Problem
Cannot access the RedShift cluster endpoint from the SageMaker Studio in workshop/04_ingest/07_Load_TSV_Data_From_Athena_Into_Redshift.ipynb
.
Related
Opened a StackOverflow question
Steps
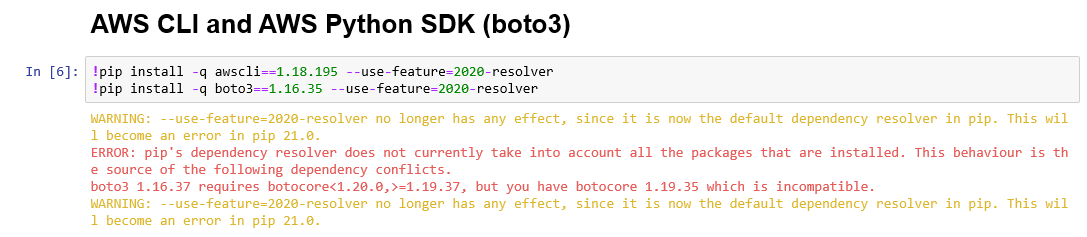
Follow the notebook. The previous steps have been done successfully except having to install !pip install psycopg2-binary.
The RedShift cluster is available.
redshift_cluster_identifier = 'dsoaws'
database_name_redshift = 'dsoaws'
database_name_athena = 'dsoaws'
redshift_port = '5439'
schema_redshift = 'redshift'
schema_athena = 'athena'
table_name_tsv = 'amazon_reviews_tsv'
import time
response = redshift.describe_clusters(ClusterIdentifier=redshift_cluster_identifier)
cluster_status = response['Clusters'][0]['ClusterStatus']
print(cluster_status)
while cluster_status != 'available':
time.sleep(10)
response = redshift.describe_clusters(ClusterIdentifier=redshift_cluster_identifier)
cluster_status = response['Clusters'][0]['ClusterStatus']
print(cluster_status)
---
available
However, cannot execute SQL as the connection fails.
statement = """
CREATE EXTERNAL SCHEMA IF NOT EXISTS {} FROM DATA CATALOG
DATABASE '{}'
IAM_ROLE '{}'
REGION '{}'
CREATE EXTERNAL DATABASE IF NOT EXISTS
""".format(schema_athena, database_name_athena, iam_role, region_name)
print(statement)
-----
CREATE EXTERNAL SCHEMA IF NOT EXISTS athena FROM DATA CATALOG
DATABASE 'dsoaws'
IAM_ROLE 'arn:aws:iam::316725000538:role/DSOAWS_Redshift'
REGION 'us-east-2'
CREATE EXTERNAL DATABASE IF NOT EXISTS
-----
s.execute(statement)
s.commit()
-----
The connection to the RedShift cluster endpoint is not open. But the RedShift cluster accepts the connection from Security Group sg-56cb133e which allows all inbounds from sg-56cb133e, and all outbounds.
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = sock.connect_ex(('dsoaws.cw7xniw3gvef.us-east-2.redshift.amazonaws.com',5439))
if result == 0:
print("Port is open")
else:
print("Port is not open")
sock.close()
---
Port is not open
Error at s.commit().
