configaformers (re-factor in progress)
A python library for highly configurable transformers - easing model architecture search and experimentation. It is premised on building small and independent modules that enables users to configure custom transformer architectures.
Special thanks to lucidrains (https://github.com/lucidrains) and Kharr.
Usage
Quick demo that will configure a 768-wide, 12-layer transformer, with a language modeling head.
Import, and create token embedding block:
import torch
from model_builder import ConfigaFormer
emb = []
model_dim = 768
emb.append({'type': 'embedding',
'output_dim': model_dim,
'num_classes': 50257})
Create self-attention module:
attn = []
# Make residual and norm
attn.append({'type': 'make_stream', 'output_name': 'residual'})
attn.append({'type': 'norm', 'norm_type': 'layer_norm'})
# Make QKVs
attn.append({'type': 'linear', 'output_name': 'queries'})
attn.append({'type': 'linear', 'output_name': 'keys'})
attn.append({'type': 'linear', 'output_name': 'values'})
attn.append({'type': 'make_heads', 'input_name': 'queries', 'output_name': 'queries', 'num_heads': 12})
attn.append({'type': 'make_heads', 'input_name': 'keys', 'output_name': 'keys', 'num_heads': 12})
attn.append({'type': 'rope', 'input_name': 'queries', 'output_name': 'queries', 'rotate_dim': 16})
attn.append({'type': 'rope', 'input_name': 'keys', 'output_name': 'keys', 'rotate_dim': 16})
# Perform attention
attn.append({'type': 'mha_dots',
'input_name_queries': 'queries',
'input_name_keys': 'keys'})
attn.append({'type': 'attention_offset'})
attn.append({'type': 'mha_sum',
'input_name_values': 'values'})
# Mix
attn.append({'type': 'linear'})
# Add residual
attn.append({'type': 'merge_streams',
'input_name_1': 'residual',
'merge_type': 'add'})
Create FFN module:
ffn = []
# Make residual and norm
ffn.append({'type': 'make_stream', 'output_name': 'residual'})
ffn.append({'type': 'norm', 'norm_type': 'layer_norm'})
# Proj Up
ffn.append({'type': 'linear', 'output_dim': 768*4})
# Activation
ffn.append({'type': 'activation'})
# Proj Down
ffn.append({'type': 'linear', 'output_dim': 768})
# Add residual
ffn.append({'type': 'merge_streams',
'input_name_1': 'residual',
'merge_type': 'add'})
