
| Package | Description | Status |
|---|---|---|
| PyNHD | Navigate and subset NHDPlus (MR and HR) using web services | |
| Py3DEP | Access topographic data through National Map's 3DEP web service | |
| PyGeoHydro | Access NWIS, NID, HCDN 2009, NLCD, and SSEBop databases | |
| PyDaymet | Access Daymet for daily climate data both single pixel and gridded | |
| AsyncRetriever | High-level API for asynchronous requests with persistent caching | |
| PyGeoOGC | Send queries to any ArcGIS RESTful-, WMS-, and WFS-based services | |
| PyGeoUtils | Convert responses from PyGeoOGC's supported web services to datasets |
PyNHD: Navigate and subset NHDPlus database



Features
PyNHD is a part of HyRiver software stack that is designed to aid in watershed analysis through web services.
This package provides access to WaterData, the National Map's NHDPlus HR, NLDI, and PyGeoAPI web services. These web services can be used to navigate and extract vector data from NHDPlus V2 (both medium- and hight-resolution) database such as catchments, HUC8, HUC12, GagesII, flowlines, and water bodies. Moreover, PyNHD gives access to an item on ScienceBase called Select Attributes for NHDPlus Version 2.1 Reach Catchments and Modified Network Routed Upstream Watersheds for the Conterminous United States. This item provides over 30 attributes at catchment-scale based on NHDPlus ComIDs. These attributes are available in three categories:
- Local (local): For individual reach catchments,
- Total (upstream_acc): For network-accumulated values using total cumulative drainage area,
- Divergence (div_routing): For network-accumulated values using divergence-routed.
Moreover, the PyGeoAPI service provides four functionalities:
flow_trace: Trace flow from a starting point to up/downstream direction.split_catchment: Split the local catchment of a point of interest at the point's location.elevation_profile: Extract elevation profile along a flow path between two points.cross_section: Extract cross-section at a point of interest along a flow line.
A list of these attributes for each characteristic type can be accessed using nhdplus_attrs function.
Similarly, PyNHD uses this item on Hydroshare to get ComID-linked NHDPlus Value Added Attributes. This dataset includes slope and roughness, among other attributes, for all the flowlines. You can use nhdplus_vaa function to get this dataset.
Additionally, PyNHD offers some extra utilities for processing the flowlines:
prepare_nhdplus: For cleaning up the dataframe by, for example, removing tiny networks, adding ato_comidcolumn, and finding a terminal flowlines if it doesn't exist.topoogical_sort: For sorting the river network topologically which is useful for routing and flow accumulation.vector_accumulation: For computing flow accumulation in a river network. This function is generic and any routing method can be plugged in.
These utilities are developed based on an R package called nhdplusTools.
You can find some example notebooks here.
Please note that since this project is in early development stages, while the provided functionalities should be stable, changes in APIs are possible in new releases. But we appreciate it if you give this project a try and provide feedback. Contributions are most welcome.
Moreover, requests for additional functionalities can be submitted via issue tracker.
Installation
You can install PyNHD using pip after installing libgdal on your system (for example, in Ubuntu run sudo apt install libgdal-dev). Moreover, PyNHD has an optional dependency for using persistent caching, requests-cache. We highly recommend to install this package as it can significantly speedup send/receive queries. You don't have to change anything in your code, since PyNHD under-the-hood looks for requests-cache and if available, it will automatically use persistent caching:
$ pip install pynhd
Alternatively, PyNHD can be installed from the conda-forge repository using Conda:
$ conda install -c conda-forge pynhd
Quick start
Let's explore the capabilities of NLDI. We need to instantiate the class first:
from pynhd import NLDI, WaterData, NHDPlusHR
import pynhd as nhd
First, let’s get the watershed geometry of the contributing basin of a USGS station using NLDI:
nldi = NLDI()
station_id = "01031500"
basin = nldi.get_basins(station_id)
The navigate_byid class method can be used to navigate NHDPlus in both upstream and downstream of any point in the database. Let’s get ComIDs and flowlines of the tributaries and the main river channel in the upstream of the station.
