Improving Graph Neural Network Expressivity via Subgraph Isomorphism Counting
Official PyTorch implementation of the paper:
Improving Graph Neural Network Expressivity via Subgraph Isomorphism Counting.
Giorgos Bouritsas, Fabrizio Frasca, Stefanos Zafeiriou, Michael M. Bronstein.
https://arxiv.org/abs/2006.09252
tl;dr: We provably improve GNN expressivity by enhancing message passing with substructure encodings. Our method allows incorporating domain specific prior knowledge and can be used as a drop-in replacement of traditional GNN layers in order to boost their performance in a variety of applications (molecules, social networks, etc.)

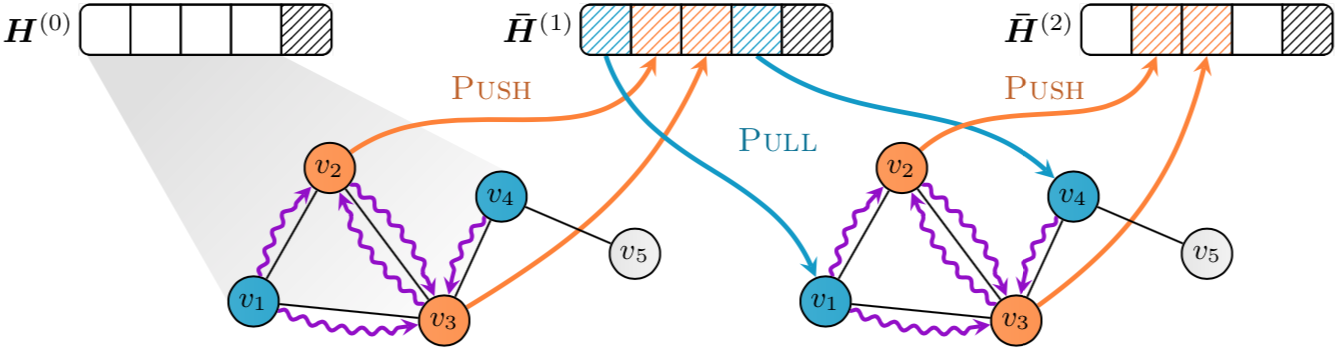
Abstract: While Graph Neural Networks (GNNs) have achieved remarkable results in a variety of applications, recent studies exposed important shortcomings in their ability to capture the structure of the underlying graph. It has been shown that the expressive power of standard GNNs is bounded by the Weisfeiler-Lehman (WL) graph isomorphism test, from which they inherit proven limitations such as the inability to detect and count graph substructures. On the other hand, there is significant empirical evidence, e.g. in network science and bioinformatics, that substructures are often informative for downstream tasks, suggesting that it is desirable to design GNNs capable of leveraging this important source of information. To this end, we propose a novel topologically-aware message passing scheme based on substructure encoding. We show that our architecture allows incorporating domain-specific inductive biases and that it is strictly more expressive than the WL test. Importantly, in contrast to recent works on the expressivity of GNNs, we do not attempt to adhere to the WL hierarchy; this allows us to retain multiple attractive properties of standard GNNs such as locality and linear network complexity, while being able to disambiguate even hard instances of graph isomorphism. We extensively evaluate our method on graph classification and regression tasks and show state-of-the-art results on multiple datasets including molecular graphs and social networks.
Dependencies and Installation Instructions
Requirements:
- python 3.7
- pytorch>=1.4.0
- cudatoolkit>=10.0
- pytorch geometric>=1.4.3 (data preprocessing and data loaders)
- graph-tool (subgraph isomorphism)
- tqdm
- ogb>=1.1.1 (experiments on the ogb datasets)
- wandb (optional: experiment monitoring)
NB: Different pytorch and cuda versions will affect the seeds and thus the exact reproducibility of the results (altough the differences are usually quite small).
Recommended setup installations:
conda create --name gsn python=3.7
conda activate gsn
conda install pytorch==1.4.0 cudatoolkit=10.0 -c pytorch
pip install torch-scatter==latest+cu100 -f https://pytorch-geometric.com/whl/torch-1.4.0.html
pip install torch-sparse==latest+cu100 -f https://pytorch-geometric.com/whl/torch-1.4.0.html
pip install torch-cluster==latest+cu100 -f https://pytorch-geometric.com/whl/torch-1.4.0.html
pip install torch-geometric
conda install -c conda-forge graph-tool
pip install ogb
pip install tqdm
pip install wandb
pip install tensorboardX
Datasets - Usage Examples
For each family of experiments we provide instructions in order to generate the data. All necessary files (e.g. splits) are provided in this repository. We also provide usage examples for 1) synthetic data: using gsn to test graph isomoprhism, 2) TU Datasets: classical graph classification datasets (molecules, protein contact maps, social networks), 3) ZINC: molecular solubility prediction, 4) OGB-MOLHIV: molecular property prediction (ability to inhibit HIV or not)
In order to perform the precomputation of the substructure counts in parallel set: --multiprocessing True and --num_processes N where N the number of threads to spawn.
