
Silero Models
Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks.
Enterprise-grade STT made refreshingly simple (seriously, see benchmarks). We provide quality comparable to Google's STT (and sometimes even better) and we are not Google.
As a bonus:
- No Kaldi;
- No compilation;
- No 20-step instructions;
Also we have published TTS models that satisfy the following criteria:
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for 16kHz and 8kHz out of the box;
Speech-To-Text
All of the provided models are listed in the models.yml file. Any meta-data and newer versions will be added there.
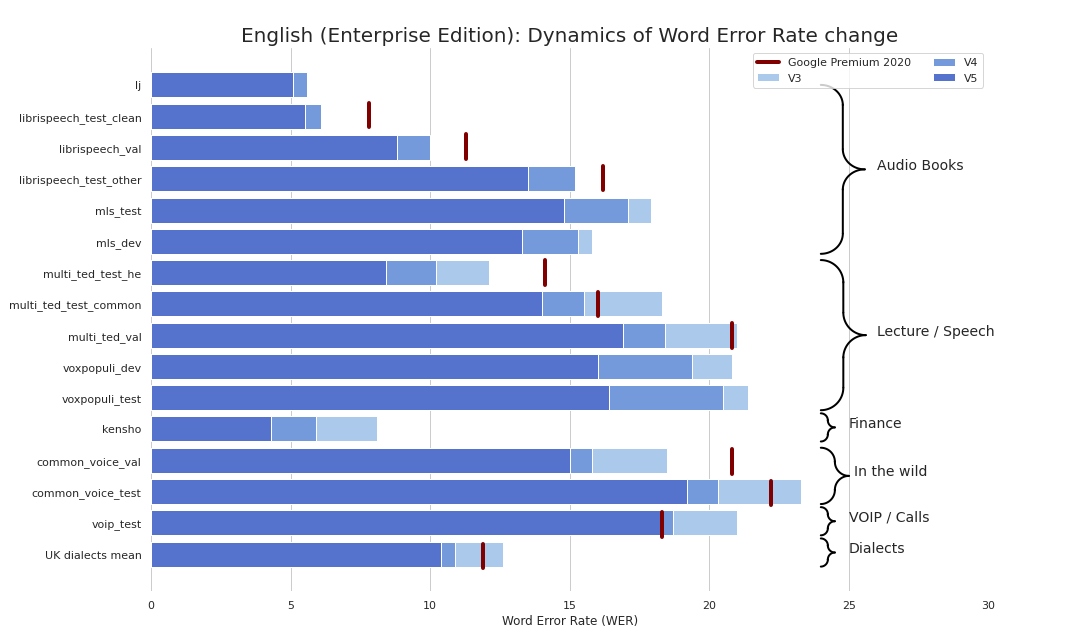
Currently we provide the following checkpoints:
| PyTorch | ONNX | Quantization | Quality | Colab | |
|---|---|---|---|---|---|
English (en_v5) |
|
|
|
link | |
German (de_v4) |
|
|
|
link | |
English (en_v3) |
|
|
|
link | |
German (de_v3) |
|
|
|
link | |
German (de_v1) |
|
|
|
link | |
Spanish (es_v1) |
|
|
|
link | |
Ukrainian (ua_v3) |
|
|
|
N/A |
Model flavours:
| jit | jit | jit | jit | jit_q | jit_q | onnx | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|---|
| xsmall | small | large | xlarge | xsmall | small | xsmall | small | large | xlarge | |
English en_v5 |
|
|
|
|
|
|||||
English en_v4_0 |
|
|
||||||||
English en_v3 |
|
|
|
|
|
|
|
|
||
German de_v4 |
|
|
||||||||
German de_v3 |
|
|||||||||
German de_v1 |
|
|
||||||||
Spanish es_v1 |
|
|
||||||||
Ukrainian ua_v3 |
|
|
|
Dependencies
- All examples:
torch, 1.8+ (used to clone the repo in tf and onnx examples), breaking changes for version older than 1.6torchaudio, latest version bound to PyTorch should workomegaconf, latest just should work
- Additional for ONNX examples:
onnx, latest just should workonnxruntime, latest just should work
- Additional for TensorFlow examples:
tensorflow, latest just should worktensorflow_hub, latest just should work
Please see the provided Colab for details for each example below. All examples are maintained to work with the latest major packaged versions of the installed libraries.
