Introduction
A command line tool that can convert Day One data into markdown files.
Features
Following metadata are supported:
- Creation Date
- Modification Date
- Device Model
- Operating System
- Day One UUID
- Time Zone
- Starred
- All Day
- Pinned
- Device
- Hashtags
- Activity
- Walking Steps
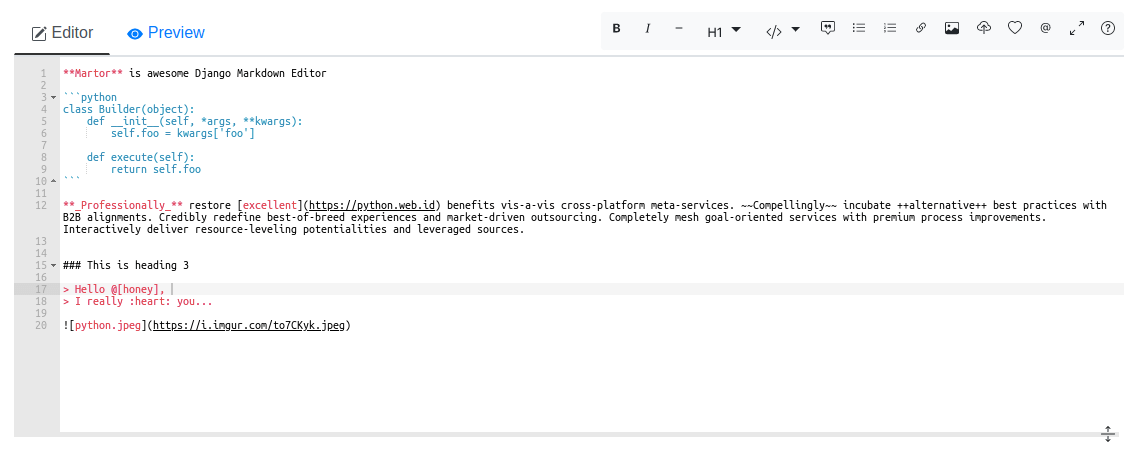
Example preview:

These are implemented through css and html tags, so are not able to be previewed on GitHub.
Audios and videos are also supported. Some markdown editor might not be able to preview badges, audios, and videos. In this case, converting to HTML is recommended. As long as the browser supports
and
tags, those media would be rendered.
Before Start
Export data from Day One
The first step is to export data from Day One.
Goto Settings -> Import/Export -> Export Day One JSON (.zip) and you should click on include media files.
Wait for couple of seconds (hours, I hate the iCloud service in mainland China), and you would get a zip file.
Check Integrity
Note that, the data you dumped might be damaged, and some files may be missing. To continue, it is recommended to use the tool provided to check data integrity.
$ python3 .\resource_checker.py check --help
Usage: resource_checker.py check [OPTIONS] DIRECTORY
Check data integrity. Only photos, audios, and videos are supported.
ARGUMENTS:
* DIRECTORY: path of unzipped Day One data
Options:
--help Show this message and exit.
If some files are missing, don't worry. The tool will tell you the md5 hash of the file, and you can search through the JSON data and find in which entry the data is located. For example, if you've found ad7f659d748c1a41c753907c6946eb03 is located in the following data,
{
"creationDate" : "2020-10-01T13:21:01Z",
"photos" : [
{
"orderInEntry" : 5,
"md5" : "ad7f659d748c1a41c753907c6946eb03",
// ...
},
// ...
],
// ...
}
It implies that the file you are looking for is a photo, and is located in the 2020-10-01 entry, and is the (5 + 1) th asset in the entry.
Now the only thing to do is to find out the photo, and rename it to its md5 hash value and then copy it to the ./photo folder.
Special Cases for Photo Extension Name
Note that in some circumstances, the extension name of the image you found is different from the type field in the image json. Feel free to change the dumped data. The checker program will calculate the md5 value for each file indexed, and will inform you if anything is going wrong.
e.g. If the image you found have the png extension, and the json data looks like the following:
"photos" : [
{
"orderInEntry" : 5,
"md5" : "ad7f659d748c1a41c753907c6946eb03",
"type": "jpeg", // feel free to change to "png"
// ...
},
// ...
],
Audio Extension Name
Most audios have m4a as extension name. However, the dumped json data might have aac as the value of format field:
"audios" : [
{
"fileSize" : 372838,
"orderInEntry" : 4,
"duration" : 55.68,
"favorite" : false,
"format" : "aac", // Here it is
"md5" : "3c93e9d7389628f6b364e1b2029cd046",
// ...
}
]
Feel free to change it into m4a. The only rule is that you should keep the extension name of audio files and format field value the same.
Usage
$ python3 .\converter.py convert --help
Usage: converter.py convert [OPTIONS] DIRECTORY
Convert dumped data to markdown files
ARGUMENTS:
* DIRECTORY: path of unzipped Day One data
Options:
--help Show this message and exit.
The converted files are located in the ./markdown folder relative to Day One data folder.
Known Issues
Following formats are not supported, 'cause I am not subscribing the app any more. If any one is interested in supporting those formats, feel free to send me dumped data, and I will take a look on them.
- Sketch
- File
- Scan
- Template
Some text attributes cannot be retained, for example red text, because they are not exported explicitly in dumped data, neither in text field, nor in richText field.
TODO
- Location
- Weather
 11.3k Jan 5, 2023
11.3k Jan 5, 2023
 685 Jan 1, 2023
685 Jan 1, 2023
 2.4k Dec 30, 2022
2.4k Dec 30, 2022

 740 Jan 8, 2023
740 Jan 8, 2023
 659 Jan 4, 2023
659 Jan 4, 2023
 398 Dec 24, 2022
398 Dec 24, 2022
 546 Jan 1, 2023
546 Jan 1, 2023
 86 Dec 25, 2022
86 Dec 25, 2022
 37 Jan 2, 2023
37 Jan 2, 2023



 213 Dec 22, 2022
213 Dec 22, 2022
 85 Dec 30, 2022
85 Dec 30, 2022
 4 Aug 13, 2022
4 Aug 13, 2022
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
 1 Dec 19, 2021
1 Dec 19, 2021
 7 Jan 22, 2022
7 Jan 22, 2022
 2 Feb 17, 2022
2 Feb 17, 2022
 2.2k Jan 4, 2023
2.2k Jan 4, 2023
 3.1k Dec 30, 2022
3.1k Dec 30, 2022