb |
vector | GeodatabaseSource |
Included libraries
geobeam includes several python modules that allow you to perform a wide variety of operations and analyses on your geospatial data.
| Module | Version | Description |
|---|---|---|
| gdal | 3.2.1 | python bindings for GDAL |
| rasterio | 1.1.8 | reads and writes geospatial raster data |
| fiona | 1.8.18 | reads and writes geospatial vector data |
| shapely | 1.7.1 | manipulation and analysis of geometric objects in the cartesian plane |
How to Use
1. Install the module
pip install geobeam
2. Write your pipeline
Write a normal Apache Beam pipeline using one of geobeams file sources. See geobeam/examples for inspiration.
3. Run
Run locally
python -m geobeam.examples.geotiff_dem \
--gcs_url gs://geobeam/examples/dem-clipped-test.tif \
--dataset=examples \
--table=dem \
--band_column=elev \
--centroid_only=true \
--runner=DirectRunner \
--temp_location <temp gs://> \
--project <project_id>
You can also run "locally" in Cloud Shell using the py-37 container variants
Note: Some of the provided examples may take a very long time to run locally...
Run in Dataflow
Write a Dockerfile
This will run in Dataflow as a custom container based on the dataflow-geobeam/base image. See [geobeam/examples/Dockerfile] for an example that installed the latest geobeam from source.
FROM gcr.io/dataflow-geobeam/base
# FROM gcr.io/dataflow-geobeam/base-py37
RUN pip install geobeam
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
# build locally with docker
docker build -t gcr.io/<project_id>/example
docker push gcr.io/<project_id>/example
# or build with Cloud Build
gcloud builds submit --tag gcr.io/<project_id>/<name> --timeout=3600s --machine-type=n1-highcpu-8
Start the Dataflow job
Note on Python versions
If you are starting a Dataflow job on a machine running Python 3.7, you must use the images suffixed with
py-37. (Cloud Shell runs Python 3.7 by default, as of Feb 2021). A separate version of the base image is built for Python 3.7, and is available atgcr.io/dataflow-geobeam/base-py37. The Python 3.7-compatible examples image is similarly-namedgcr.io/dataflow-geobeam/example-py37
# run the geotiff_soilgrid example in dataflow
python -m geobeam.examples.geotiff_soilgrid \
--gcs_url gs://geobeam/examples/AWCh3_M_sl1_250m_ll.tif \
--dataset=examples \
--table=soilgrid \
--band_column=h3 \
--runner=DataflowRunner \
--worker_harness_container_image=gcr.io/dataflow-geobeam/example \
--experiment=use_runner_v2 \
--temp_location=<temp bucket> \
--service_account_email <service account> \
--region us-central1 \
--max_num_workers 2 \
--machine_type c2-standard-30 \
--merge_blocks 64
Examples
Polygonize Raster
def run(options):
from geobeam.io import GeotiffSource
from geobeam.fn import format_record
with beam.Pipeline(options) as p:
(p | 'ReadRaster' >> beam.io.Read(GeotiffSource(gcs_url))
| 'FormatRecord' >> beam.Map(format_record, 'elev', 'float')
| 'WriteToBigquery' >> beam.io.WriteToBigQuery('geo.dem'))
Validate and Simplify Shapefile
def run(options):
from geobeam.io import ShapefileSource
from geobeam.fn import make_valid, filter_invalid, format_record
with beam.Pipeline(options) as p:
(p | 'ReadShapefile' >> beam.io.Read(ShapefileSource(gcs_url))
| 'Validate' >> beam.Map(make_valid)
| 'FilterInvalid' >> beam.Filter(filter_invalid)
| 'FormatRecord' >> beam.Map(format_record)
| 'WriteToBigquery' >> beam.io.WriteToBigQuery('geo.parcel'))
See geobeam/examples/ for complete examples.
A number of example pipelines are available in the geobeam/examples/ folder. To run them in your Google Cloud project, run the included terraform file to set up the Bigquery dataset and tables used by the example pipelines.
Open up Bigquery GeoViz to visualize your data.