PyTorch
import torch
import zipfile
import torchaudio
from glob import glob
device = torch.device('cpu') # gpu also works, but our models are fast enough for CPU
model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_stt',
language='en', # also available 'de', 'es'
device=device)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils # see function signature for details
# download a single file, any format compatible with TorchAudio
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav',
dst ='speech_orig.wav', progress=True)
test_files = glob('speech_orig.wav')
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]),
device=device)
output = model(input)
for example in output:
print(decoder(example.cpu()))
ONNX
You can run our model everywhere, where you can import the ONNX model or run ONNX runtime.
import onnx
import torch
import onnxruntime
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils
_, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_stt', language=language)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils
# see available models
torch.hub.download_url_to_file('https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml', 'models.yml')
models = OmegaConf.load('models.yml')
available_languages = list(models.stt_models.keys())
assert language in available_languages
# load the actual ONNX model
torch.hub.download_url_to_file(models.stt_models.en.latest.onnx, 'model.onnx', progress=True)
onnx_model = onnx.load('model.onnx')
onnx.checker.check_model(onnx_model)
ort_session = onnxruntime.InferenceSession('model.onnx')
# download a single file, any format compatible with TorchAudio
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav', dst ='speech_orig.wav', progress=True)
test_files = ['speech_orig.wav']
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]))
# actual onnx inference and decoding
onnx_input = input.detach().cpu().numpy()
ort_inputs = {'input': onnx_input}
ort_outs = ort_session.run(None, ort_inputs)
decoded = decoder(torch.Tensor(ort_outs[0])[0])
print(decoded)
TensorFlow
SavedModel example
import os
import torch
import subprocess
import tensorflow as tf
import tensorflow_hub as tf_hub
from omegaconf import OmegaConf
language = 'en' # also available 'de', 'es'
# load provided utils using torch.hub for brevity
_, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_stt', language=language)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils
# see available models
torch.hub.download_url_to_file('https://raw.githubusercontent.com/snakers4/silero-models/master/models.yml', 'models.yml')
models = OmegaConf.load('models.yml')
available_languages = list(models.stt_models.keys())
assert language in available_languages
# load the actual tf model
torch.hub.download_url_to_file(models.stt_models.en.latest.tf, 'tf_model.tar.gz')
subprocess.run('rm -rf tf_model && mkdir tf_model && tar xzfv tf_model.tar.gz -C tf_model', shell=True, check=True)
tf_model = tf.saved_model.load('tf_model')
# download a single file, any format compatible with TorchAudio
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav', dst ='speech_orig.wav', progress=True)
test_files = ['speech_orig.wav']
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]))
# tf inference
res = tf_model.signatures["serving_default"](tf.constant(input.numpy()))['output_0']
print(decoder(torch.Tensor(res.numpy())[0]))
Text-To-Speech
Models and Speakers
All of the provided models are listed in the models.yml file. Any meta-data and newer versions will be added there.
Currently we provide the following speakers:
| Speaker | Auto-stress | Language | SR | Colab |
|---|---|---|---|---|
aidar_v2 |
yes | ru (Russian) |
8000, 16000 |
|
baya_v2 |
yes | ru (Russian) |
8000, 16000 |
|
irina_v2 |
yes | ru (Russian) |
8000, 16000 |
|
kseniya_v2 |
yes | ru (Russian) |
8000, 16000 |
|
natasha_v2 |
yes | ru (Russian) |
8000, 16000 |
|
ruslan_v2 |
yes | ru (Russian) |
8000, 16000 |
|
lj_v2 |
no | en (English) |
8000, 16000 |
|
thorsten_v2 |
no | de (German) |
8000, 16000 |
|
tux_v2 |
no | es (Spanish) |
8000, 16000 |
|
gilles_v2 |
no | fr (French) |
8000, 16000 |
|
multi_v2 |
no | ru, en, de, es, fr, tt |
8000, 16000 |
|
aigul_v2 |
no | ba (Bashkir) |
8000, 16000 |
|
erdni_v2 |
no | xal (Kalmyk) |
8000, 16000 |
|
dilyara_v2 |
no | tt (Tatar) |
8000, 16000 |
|
dilnavoz_v2 |
no | uz (Uzbek) |
8000, 16000 |
(!!!) In multi_v2 all speakers can speak all of langauges (with various levels of fidelity).
