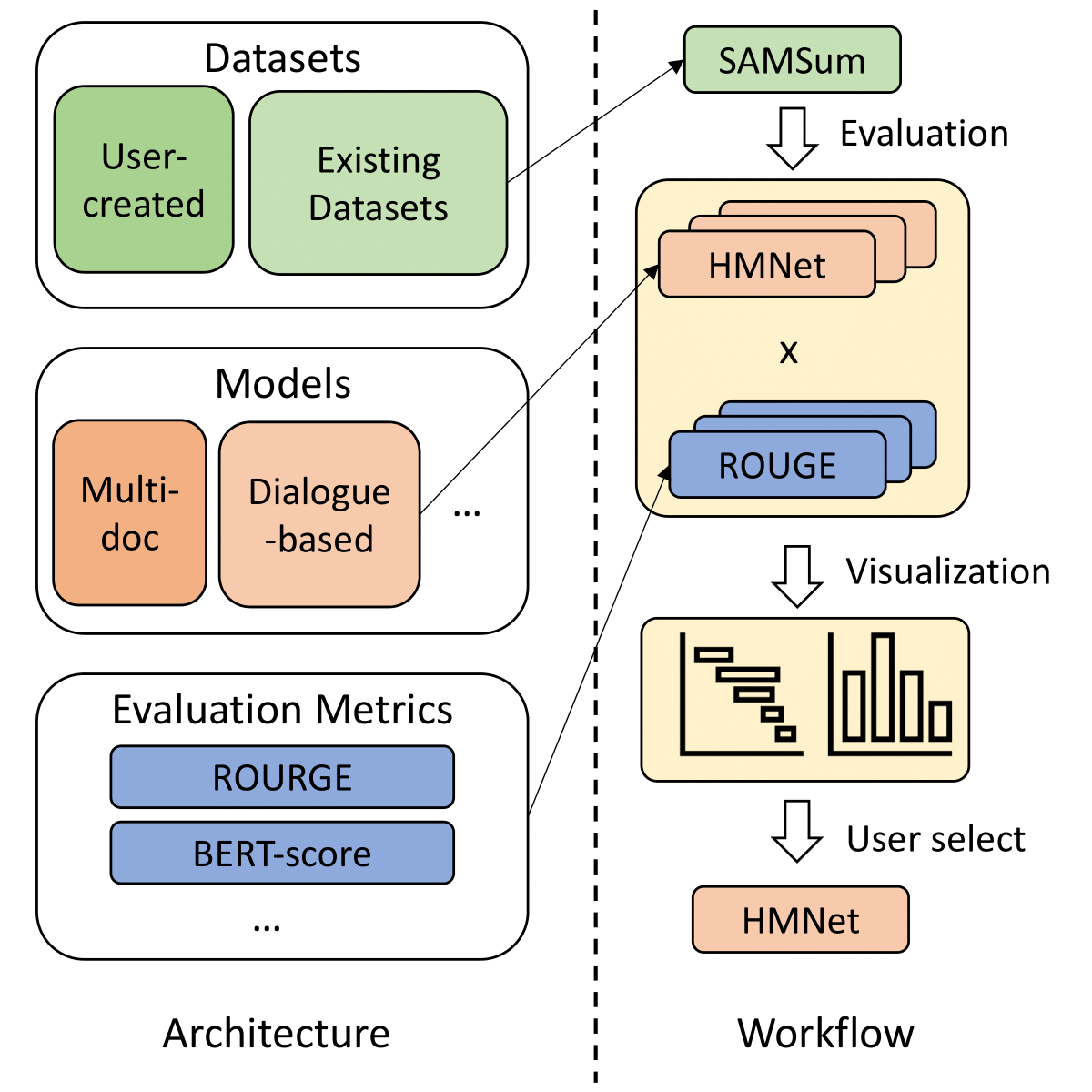
ESACL: Enhanced Seq2Seq Autoencoder via Contrastive Learning for AbstractiveText Summarization
This repo is for our paper "Enhanced Seq2Seq Autoencoder via Contrastive Learning for AbstractiveText Summarization". Our program is building on top of the Huggingface transformers framework. You can refer to their repo at: https://github.com/huggingface/transformers/tree/master/examples/seq2seq.
Local Setup
Tested with Python 3.7 via virtual environment. Clone the repo, go to the repo folder, setup the virtual environment, and install the required packages:
$ python3.7 -m venv venv
$ source venv/bin/activate
$ pip install -r requirements.txt
Install apex
Based on the recommendation from HuggingFace, both finetuning and eval are 30% faster with --fp16. For that you need to install apex.
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Data
Create a directory for data used in this work named data:
$ mkdir data
CNN/DM
$ wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
$ tar -xzvf cnn_dm_v2.tgz
$ mv cnn_cln data/cnndm
XSUM
$ wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
$ tar -xzvf xsum.tar.gz
$ mv xsum data/xsum
Generate Augmented Dataset
$ python generate_augmentation.py \
--dataset xsum \
--n 5 \
--augmentation1 randomdelete \
--augmentation2 randomswap
Training
CNN/DM
Our model is warmed up using sshleifer/distilbart-cnn-12-6:
$ DATA_DIR=./data/cnndm-augmented/RandominsertionRandominsertion-NumSent-3
$ OUTPUT_DIR=./log/cnndm
$ python -m torch.distributed.launch --nproc_per_node=3 cl_finetune_trainer.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--learning_rate=5e-7 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--do_train --do_eval \
--evaluation_strategy steps \
--freeze_embeds \
--save_total_limit 10 \
--save_steps 1000 \
--logging_steps 1000 \
--num_train_epochs 5 \
--model_name_or_path sshleifer/distilbart-cnn-12-6 \
--alpha 0.2 \
--temperature 0.5 \
--freeze_encoder_layer 6 \
--prediction_loss_only \
--fp16
XSUM
$ DATA_DIR=./data/xsum-augmented/RandomdeleteRandomswap-NumSent-3