How to define the substructures?
We provide three main functionalities in order to define the substructures that will be counted:
- Using networkx generators: you can define a networkx graph generator family, such as cycle_graph, path_graph, complete_graph, etc. (consults utils.py for the supported generators) by setting e.g. --id type cycle_graph. This will count all the subgraphs of the family that have size up to k (e.g. --k 5). If a single size is required set e.g. --id type cycle_graph_chosen_k.
- By providing the subgraphs in .g6 files: For example, in ./datasets/all_simple_graphs we provide .g6 files that contain all connected graphs of a certain size (obtained again from here http://users.cecs.anu.edu.au/~bdm/data/graphs.html). The by setting --id type all_simple_graphs and e.g. --k 5, all files with k up to 5 will be loaded. Similarly here, to obtain a single size use --id type all_simple_graphs_chosen_k.
- By custom edge lists: The user can define custom edge lists in the command line as follows: --id_type custom, e.g. --custom_edge_list --id_type custom --custom_edge_list 0,2,,1,2,,,0,1,,1,2,,2,3,,3,4 (i.e. delimiter between two edges: ',,' and between two edge lists ',,,'. Here we get edge_list1 = [[0,2],[1,2]] and edge_list2 = [[0,1],[1,2],[2,3],[3,4]])
Other important command line arguments: --induced: set to True for graphlets, False for motifs, --id_scope: set to local for GSN-e (edge counts), global for GSN-v (vertex counts)
Graph Isomoprhism Testing
In this repository, we provide an exemplary family of Strongly Regular (SR) graphs, i.e. SR(25,12,5,6). The rest of the SR families can be downloaded from here: http://users.cecs.anu.edu.au/~bdm/data/graphs.html . In the paper we used SR graphs of size up to 35. By running the command below you can run an isomorphism test with GSN (with random weights) that will try to distinguish all available pairs from the family. Other substructure configurations can be tested, e.g. by setting --id_type to path_graph, complete_graph, etc., --induced to True or False (graphlets vs. motifs), --k to any positive integer number to define the size of the largest substructure, --id_scope to local or global (GSN-e vs GSN-v).
The expected results from the following command is 0% failure.
python main.py --seed 0 --dataset SR_graphs --dataset_name sr251256 --root_folder ./datasets --id_type cycle_graph --induced True --k 6 --id_scope local --id_embedding one_hot_encoder --model_name GSN_sparse --num_layers 2 --d_out 64 --msg_kind general --bn False --readout sum --final_projection False --jk_mlp True --mode isomorphism_test --device_idx 0 --wandb False
To test a traditional GNN (expected result: 100% failure), run the following command:
python main.py --seed 0 --dataset SR_graphs --dataset_name sr251256 --root_folder ./datasets --model_name MPNN_sparse --num_layers 2 --d_out 64 --msg_kind general --bn False --readout sum --final_projection False --jk_mlp True --mode isomorphism_test --device_idx 0 --wandb False
(NB: when running a traditional GNN the substructure defined by the default parameters will be counted, but the identifiers won't be used by the network)
TUD Datasets
We provide the raw data, split indices and preprocessed data for one of the TU datasets used in the paper (IMDBBINARY). The rest of the datasets (raw data and split indices) can be obtained from https://github.com/weihua916/powerful-gnns . The datasets are split into two categories: 'social' (IMDBBINARY, IMDBMULTI, COLLAB) and 'bioinformatics' (PTC, PROTEINS, NCI1, MUTAG). The names of the categories are used for the parent folders. We provide the command that performs the evaluation procedure mentioned in the supplementary material (cross-validation), with the best performing hyperparameters.
