
This repository is forked from Real-Time-Voice-Cloning which only support English.
English | 中文
Features
DEMO VIDEO
Quick Start
1. Install Requirements
Follow the original repo to test if you got all environment ready. **Python 3.7 or higher ** is needed to run the toolbox.
- Install PyTorch.
- Install ffmpeg.
- Run
pip install -r requirements.txtto install the remaining necessary packages.
2. Train synthesizer with aidatatang_200zh
-
Download aidatatang_200zh dataset and unzip: make sure you can access all .wav in train folder
-
Preprocess with the audios and the mel spectrograms:
python synthesizer_preprocess_audio.py -
Preprocess the embeddings:
python synthesizer_preprocess_embeds.py/SV2TTS/synthesizer -
Train the synthesizer:
python synthesizer_train.py mandarin/SV2TTS/synthesizer -
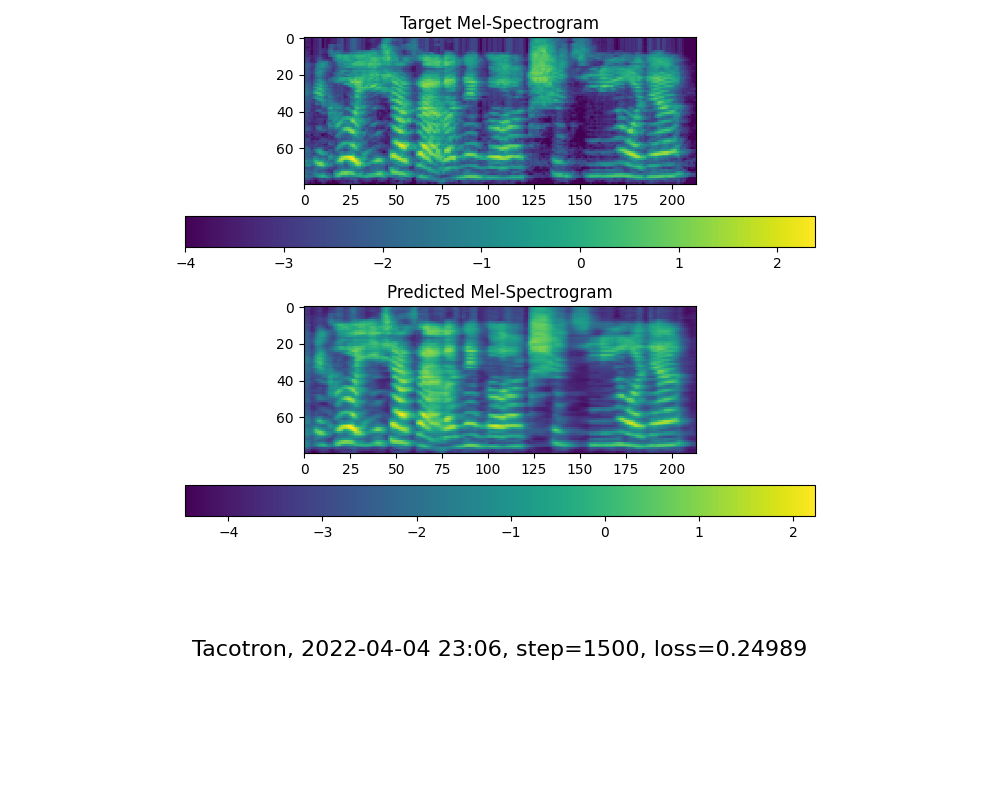
Go to next step when you see attention line show and loss meet your need in training folder synthesizer/saved_models/.
FYI, my attention came after 18k steps and loss became lower than 0.4 after 50k steps.


3. Launch the Toolbox
You can then try the toolbox:
python demo_toolbox.py -d
or
python demo_toolbox.py
TODO
- Add demo video
- Add support for more dataset
- Upload pretrained model
-
🙏 Welcome to add more













![FileNotFoundError: [Errno 2] No such file or directory: 'encoder\\saved_models\\pretrained.pt'](https://avatars.githubusercontent.com/u/62303408?v=4)










 19 Jun 30, 2022
19 Jun 30, 2022
 6 Nov 8, 2022
6 Nov 8, 2022
 575 Dec 31, 2022
575 Dec 31, 2022
 2 Jun 19, 2022
2 Jun 19, 2022
 15.3k Dec 30, 2022
15.3k Dec 30, 2022
 3 Oct 15, 2021
3 Oct 15, 2021
 16 Dec 7, 2022
16 Dec 7, 2022
 14 Dec 9, 2022
14 Dec 9, 2022
 2.2k Jan 9, 2023
2.2k Jan 9, 2023
 22 Nov 13, 2022
22 Nov 13, 2022
 11 Nov 17, 2022
11 Nov 17, 2022
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
 1k Dec 30, 2022
1k Dec 30, 2022
 5 Dec 28, 2021
5 Dec 28, 2021
 1 Dec 20, 2021
1 Dec 20, 2021
 29 Oct 16, 2022
29 Oct 16, 2022
 873 Dec 15, 2022
873 Dec 15, 2022