---------------------------------------------------------------------------
OperationalError Traceback (most recent call last)
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/base.py in _wrap_pool_connect(self, fn, connection)
2275 try:
-> 2276 return fn()
2277 except dialect.dbapi.Error as e:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in connect(self)
362 if not self._use_threadlocal:
--> 363 return _ConnectionFairy._checkout(self)
364
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in _checkout(cls, pool, threadconns, fairy)
772 if not fairy:
--> 773 fairy = _ConnectionRecord.checkout(pool)
774
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in checkout(cls, pool)
491 def checkout(cls, pool):
--> 492 rec = pool._do_get()
493 try:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/impl.py in _do_get(self)
138 with util.safe_reraise():
--> 139 self._dec_overflow()
140 else:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/util/langhelpers.py in __exit__(self, type_, value, traceback)
67 if not self.warn_only:
---> 68 compat.reraise(exc_type, exc_value, exc_tb)
69 else:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/util/compat.py in reraise(tp, value, tb, cause)
152 raise value.with_traceback(tb)
--> 153 raise value
154
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/impl.py in _do_get(self)
135 try:
--> 136 return self._create_connection()
137 except:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in _create_connection(self)
307
--> 308 return _ConnectionRecord(self)
309
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in __init__(self, pool, connect)
436 if connect:
--> 437 self.__connect(first_connect_check=True)
438 self.finalize_callback = deque()
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in __connect(self, first_connect_check)
651 self.starttime = time.time()
--> 652 connection = pool._invoke_creator(self)
653 pool.logger.debug("Created new connection %r", connection)
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/strategies.py in connect(connection_record)
113 return connection
--> 114 return dialect.connect(*cargs, **cparams)
115
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/default.py in connect(self, *cargs, **cparams)
488 def connect(self, *cargs, **cparams):
--> 489 return self.dbapi.connect(*cargs, **cparams)
490
/opt/conda/lib/python3.7/site-packages/psycopg2/__init__.py in connect(dsn, connection_factory, cursor_factory, **kwargs)
121 dsn = _ext.make_dsn(dsn, **kwargs)
--> 122 conn = _connect(dsn, connection_factory=connection_factory, **kwasync)
123 if cursor_factory is not None:
OperationalError: could not connect to server: Connection timed out
Is the server running on host "dsoaws.cw7xniw3gvef.us-east-2.redshift.amazonaws.com" (172.31.43.160) and accepting
TCP/IP connections on port 5439?
The above exception was the direct cause of the following exception:
OperationalError Traceback (most recent call last)
<ipython-input-20-2959b0ded50f> in <module>
----> 1 s.execute(statement)
2 s.commit()
/opt/conda/lib/python3.7/site-packages/sqlalchemy/orm/session.py in execute(self, clause, params, mapper, bind, **kw)
1275 bind = self.get_bind(mapper, clause=clause, **kw)
1276
-> 1277 return self._connection_for_bind(bind, close_with_result=True).execute(
1278 clause, params or {}
1279 )
/opt/conda/lib/python3.7/site-packages/sqlalchemy/orm/session.py in _connection_for_bind(self, engine, execution_options, **kw)
1137 if self.transaction is not None:
1138 return self.transaction._connection_for_bind(
-> 1139 engine, execution_options
1140 )
1141 else:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/orm/session.py in _connection_for_bind(self, bind, execution_options)
430 )
431 else:
--> 432 conn = bind._contextual_connect()
433 local_connect = True
434
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/base.py in _contextual_connect(self, close_with_result, **kwargs)
2240 return self._connection_cls(
2241 self,
-> 2242 self._wrap_pool_connect(self.pool.connect, None),
2243 close_with_result=close_with_result,
2244 **kwargs
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/base.py in _wrap_pool_connect(self, fn, connection)
2278 if connection is None:
2279 Connection._handle_dbapi_exception_noconnection(
-> 2280 e, dialect, self
2281 )
2282 else:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/base.py in _handle_dbapi_exception_noconnection(cls, e, dialect, engine)
1545 util.raise_from_cause(newraise, exc_info)
1546 elif should_wrap:
-> 1547 util.raise_from_cause(sqlalchemy_exception, exc_info)
1548 else:
1549 util.reraise(*exc_info)
/opt/conda/lib/python3.7/site-packages/sqlalchemy/util/compat.py in raise_from_cause(exception, exc_info)
396 exc_type, exc_value, exc_tb = exc_info
397 cause = exc_value if exc_value is not exception else None
--> 398 reraise(type(exception), exception, tb=exc_tb, cause=cause)
399
400
/opt/conda/lib/python3.7/site-packages/sqlalchemy/util/compat.py in reraise(tp, value, tb, cause)
150 value.__cause__ = cause
151 if value.__traceback__ is not tb:
--> 152 raise value.with_traceback(tb)
153 raise value
154
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/base.py in _wrap_pool_connect(self, fn, connection)
2274 dialect = self.dialect
2275 try:
-> 2276 return fn()
2277 except dialect.dbapi.Error as e:
2278 if connection is None:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in connect(self)
361 """
362 if not self._use_threadlocal:
--> 363 return _ConnectionFairy._checkout(self)
364
365 try:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in _checkout(cls, pool, threadconns, fairy)
771 def _checkout(cls, pool, threadconns=None, fairy=None):
772 if not fairy:
--> 773 fairy = _ConnectionRecord.checkout(pool)
774
775 fairy._pool = pool
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in checkout(cls, pool)
490 @classmethod
491 def checkout(cls, pool):
--> 492 rec = pool._do_get()
493 try:
494 dbapi_connection = rec.get_connection()
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/impl.py in _do_get(self)
137 except:
138 with util.safe_reraise():
--> 139 self._dec_overflow()
140 else:
141 return self._do_get()
/opt/conda/lib/python3.7/site-packages/sqlalchemy/util/langhelpers.py in __exit__(self, type_, value, traceback)
66 self._exc_info = None # remove potential circular references
67 if not self.warn_only:
---> 68 compat.reraise(exc_type, exc_value, exc_tb)
69 else:
70 if not compat.py3k and self._exc_info and self._exc_info[1]:
/opt/conda/lib/python3.7/site-packages/sqlalchemy/util/compat.py in reraise(tp, value, tb, cause)
151 if value.__traceback__ is not tb:
152 raise value.with_traceback(tb)
--> 153 raise value
154
155 def u(s):
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/impl.py in _do_get(self)
134 if self._inc_overflow():
135 try:
--> 136 return self._create_connection()
137 except:
138 with util.safe_reraise():
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in _create_connection(self)
306 """Called by subclasses to create a new ConnectionRecord."""