Dependencies
Basic dependencies for colab examples:
torch, 1.9+;torchaudio, latest version bound to PyTorch should work (required only because models are hosted together with STT, not required for work);omegaconf, latest (can be removed as well, if you do not load all of the configs);
PyTorch
import torch
language = 'ru'
speaker = 'kseniya_v2'
sample_rate = 16000
device = torch.device('cpu')
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_tts',
language=language,
speaker=speaker)
model.to(device) # gpu or cpu
audio = model.apply_tts(texts=[example_text],
sample_rate=sample_rate)
Standalone Use
- Standalone usage just requires PyTorch 1.9+ and python standard library;
- Please see the detailed examples in Colab;
import os
import torch
device = torch.device('cpu')
torch.set_num_threads(4)
local_file = 'model.pt'
if not os.path.isfile(local_file):
torch.hub.download_url_to_file('https://models.silero.ai/models/tts/ru/v2_kseniya.pt',
local_file)
model = torch.package.PackageImporter(local_file).load_pickle("tts_models", "model")
model.to(device)
example_batch = ['В недрах тундры выдры в г+етрах т+ырят в вёдра ядра кедров.',
'Котики - это жидкость!',
'М+ама М+илу м+ыла с м+ылом.']
sample_rate = 16000
audio_paths = model.save_wav(texts=example_batch,
sample_rate=sample_rate)
FAQ
Wiki
Also check out our wiki.
Performance and Quality
Please refer to this wiki sections:
Adding new Languages
Please refer here.
Contact
Get in Touch
Try our models, create an issue, join our chat, email us, read our news.
Commercial Inquiries
Please see our wiki and tiers for relevant information and email us.
Citations
@misc{Silero Models,
author = {Silero Team},
title = {Silero Models: pre-trained enterprise-grade STT / TTS models and benchmarks},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/snakers4/silero-models}},
commit = {insert_some_commit_here},
email = {hello@silero.ai}
}
Further reading
English
-
STT:
-
TTS:
- High-Quality Text-to-Speech Made Accessible, Simple and Fast - link
-
VAD:
- Modern Portable Voice Activity Detector Released - link
Chinese
Russian
-
STT
-
TTS:
- Мы Опубликовали Качественный, Простой, Доступный и Быстрый Синтез Речи - link
-
VAD:
- Мы опубликовали современный Voice Activity Detector и не только -link
Donations
Please use the "sponsor" button.













![Feature request - [Wake Word Detection]](https://avatars.githubusercontent.com/u/50025123?v=4)

 1.1k Jan 3, 2023
1.1k Jan 3, 2023
 9 Nov 7, 2022
9 Nov 7, 2022
 2 Oct 17, 2021
2 Oct 17, 2021
 1 Dec 20, 2021
1 Dec 20, 2021
 6 Apr 29, 2022
6 Apr 29, 2022
 44 Dec 31, 2022
44 Dec 31, 2022
 89 Jan 3, 2023
89 Jan 3, 2023
 22 Dec 14, 2022
22 Dec 14, 2022
 2.3k Jan 8, 2023
2.3k Jan 8, 2023
 1.4k Jan 3, 2023
1.4k Jan 3, 2023
 84 Dec 20, 2022
84 Dec 20, 2022
 947 Dec 28, 2022
947 Dec 28, 2022
 5 Dec 28, 2021
5 Dec 28, 2021
 1 Dec 21, 2021
1 Dec 21, 2021
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
 4 Jul 1, 2022
4 Jul 1, 2022
 1k Dec 30, 2022
1k Dec 30, 2022
 72 Dec 9, 2022
72 Dec 9, 2022
 117 Jan 7, 2023
117 Jan 7, 2023