flw_main = nldi.navigate_byid(
fsource="nwissite",
fid=f"USGS-{station_id}",
navigation="upstreamMain",
source="flowlines",
distance=1000,
)
flw_trib = nldi.navigate_byid(
fsource="nwissite",
fid=f"USGS-{station_id}",
navigation="upstreamTributaries",
source="flowlines",
distance=1000,
)
We can get other USGS stations upstream (or downstream) of the station and even set a distance limit (in km):
st_all = nldi.navigate_byid(
fsource="nwissite",
fid=f"USGS-{station_id}",
navigation="upstreamTributaries",
source="nwissite",
distance=1000,
)
st_d20 = nldi.navigate_byid(
fsource="nwissite",
fid=f"USGS-{station_id}",
navigation="upstreamTributaries",
source="nwissite",
distance=20,
)
Now, let’s get the HUC12 pour points:
pp = nldi.navigate_byid(
fsource="nwissite",
fid=f"USGS-{station_id}",
navigation="upstreamTributaries",
source="huc12pp",
distance=1000,
)
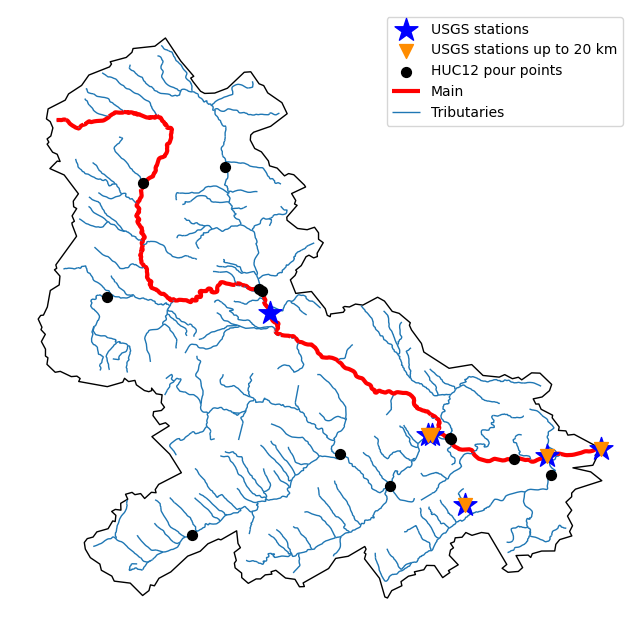
Also, we can get the slope data for each river segment from NHDPlus VAA database:
vaa = nhd.nhdplus_vaa("input_data/nhdplus_vaa.parquet")
flw_trib["comid"] = pd.to_numeric(flw_trib.nhdplus_comid)
slope = gpd.GeoDataFrame(
pd.merge(flw_trib, vaa[["comid", "slope"]], left_on="comid", right_on="comid"),
crs=flw_trib.crs,
)
slope[slope.slope < 0] = np.nan
Now, let's explore the PyGeoAPI capabilities:
pygeoapi = PyGeoAPI()
trace = pygeoapi.flow_trace(
(1774209.63, 856381.68), crs="ESRI:102003", raindrop=False, direction="none"
)
split = pygeoapi.split_catchment((-73.82705, 43.29139), crs="epsg:4326", upstream=False)
profile = pygeoapi.elevation_profile(
[(-103.801086, 40.26772), (-103.80097, 40.270568)], numpts=101, dem_res=1, crs="epsg:4326"
)
section = pygeoapi.cross_section((-103.80119, 40.2684), width=1000.0, numpts=101, crs="epsg:4326")
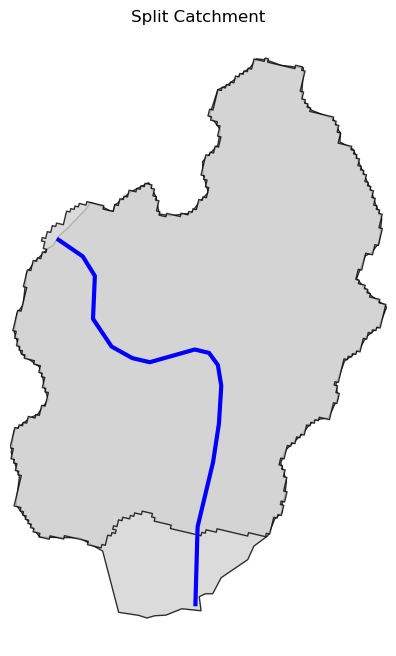
Next, we retrieve the medium- and high-resolution flowlines within the bounding box of our watershed and compare them. Moreover, Since several web services offer access to NHDPlus database, NHDPlusHR has an argument for selecting a service and also an argument for automatically switching between services.