307
--> 308 return _ConnectionRecord(self)
309
310 def _invalidate(self, connection, exception=None, _checkin=True):
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in __init__(self, pool, connect)
435 self.__pool = pool
436 if connect:
--> 437 self.__connect(first_connect_check=True)
438 self.finalize_callback = deque()
439
/opt/conda/lib/python3.7/site-packages/sqlalchemy/pool/base.py in __connect(self, first_connect_check)
650 try:
651 self.starttime = time.time()
--> 652 connection = pool._invoke_creator(self)
653 pool.logger.debug("Created new connection %r", connection)
654 self.connection = connection
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/strategies.py in connect(connection_record)
112 if connection is not None:
113 return connection
--> 114 return dialect.connect(*cargs, **cparams)
115
116 creator = pop_kwarg("creator", connect)
/opt/conda/lib/python3.7/site-packages/sqlalchemy/engine/default.py in connect(self, *cargs, **cparams)
487
488 def connect(self, *cargs, **cparams):
--> 489 return self.dbapi.connect(*cargs, **cparams)
490
491 def create_connect_args(self, url):
/opt/conda/lib/python3.7/site-packages/psycopg2/__init__.py in connect(dsn, connection_factory, cursor_factory, **kwargs)
120
121 dsn = _ext.make_dsn(dsn, **kwargs)
--> 122 conn = _connect(dsn, connection_factory=connection_factory, **kwasync)
123 if cursor_factory is not None:
124 conn.cursor_factory = cursor_factory
OperationalError: (psycopg2.OperationalError) could not connect to server: Connection timed out
Is the server running on host "dsoaws.cw7xniw3gvef.us-east-2.redshift.amazonaws.com" (172.31.43.160) and accepting
TCP/IP connections on port 5439?
(Background on this error at: http://sqlalche.me/e/e3q8)
AWS
Region is us-east-2





























 3.1k Jan 6, 2023
3.1k Jan 6, 2023
 8.9k Jan 9, 2023
8.9k Jan 9, 2023
 84 Nov 25, 2022
84 Nov 25, 2022
 8.1k Dec 30, 2022
8.1k Dec 30, 2022
 19 Oct 3, 2022
19 Oct 3, 2022
 366 Jan 3, 2023
366 Jan 3, 2023
 152 Jan 7, 2023
152 Jan 7, 2023
 5.7k Dec 30, 2022
5.7k Dec 30, 2022
 3.8k Jan 9, 2023
3.8k Jan 9, 2023
 2 Aug 23, 2022
2 Aug 23, 2022
 0 Jan 31, 2022
0 Jan 31, 2022
 3k Jan 8, 2023
3k Jan 8, 2023
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
 4.2k Dec 29, 2022
4.2k Dec 29, 2022
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
 121 Dec 28, 2022
121 Dec 28, 2022
 124 Dec 28, 2022
124 Dec 28, 2022
 14 Mar 30, 2022
14 Mar 30, 2022
 2 Dec 10, 2021
2 Dec 10, 2021