Create language modeling head:
to_logits = []
to_logits.append({'type': 'linear', 'output_dim': 50257})
Create blocks, initialize input shapes, and init the model:
transformer_block = attn + ffn
classifier = ffn + to_logits
blocks = [{"config": emb,
"repeat": 1},
{"config": transformer_block,
"repeat": 12},
{"config": classifier,
"repeat": 1},
]
my_config = {'blocks' = blocks}
input_streams = {'emb_ids': ['B', 'L_in'],
'attn_offset': ['B', 12, 'L_in', 'L_in'],}
model = ConfigaFormer(model_config=my_config,
input_streams=input_streams).cuda()
This will print out the transformer config:
Block #1, 1x
embedding -> Input(s): emb_ids (BSZ, L_in) - Output(s): x (BSZ, L_in, 768)
Block #2, 12x
make_stream -> Input(s): x (BSZ, L_in, 768) - Output(s): residual (BSZ, L_in, 768)
norm -> Input(s): x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 768)
linear -> Input(s): x (BSZ, L_in, 768) - Output(s): queries (BSZ, L_in, 768)
linear -> Input(s): x (BSZ, L_in, 768) - Output(s): keys (BSZ, L_in, 768)
linear -> Input(s): x (BSZ, L_in, 768) - Output(s): values (BSZ, L_in, 768)
make_heads -> Input(s): queries (BSZ, L_in, 768) - Output(s): queries (BSZ, 12, L_in, 64)
make_heads -> Input(s): keys (BSZ, L_in, 768) - Output(s): keys (BSZ, 12, L_in, 64)
rope -> Input(s): queries (BSZ, 12, L_in, 64), rope_16 (2048, 16) - Output(s): queries (BSZ, 12, L_in, 64)
rope -> Input(s): keys (BSZ, 12, L_in, 64), rope_16 (2048, 16) - Output(s): keys (BSZ, 12, L_in, 64)
mha_dots -> Input(s): queries (BSZ, 12, L_in, 64), keys (BSZ, 12, L_in, 64) - Output(s): attn_dots (BSZ, 12, L_in, L_in)
attention_offset -> Input(s): attn_dots (BSZ, 12, L_in, L_in), attn_offset (BSZ, 12, L_in, L_in) - Output(s): attn_dots (BSZ, 12, L_in, L_in)
mha_sum -> Input(s): values (BSZ, L_in, 768), attn_dots (BSZ, 12, L_in, L_in) - Output(s): x (BSZ, L_in, 768)
linear -> Input(s): x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 768)
merge_streams -> Input(s): residual (BSZ, L_in, 768), x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 768)
make_stream -> Input(s): x (BSZ, L_in, 768) - Output(s): residual (BSZ, L_in, 768)
norm -> Input(s): x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 768)