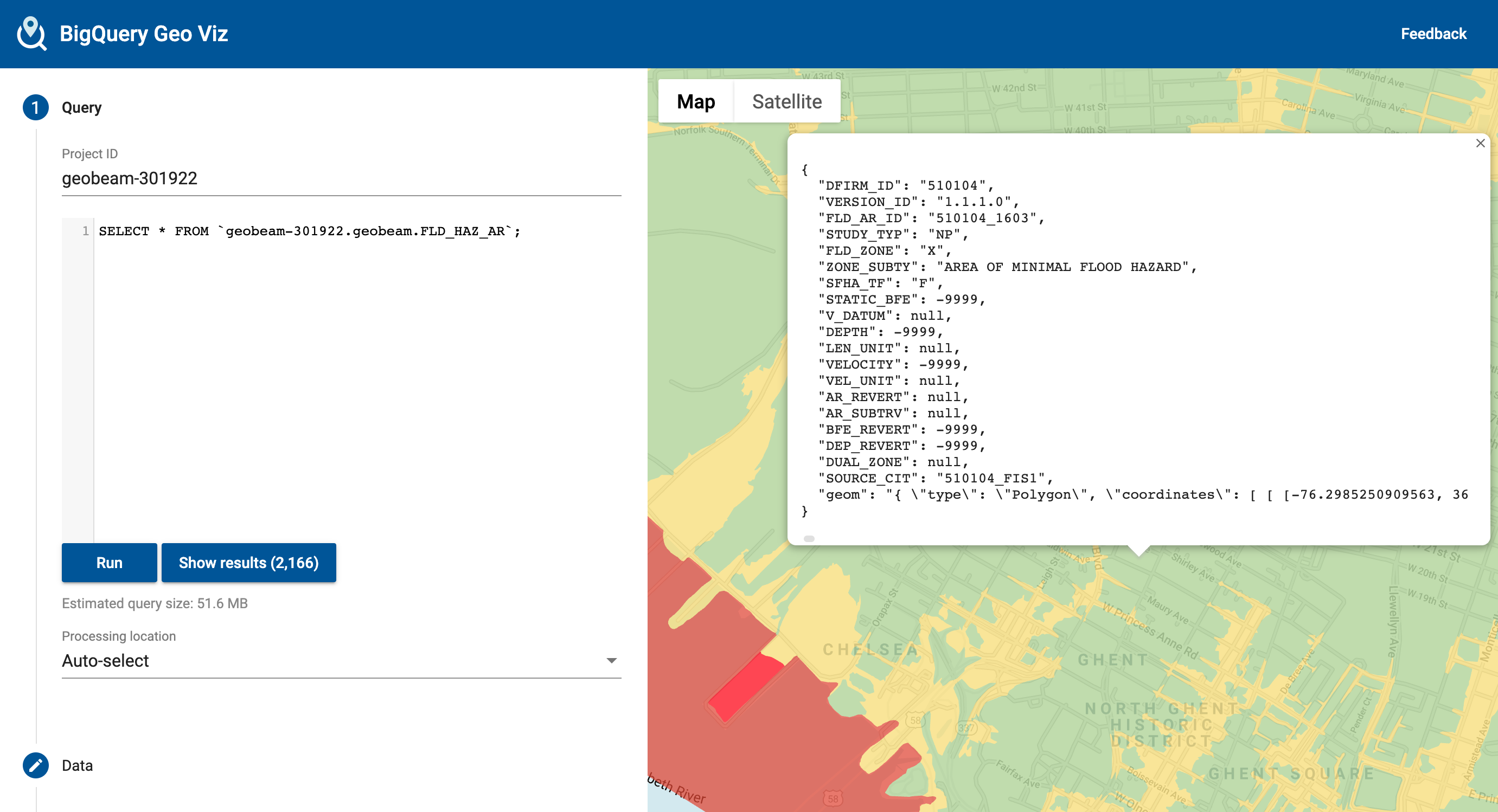
Shapefile Example
The National Flood Hazard Layer loaded from a shapefile. Example pipeline at geobeam/examples/shapefile_nfhl.py
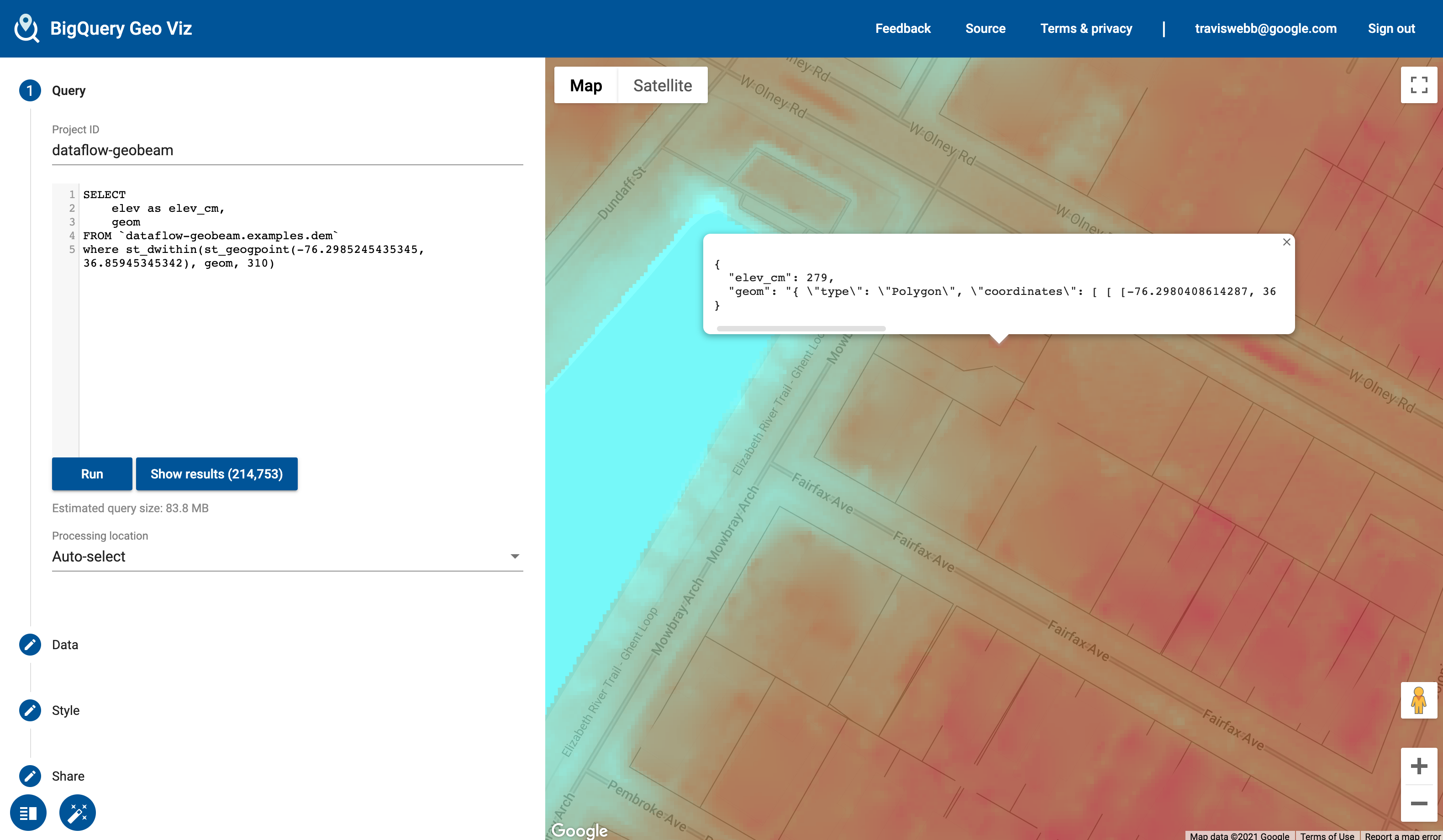
Raster Example
The Digital Elevation Model is a high-resolution model of elevation measurements at 1-meter resolution. (Values converted to centimeters). Example pipeline: geobeam/examples/geotiff_dem.py.
Included Transforms
The geobeam.fn module includes several Beam Transforms that you can use in your pipelines.
| Module | Description |
|---|---|
geobeam.fn.make_valid |
Attempt to make all geometries valid. |
geobeam.fn.filter_invalid |
Filter out invalid geometries that cannot be made valid |
geobeam.fn.format_record |
Format the (props, geom) tuple received from a FileSource into a dict that can be inserted into the destination table |
Execution parameters
Each FileSource accepts several parameters that you can use to configure how your data is loaded and processed. These can be parsed as pipeline arguments and passed into the respective FileSources as seen in the examples pipelines.
| Parameter | Input type | Description | Default | Required? |
|---|---|---|---|---|
skip_reproject |
All | True to skip reprojection during read | False |
No |
in_epsg |
