CosineAnnealingWithWarmup
Formulation
The learning rate is annealed using a cosine schedule over the course of learning of n_total total steps with an initial warmup period of n_warmup steps. Hence, the learning rate at step i is computed as:
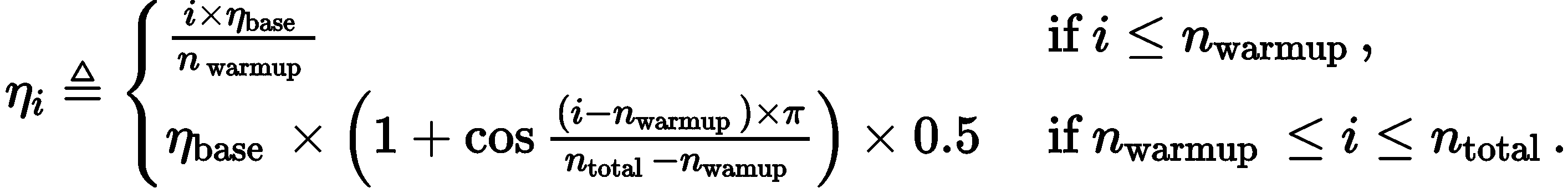
Learning rate will be changed as:
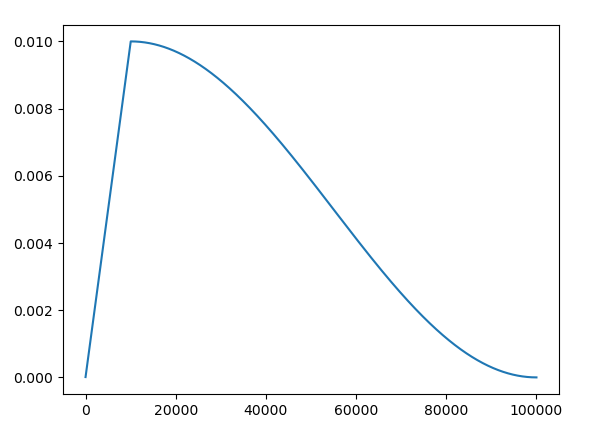
Usage
# optimizer, warmup_epochs, warmup_lr, num_epochs, base_lr, final_lr, iter_per_epoch
lr_scheduler = LR_Scheduler(
optimizer,
args.warmup_epochs, args.warmup_lr*args.batch_size/256,
args.epochs, args.lr*args.batch_size/256, args.final_lr*args.batch_size/256,
len(train_loader),
)
for data in range(train_loader):
optimizer.zero_grad()
output = model(data)
loss = lossfunc(output,gt)
loss.backward()
optimizer.step()
lr_scheduler.step()
In CV domain [1,2], in order to automatically adapt different batch size you can use a learning rate of lr×BatchSize/256 (linear scaling [4])(we can use larger learning rate while adopting larger batch size, especially, when you use LARS optimizer[3]). Of course, you can modify it according to your specific requirements.
Reference
[1] Jean-Bastien Grill, Florian Strub, Florent Altch´e, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Do- ersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Moham- mad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, R´emi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning. arXiv:2006.07733v1, 2020.
[2] Chen X, He K. Exploring simple siamese representation learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 15750-15758.
[3] Yang You, Igor Gitman, and Boris Ginsburg. Large batch training of convolutional networks. arXiv:1708.03888, 2017.
[4] Priya Goyal, Piotr Doll´ar, Ross Girshick, Pieter Noord- huis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: Training ImageNet in 1 hour. arXiv:1706.02677, 2017.
[5] https://github.com/PatrickHua/SimSiam?utm_source=catalyzex.com
 3.7k Jan 1, 2023
3.7k Jan 1, 2023
 924 Jan 3, 2023
924 Jan 3, 2023

 55 Jun 15, 2022
55 Jun 15, 2022
 57 Nov 27, 2022
57 Nov 27, 2022
 13 Dec 11, 2022
13 Dec 11, 2022
 71 Dec 22, 2022
71 Dec 22, 2022
 3 Aug 25, 2022
3 Aug 25, 2022
 8 May 28, 2022
8 May 28, 2022
 10 Mar 22, 2022
10 Mar 22, 2022

 2 Feb 15, 2022
2 Feb 15, 2022

 203 Nov 30, 2022
203 Nov 30, 2022
 3.7k Jan 3, 2023
3.7k Jan 3, 2023
 57 Nov 27, 2022
57 Nov 27, 2022
 71 Dec 22, 2022
71 Dec 22, 2022
 10 Mar 22, 2022
10 Mar 22, 2022
 2 Feb 15, 2022
2 Feb 15, 2022
 133 Dec 20, 2022
133 Dec 20, 2022
 249 Jan 2, 2023
249 Jan 2, 2023