NormCap
OCR powered screen-capture tool to capture information instead of images.
![]()
Links: Repo | PyPi | Releases | Changelog | FAQs
Content: Quickstart | Python package | Usage | Contribute | Credits
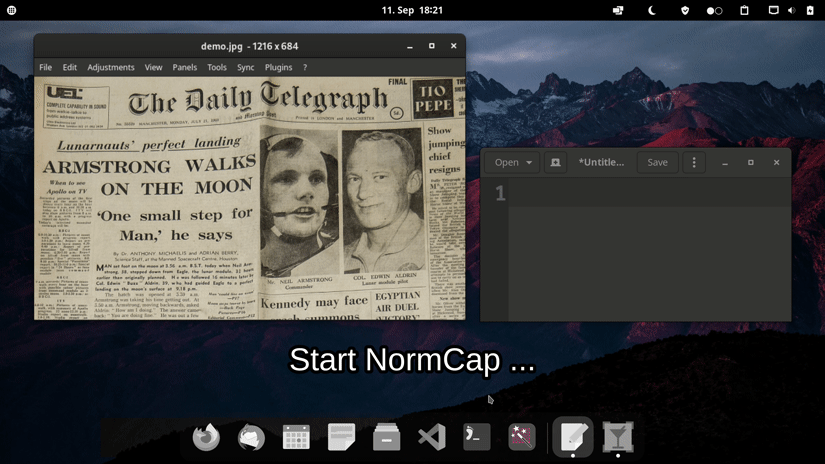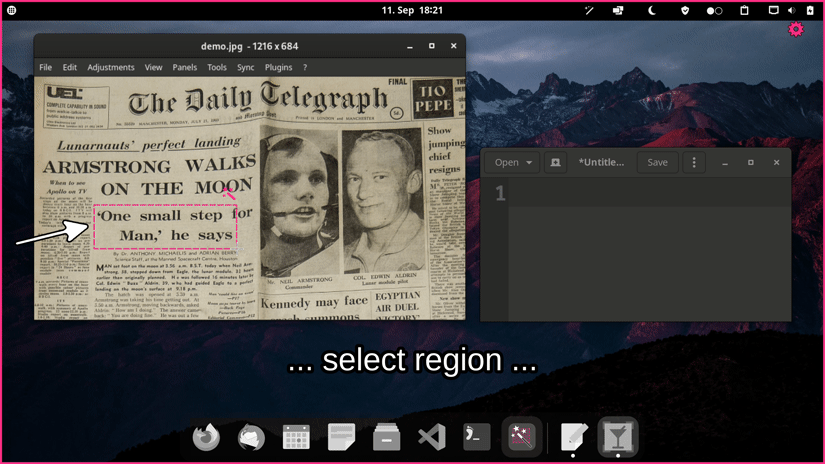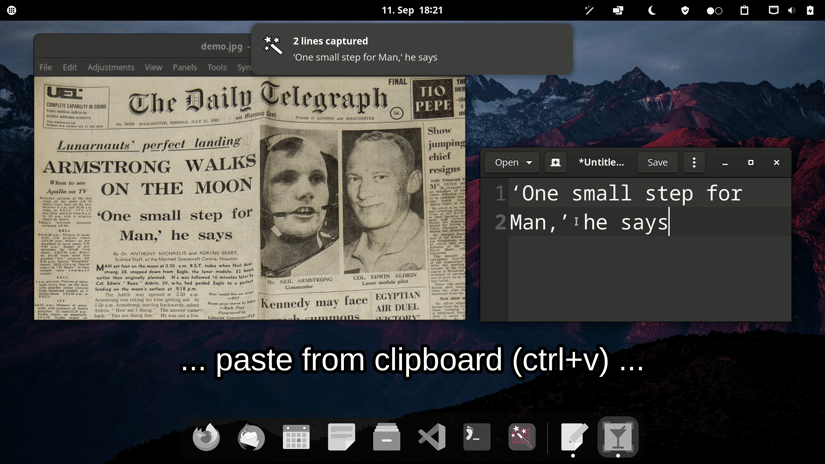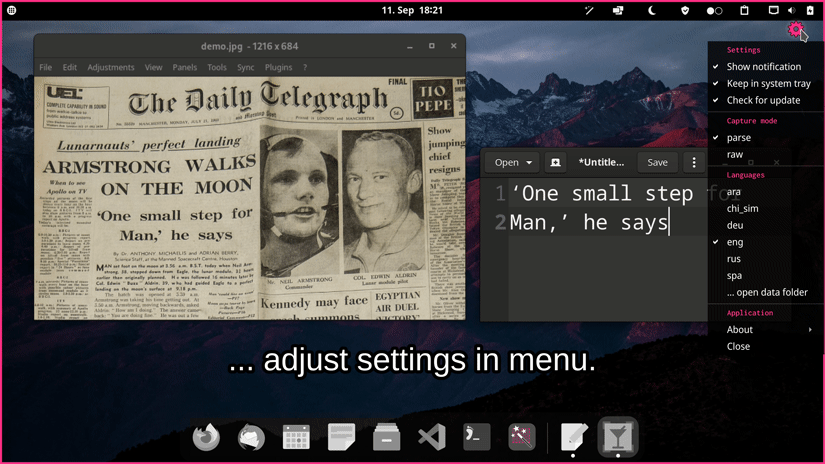
Features
- On-screen recognition of selected text
- Multi platform support for Linux, Windows, MacOS
- Multi monitor support, incl. HDPI displays
- "Magically" parsing the text (optional, on by default)
- Show notifications (optional)
- Stay in system tray (optional)
- Check for updates (optional, off by default)
Quickstart
❱❱ Download & run a pre-build package for Linux, MacOS or Windows ❰❰
If you experience issues please look at the FAQs or open an issue.
(On MacOS, allow the unsigned application on first start: "System Preferences" → "Security & Privacy" → "General" → "Open anyway". You might also need to allow NormCap to take screenshots.)
Python package
As an alternative to a pre-build package you can install the NormCap Python package:
On Linux
# Install dependencies (Ubuntu/Debian)
sudo apt install tesseract-ocr tesseract-ocr-eng \
libtesseract-dev libleptonica-dev \
python3-dev
## Install dependencies (Arch)
sudo pacman -S tesseract tesseract-data-eng leptonica
## Install dependencies (Fedora)
sudo dnf install tesseract tesseract-devel \
libleptonica-devel python3-devel
# Install normcap
pip install normcap
# Run
./normcap
On MacOS
# Install dependencies
brew install tesseract tesseract-lang
# Install normcap
pip install normcap
# Run
./normcap
On Windows
1. Install "Tesseract 4.1", e.g. by using the installer provided by UB Mannheim.
2. Set the environment variable TESSDATA_PREFIX to Tesseract's data folder, e.g.:
setx TESSDATA_PREFIX "C:\Program Files\Tesseract-OCR\tessdata"
3. Install tesserocr using the Windows specific wheel and NormCap afterwards:
# Install tesserocr package
pip install https://github.com/simonflueckiger/tesserocr-windows_build/releases/download/tesserocr-v2.4.0-tesseract-4.0.0/tesserocr-2.4.0-cp37-cp37m-win_amd64.whl
# Install normcap
pip install normcap
# Run
normcap
Usage
General
-
Select a region on screen with your mouse to perform text recognition
-
Press
<esc>key to abort a capture and quit the application.
Magics
"Magics" are like add-ons providing automated functionality to intelligently detect and format the captured input.
First, every "magic" calculates a "score" to determine the likelihood of being responsible for this type of text. Second, the "magic" which achieved the highest "score" takes the necessary actions to "transform" the input text according to its type.
Currently implemented Magics:
| Magic | Score | Transform |
|---|---|---|
| Single line | Only single line is detected | Trim unnecessary whitespace |
| Multi line | Multi lines, but single Paragraph | Separated by line breaks and trim each lined |
| Paragraph | Multiple blocks of lines or multiple paragraphs | Join every paragraph into a single line, separate different paragraphs by empty line |
| Number of chars in email addresses vs. overall chars | Transform to a comma-separated list of email addresses | |
| URL | Number of chars in URLs vs. overall chars | Transform to line-break separated URLs |
Why "NormCap"?
See XKCD:

Contribute
Setup Environment
Prerequisites are Python >=3.7.1, Poetry, Tesseract (incl. language data).
# Clone repository
git clone https://github.com/dynobo/normcap.git
# Change into project directory
cd normcap
# Create virtual env and install dependencies
poetry install
# Register pre-commit hook
poetry run pre-commit install
# Run NormCap in virtual env
poetry run python -m normcap
Credits
This project uses the following non-standard libraries:
- pyside2 - bindings for Qt UI Framework
- tesserocr - wrapper for tesseract's API
- jeepney - DBUS client
Packaging is done with:
- briefcase - converting Python projects into standalone apps
And it depends on external software
- tesseract - OCR engine
Thanks to the maintainers of those nice libraries!
Certification
![]()

![[ERROR] Not launching in Fedora 35 Wayland](https://avatars.githubusercontent.com/u/57890520?v=4)



![[flatpak] Fails to start in Ubuntu Unity with](https://avatars.githubusercontent.com/u/3063132?v=4)

![[Feature Request] Would a flatpak package distribution be possible?](https://avatars.githubusercontent.com/u/67047467?v=4)

![[Linux] Latest version ( 0.3.7 ) doesn't copy text to clipboard](https://avatars.githubusercontent.com/u/1454420?v=4)
![[Win 10] Normcap windows notifications can't turned back on](https://avatars.githubusercontent.com/u/74261395?v=4)

 It seems to be inline with issue 126 over on giters, although it wasn't fixed for me by enabling the compositor (it was never off), and I know that I can have transparent windows, asl GLava works fine.
Here's my logs:
It seems to be inline with issue 126 over on giters, although it wasn't fixed for me by enabling the compositor (it was never off), and I know that I can have transparent windows, asl GLava works fine.
Here's my logs:![[Linux]](https://avatars.githubusercontent.com/u/32822588?v=4)


 1 Feb 13, 2022
1 Feb 13, 2022
 311 Dec 24, 2022
311 Dec 24, 2022
 27.5k Jan 8, 2023
27.5k Jan 8, 2023
 5 Dec 6, 2021
5 Dec 6, 2021
 684 Jan 6, 2023
684 Jan 6, 2023
 2 Apr 16, 2022
2 Apr 16, 2022
 144 Jan 5, 2023
144 Jan 5, 2023
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
 4 Aug 6, 2021
4 Aug 6, 2021
 2 Nov 16, 2022
2 Nov 16, 2022
 32 Jul 24, 2022
32 Jul 24, 2022
 40 Dec 20, 2022
40 Dec 20, 2022
 1 Dec 7, 2021
1 Dec 7, 2021
 4 Oct 18, 2022
4 Oct 18, 2022
 4 Nov 10, 2021
4 Nov 10, 2021
 1 Jan 7, 2022
1 Jan 7, 2022
 1.8k Dec 28, 2022
1.8k Dec 28, 2022
 1 Jan 13, 2022
1 Jan 13, 2022
 16.7k Jan 3, 2023
16.7k Jan 3, 2023