Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar
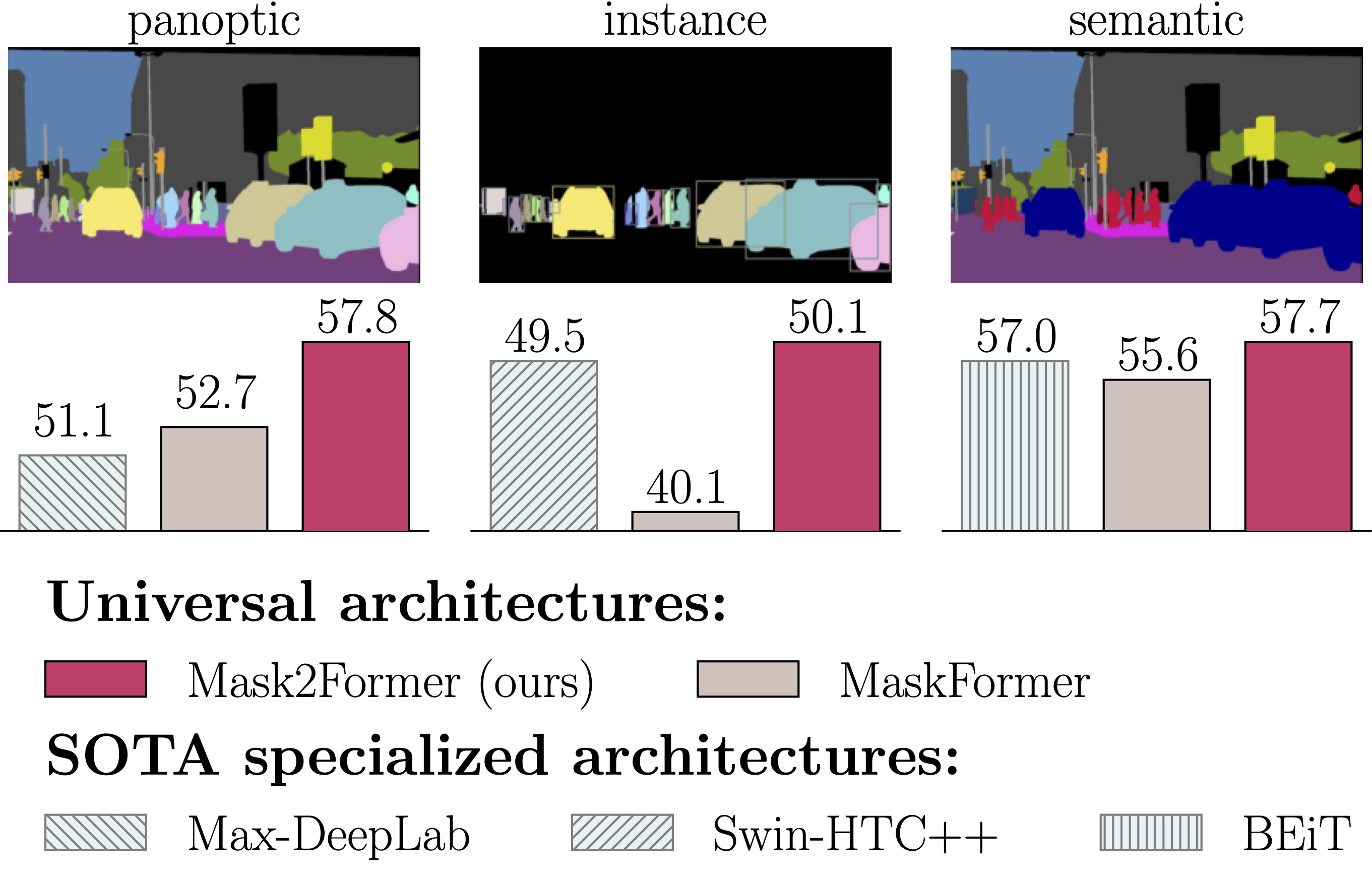
Features
- A single architecture for panoptic, instance and semantic segmentation.
- Support major segmentation datasets: ADE20K, Cityscapes, COCO, Mapillary Vistas.
Installation
See installation instructions.
Getting Started
See Preparing Datasets for Mask2Former.
See Getting Started with Mask2Former.
Advanced usage
See Advanced Usage of Mask2Former.
Model Zoo and Baselines
We provide a large set of baseline results and trained models available for download in the Mask2Former Model Zoo.
License
Shield:
The majority of Mask2Former is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.

However portions of the project are available under separate license terms: Swin-Transformer-Semantic-Segmentation is licensed under the MIT license, Deformable-DETR is licensed under the Apache-2.0 License.
Citing Mask2Former
If you use Mask2Former in your research or wish to refer to the baseline results published in the Model Zoo, please use the following BibTeX entry.
@article{cheng2021mask2former,
title={Masked-attention Mask Transformer for Universal Image Segmentation},
author={Bowen Cheng and Ishan Misra and Alexander G. Schwing and Alexander Kirillov and Rohit Girdhar},
journal={arXiv},
year={2021}
}
If you find the code useful, please also consider the following BibTeX entry.
@inproceedings{cheng2021maskformer,
title={Per-Pixel Classification is Not All You Need for Semantic Segmentation},
author={Bowen Cheng and Alexander G. Schwing and Alexander Kirillov},
journal={NeurIPS},
year={2021}
}
Acknowledgement
Code is largely based on MaskFormer (https://github.com/facebookresearch/MaskFormer).





 was lower that the result from Table 1 in the paper,
was lower that the result from Table 1 in the paper,
 could you help me see what is the reason for this ^ ^
could you help me see what is the reason for this ^ ^





 But when I run the code:
But when I run the code:
 It doesnt work successifully. It makes an ImportError
It doesnt work successifully. It makes an ImportError












 56 Dec 28, 2022
56 Dec 28, 2022
 66 Dec 16, 2022
66 Dec 16, 2022
 89 Dec 10, 2022
89 Dec 10, 2022
 360 Jan 6, 2023
360 Jan 6, 2023
 12 Nov 30, 2022
12 Nov 30, 2022
 93 Nov 8, 2022
93 Nov 8, 2022
 18 May 27, 2022
18 May 27, 2022
 95 Jan 8, 2023
95 Jan 8, 2023
 53 Dec 24, 2022
53 Dec 24, 2022
 524 Jan 8, 2023
524 Jan 8, 2023
 41 May 18, 2022
41 May 18, 2022
 23 Dec 7, 2022
23 Dec 7, 2022
 101 Dec 11, 2022
101 Dec 11, 2022
 68 Dec 14, 2022
68 Dec 14, 2022
 230 Dec 31, 2022
230 Dec 31, 2022
 813 Jan 4, 2023
813 Jan 4, 2023
 40 Dec 30, 2022
40 Dec 30, 2022
 24 Dec 17, 2022
24 Dec 17, 2022