mr = WaterData("nhdflowline_network")
nhdp_mr = mr.bybox(basin.geometry[0].bounds)
hr = NHDPlusHR("networknhdflowline", service="hydro", auto_switch=True)
nhdp_hr = hr.bygeom(basin.geometry[0].bounds)

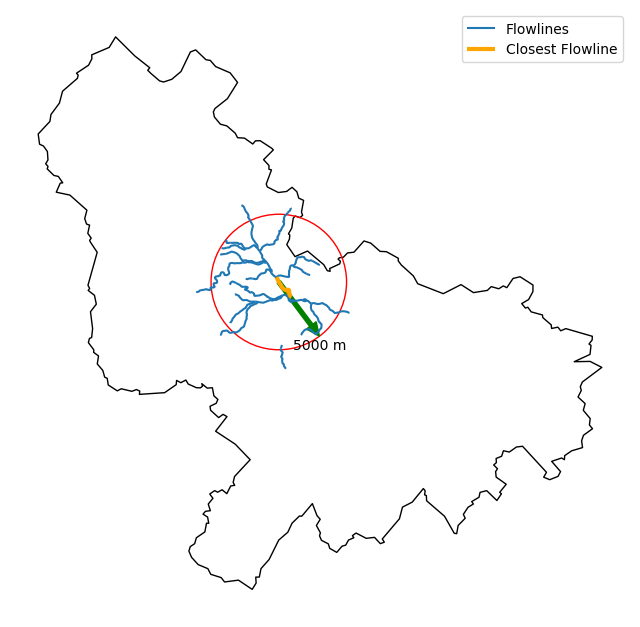
Moreover, WaterData can find features within a given radius (in meters) of a point:
eck4 = "+proj=eck4 +lon_0=0 +x_0=0 +y_0=0 +datum=WGS84 +units=m +no_defs"
coords = (-5727797.427596455, 5584066.49330473)
rad = 5e3
flw_rad = mr.bydistance(coords, rad, loc_crs=eck4)
flw_rad = flw_rad.to_crs(eck4)
Instead of getting all features within a radius of the coordinate, we can snap to the closest flowline using NLDI:
comid_closest = nldi.comid_byloc((x, y), eck4)
flw_closest = nhdp_mr.byid("comid", comid_closest.comid.values[0])
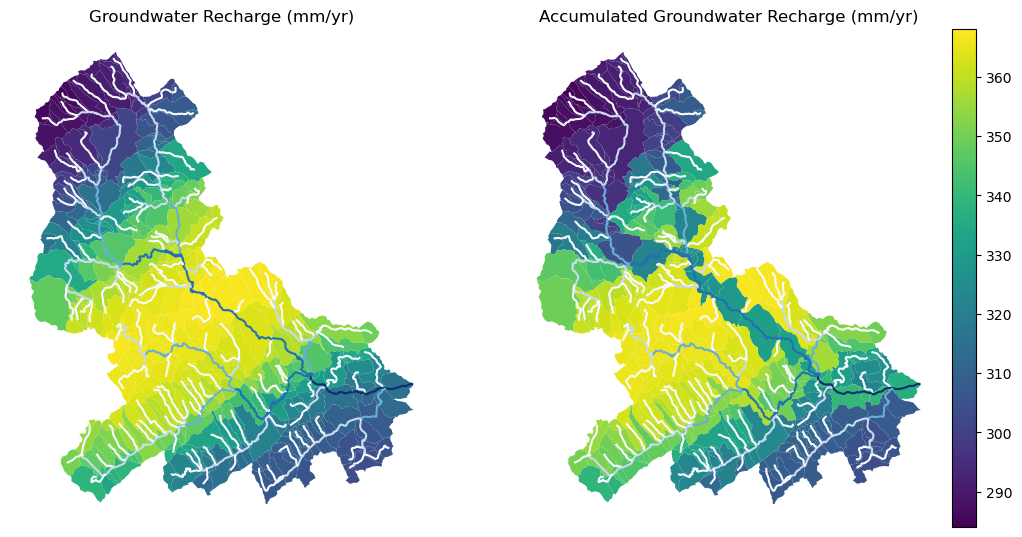
Since NHDPlus HR is still at the pre-release stage let's use the MR flowlines to demonstrate the vector-based accumulation. Based on a topological sorted river network pynhd.vector_accumulation computes flow accumulation in the network. It returns a dataframe which is sorted from upstream to downstream that shows the accumulated flow in each node.
PyNHD has a utility called prepare_nhdplus that identifies such relationship among other things such as fixing some common issues with NHDPlus flowlines. But first we need to get all the NHDPlus attributes for each ComID since NLDI only provides the flowlines’ geometries and ComIDs which is useful for navigating the vector river network data. For getting the NHDPlus database we use WaterData. Let’s use the nhdflowline_network layer to get required info.