All | An EPSG integer to override the input source CRS to reproject from | No | |
band_number |
Raster | The raster band to read from | 1 |
No |
include_nodata |
Raster | True to include nodata values |
False |
No |
centroid_only |
Raster | True to only read pixel centroids | False |
No |
merge_blocks |
Raster | Number of block windows to combine during read. Larger values will generate larger, better-connected polygons. | No | |
layer_name |
Vector | Name of layer to read | Yes | |
gdb_name |
Vector | Name of geodatabase directory in a gdb zip archive | Yes, for GDB files |
License
This is not an officially supported Google product, though support will be provided on a best-effort basis.
Copyright 2021 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.












 4k Jan 8, 2023
4k Jan 8, 2023
 85 Aug 30, 2022
85 Aug 30, 2022
 481 Dec 29, 2022
481 Dec 29, 2022
 1 Dec 8, 2021
1 Dec 8, 2021
 7 Oct 21, 2022
7 Oct 21, 2022
 3 May 6, 2022
3 May 6, 2022
 1 Feb 7, 2022
1 Feb 7, 2022
 1.2k Jan 3, 2023
1.2k Jan 3, 2023
 765 Jan 6, 2023
765 Jan 6, 2023
 3.1k Jan 3, 2023
3.1k Jan 3, 2023
 832 Dec 31, 2022
832 Dec 31, 2022
 1.9k Jan 7, 2023
1.9k Jan 7, 2023
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
 837 Dec 28, 2022
837 Dec 28, 2022
 976 Dec 11, 2022
976 Dec 11, 2022
 2.4k Dec 30, 2022
2.4k Dec 30, 2022