linear -> Input(s): x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 3072)
activation -> Input(s): x (BSZ, L_in, 3072) - Output(s): x (BSZ, L_in, 3072)
linear -> Input(s): x (BSZ, L_in, 3072) - Output(s): x (BSZ, L_in, 768)
merge_streams -> Input(s): residual (BSZ, L_in, 768), x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 768)
Block #3, 1x
make_stream -> Input(s): x (BSZ, L_in, 768) - Output(s): residual (BSZ, L_in, 768)
norm -> Input(s): x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 768)
linear -> Input(s): x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 3072)
activation -> Input(s): x (BSZ, L_in, 3072) - Output(s): x (BSZ, L_in, 3072)
linear -> Input(s): x (BSZ, L_in, 3072) - Output(s): x (BSZ, L_in, 768)
merge_streams -> Input(s): residual (BSZ, L_in, 768), x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 768)
linear -> Input(s): x (BSZ, L_in, 768) - Output(s): x (BSZ, L_in, 50257)
Before running, we need to get the attention offset (in this case, AliBi with a causal mask):
from attention_offset_module import get_alibi
attn_offset = get_alibi(num_heads=12)
Now we can use the model:
input_data = {'emb_ids': batch_ids.view(bsz, 1024).cuda(),
'attn_offset': attn_offset.cuda()}
logits = model(input_data)['x'].view(bsz, 1024, 50257)
TODO
- Token shifting, down/up sampling
- Create higher abstractions for FFN and self-attention
- everything else
 57 Nov 30, 2022
57 Nov 30, 2022
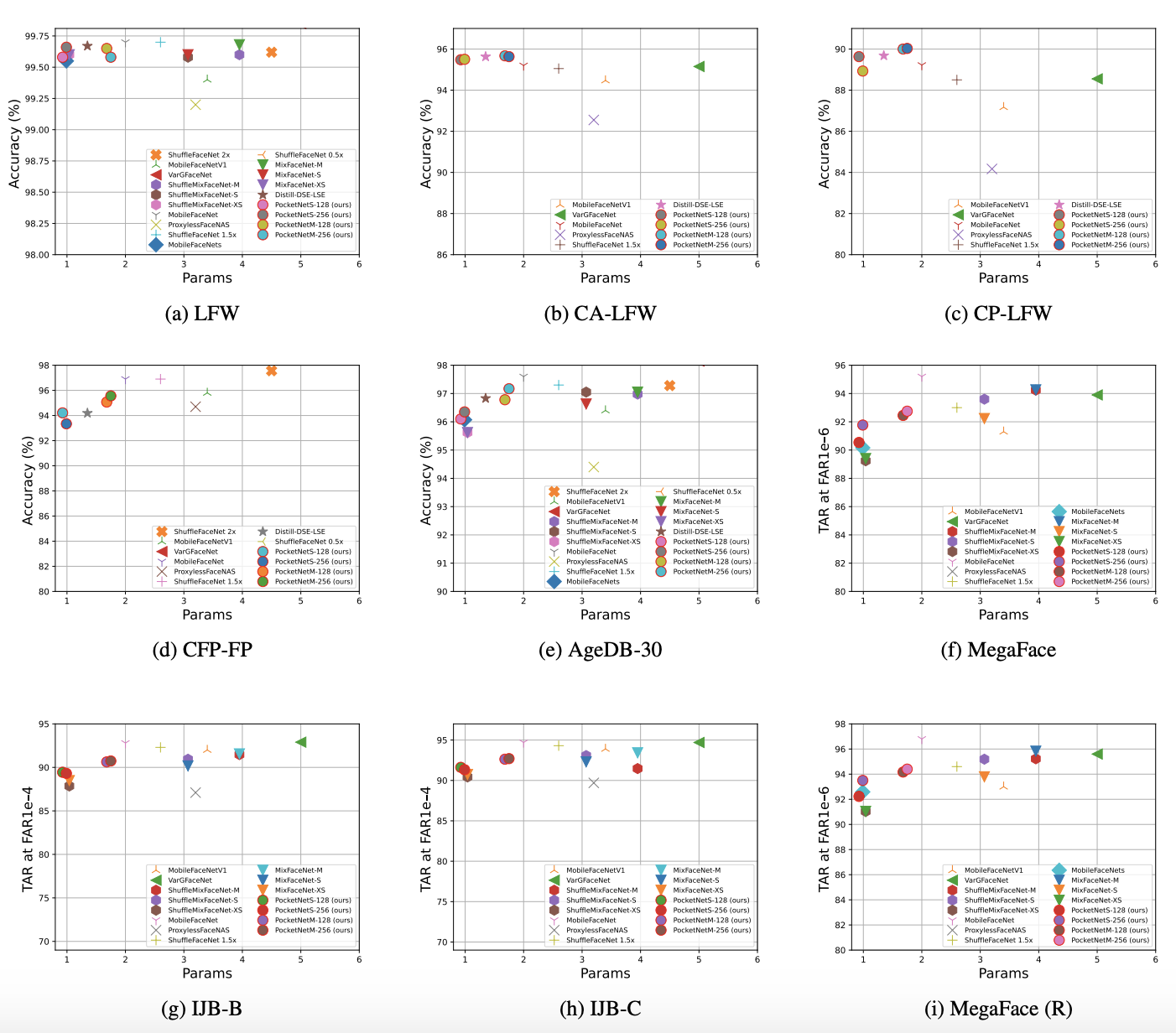
 40 Dec 22, 2022
40 Dec 22, 2022

 3.7k Jan 9, 2023
3.7k Jan 9, 2023
 214 Jan 8, 2023
214 Jan 8, 2023
 156 Nov 28, 2022
156 Nov 28, 2022
![[ICLR 2021] HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark](https://github.com/RICE-EIC/HW-NAS-Bench/raw/main/devices.jpg?raw=true)
 72 Jan 3, 2023
72 Jan 3, 2023

 23 Dec 21, 2022
23 Dec 21, 2022

 48 Sep 30, 2022
48 Sep 30, 2022
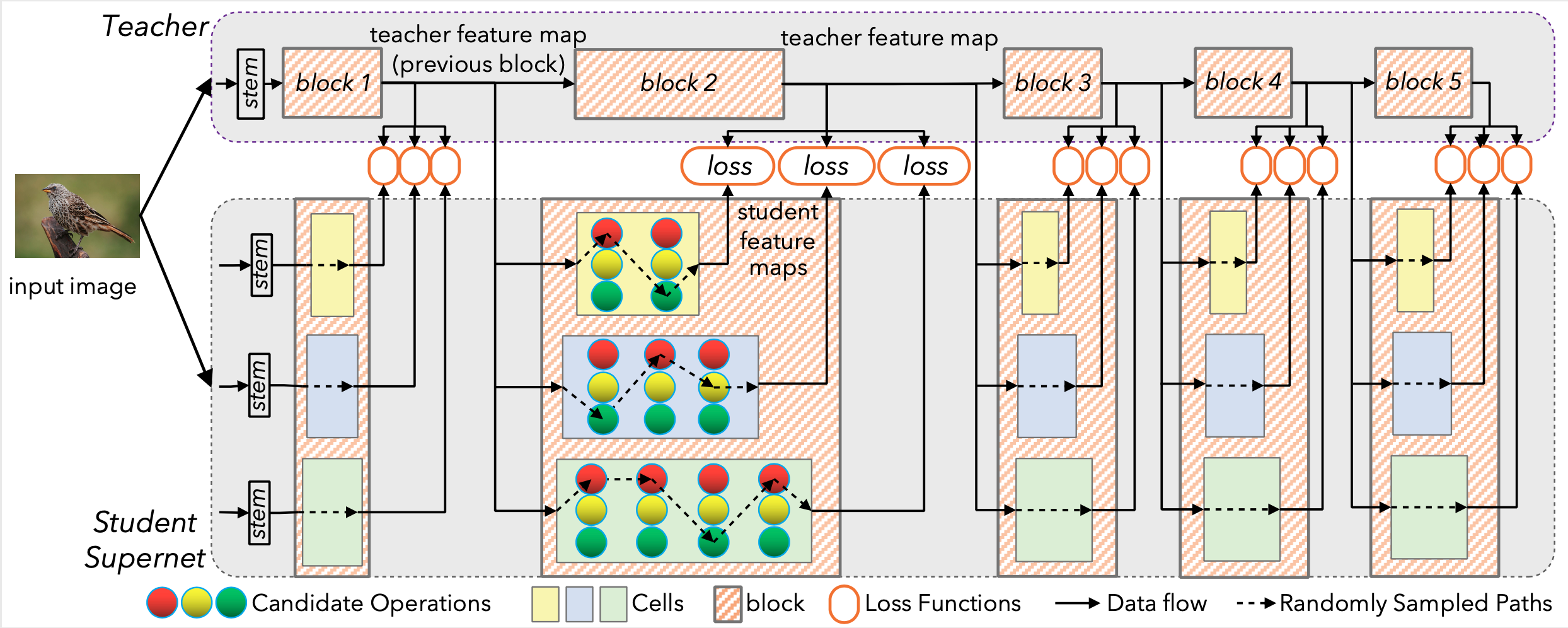
 215 Dec 19, 2022
215 Dec 19, 2022

 134 Jul 10, 2022
134 Jul 10, 2022
 127 Dec 26, 2022
127 Dec 26, 2022
 291 Nov 18, 2022
291 Nov 18, 2022
 0 Aug 1, 2022
0 Aug 1, 2022
 139 Jan 1, 2023
139 Jan 1, 2023
 270 Jan 3, 2023
270 Jan 3, 2023
 22 Jan 5, 2023
22 Jan 5, 2023
 146 Dec 28, 2022
146 Dec 28, 2022
 3 Oct 31, 2022
3 Oct 31, 2022
 6 Nov 18, 2022
6 Nov 18, 2022