wd = WaterData("nhdflowline_network")
comids = flw_trib.nhdplus_comid.to_list()
nhdp_trib = wd.byid("comid", comids)
flw = nhd.prepare_nhdplus(nhdp_trib, 0, 0, purge_non_dendritic=False)
To demonstrate the use of routing, let's use nhdplus_attrs function to get list of available NHDPlus attributes
Since these are catchment-scale characteristic, let’s get the catchments then add the accumulated characteristic as a new column and plot the results.
wd = WaterData("catchmentsp")
catchments = wd.byid("featureid", comids)
c_local = catchments.merge(local, left_on="featureid", right_index=True)
c_acc = catchments.merge(runoff, left_on="featureid", right_index=True)
More examples can be found here.
Contributing
Contributions are very welcomed. Please read CONTRIBUTING.rst file for instructions.















![BOT: [skip ci] Bump styfle/cancel-workflow-action from 0.9.1 to 0.10.0](https://avatars.githubusercontent.com/in/29110?v=4)

 0 Dec 1, 2021
0 Dec 1, 2021
 25 Dec 14, 2022
25 Dec 14, 2022
 98 Dec 22, 2022
98 Dec 22, 2022
 102 Nov 10, 2022
102 Nov 10, 2022
 1 Nov 16, 2021
1 Nov 16, 2021
 19 Nov 24, 2022
19 Nov 24, 2022
 1 Sep 3, 2022
1 Sep 3, 2022
 167 Dec 13, 2022
167 Dec 13, 2022
 1 Oct 20, 2021
1 Oct 20, 2021
 917 Jan 3, 2023
917 Jan 3, 2023
 208 Dec 22, 2022
208 Dec 22, 2022
 2.5k Jan 9, 2023
2.5k Jan 9, 2023
 3.8k Jan 5, 2023
3.8k Jan 5, 2023
 663 Jan 5, 2023
663 Jan 5, 2023
 79 Sep 20, 2022
79 Sep 20, 2022
 97 Dec 8, 2022
97 Dec 8, 2022
 96 Jan 1, 2023
96 Jan 1, 2023
 184 Dec 27, 2022
184 Dec 27, 2022
 168 Dec 28, 2022
168 Dec 28, 2022