$ OUTPUT_DIR=./log/xsum
$ python -m torch.distributed.launch --nproc_per_node=3 cl_finetune_trainer.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--learning_rate=5e-7 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--do_train --do_eval \
--evaluation_strategy steps \
--freeze_embeds \
--save_total_limit 10 \
--save_steps 1000 \
--logging_steps 1000 \
--num_train_epochs 5 \
--model_name_or_path sshleifer/distilbart-xsum-12-6 \
--alpha 0.2 \
--temperature 0.5 \
--freeze_encoder \
--prediction_loss_only \
--fp16
Evaluation
We have released the following checkpoints for pre-trained models as described in the paper:
CNN/DM
CNN/DM requires an extra postprocessing step.
$ export DATA=cnndm
$ export DATA_DIR=data/$DATA
$ export CHECKPOINT_DIR=./log/$DATA
$ export OUTPUT_DIR=output/$DATA
$ python -m torch.distributed.launch --nproc_per_node=2 run_distributed_eval.py \
--model_name sshleifer/distilbart-cnn-12-6 \
--save_dir $OUTPUT_DIR \
--data_dir $DATA_DIR \
--bs 16 \
--fp16 \
--use_checkpoint \
--checkpoint_path $CHECKPOINT_DIR
$ python postprocess_cnndm.py \
--src_file $OUTPUT_DIR/test_generations.txt \
--tgt_file $DATA_DIR/test.target
XSUM
$ export DATA=xsum
$ export DATA_DIR=data/$DATA
$ export CHECKPOINT_DIR=./log/$DATA
$ export OUTPUT_DIR=output/$DATA
$ python -m torch.distributed.launch --nproc_per_node=3 run_distributed_eval.py \
--model_name sshleifer/distilbart-xsum-12-6 \
--save_dir $OUTPUT_DIR \
--data_dir $DATA_DIR \
--bs 16 \
--fp16 \
--use_checkpoint \
--checkpoint_path $CHECKPOINT_DIR

 1.9k Jan 6, 2023
1.9k Jan 6, 2023

 211 Dec 28, 2022
211 Dec 28, 2022
 2.5k Feb 17, 2021
2.5k Feb 17, 2021


 1.2k Dec 30, 2022
1.2k Dec 30, 2022
 213 Jan 4, 2023
213 Jan 4, 2023

 9 Oct 14, 2022
9 Oct 14, 2022

 6 Oct 22, 2022
6 Oct 22, 2022


 83 Jan 9, 2023
83 Jan 9, 2023
 189 Jan 2, 2023
189 Jan 2, 2023
 10 Jul 1, 2022
10 Jul 1, 2022
 30 Dec 12, 2022
30 Dec 12, 2022
 19 Jun 30, 2022
19 Jun 30, 2022
 231 Nov 18, 2022
231 Nov 18, 2022
 1.4k Jan 2, 2023
1.4k Jan 2, 2023
 159 Apr 4, 2022
159 Apr 4, 2022
 3k Jan 8, 2023
3k Jan 8, 2023