python main.py --seed 0 --onesplit False --dataset social --dataset_name IMDBBINARY --root_folder ./datasets --degree_as_tag False --id_type complete_graph --induced False --k 5 --id_scope local --id_encoding one_hot_unique --id_embedding one_hot_encoder --model_name GSN_sparse --msg_kind gin --num_layers 4 --d_out 64 --dropout_features 0 --final_projection True --jk_mlp False --readout mean --batch_size 32 --num_epochs 300 --num_iters 50 --lr 1e-3 --decay_steps 10 --decay_rate 0.5 --mode train --device_idx 0 --wandb False
ZINC
For the ZINC dataset, the raw data can be obtained from https://github.com/graphdeeplearning/benchmarking-gnns by running the following commands in the ./datasets/chemical/ZINC/ folder:
cd ./datasets/chemical/ZINC/
curl https://www.dropbox.com/s/feo9qle74kg48gy/molecules.zip?dl=1 -o molecules.zip -J -L -k
unzip molecules.zip -d ./
We provide the split indices (obtained from the same repository). Preprocessed data will be computed before starting the training by running the following command:
python main.py --seed 0 --onesplit True --dataset chemical --dataset_name ZINC --root_folder ./datasets --id_type cycle_graph --induced False --k 8 --id_scope global --id_encoding one_hot_unique --id_embedding one_hot_encoder --input_node_encoder one_hot_encoder --edge_encoder one_hot_encoder --model_name GSN_edge_sparse --msg_kind general --num_layers 4 --d_out 128 --dropout_features 0 --final_projection False --jk_mlp True --readout sum --batch_size 128 --num_epochs 1000 --lr 1e-3 --scheduler ReduceLROnPlateau --decay_rate 0.5 --patience 5 --min_lr 1e-5 --regression True --loss_fn L1Loss --prediction_fn L1Loss --mode train --device_idx 0 --wandb False
This will train and evaluate our best GSN-EF model (i.e. general MPNN formulation with edge features and structural identifiers) as described in the supplementary material (result reported in Table 2 of the main paper). In order to obtain the mean and standard deviation reported in the paper, you will need to run the above command 10 times by changing the seed to 1,2,...,9.
OGBG MOL-HIV
For the MOL-HIV dataset, the raw data will be downloaded automatically before starting the training. We provide the split indices (obtained from the authors of OGB https://ogb.stanford.edu/). Preprocessed data will be computed before starting the training by running the following command:
python main.py --seed 0 --onesplit True --dataset ogb --dataset_name ogbg-molhiv --root_folder ./datasets --features_scope full --vn True --id_type cycle_graph --induced True --k 6 --id_scope local --id_encoding one_hot_unique --id_embedding embedding --input_node_encoder atom_encoder --edge_encoder bond_encoder --input_vn_encoder embedding --model_name GSN_edge_sparse_ogb --msg_kind ogb --num_layers 5 --d_out 300 --d_h 600 --dropout_features 0.5 --final_projection False --jk_mlp False --readout mean --batch_size 32 --num_epochs 100 --lr 1e-3 --scheduler None --loss_fn BCEWithLogitsLoss --prediction_fn multi_class_accuracy --mode train --device_idx 0 --wandb False
This will train and evaluate our best GSN-VN-AF model (i.e. virtual node & additional features) as described in the supplementary material (results reported in Table 3 of the main paper). In order to obtain the mean and standard deviation reported in the paper, you will need to run the above command 10 times by changing the seed to 1,2,...,9.
Results
By following the instructions above to train our models on each of the datasets, the following results are expected:
+----------------------------------------------------------+
| Dataset | Performance |
|---|---|
| SR(25,12,5,6) | 0% Failure Percentage |
| IMDBBINARY | 77.8% ± 3.3% Accuracy |
| ZINC | 0.108 ± 018 Mean Absolute Error |
| MOL-HIV | 77.99% ± 1.00% ROC-AUC |
| +----------------------------------------------------------+ |
The rest of the results reported in the main paper can be obtained accordingly, i.e. by changing the hyperparameters as per the supplementary material.
Update (June'21)
We extended the repo with a new set of experiments: (1) GSN with 100K parameters and 500K on the ZINC dataset as instructed in the official leaderboard. (2) Combination of GSN with DGN, where we defined a vector field based on structural features instead of eigenvectors. The code can be found in the directional_gsn folder. Please use the following installation instructions to reproduce the results:
conda create --name gsn python=3.7
conda activate gsn
conda install pytorch==1.8.0 cudatoolkit=10.2 -c pytorch
pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.8.0+cu102.html
pip install torch-sparse -f https://pytorch-geometric.com/whl/torch-1.8.0+cu102.html
pip install torch-cluster -f https://pytorch-geometric.com/whl/torch-1.8.0+cu102.html
pip install torch-geometric
conda install -c conda-forge graph-tool
pip install ogb
pip install tqdm
pip install wandb
conda install -c dglteam dgl-cuda10.2
Then, run the following commands. The expected results are the following:
- ZINC 100K 0.115 ± 0.012 ,
- ZINC 500K 0.101 ± 0.010,
- molhiv 100K 0.8039±0.0090
ZINC 100K
cd scripts
python ZINC_10_runs_100K.py
ZINC 500K
cd scripts
python ZINC_10_runs_500K.py
directional GSN (molhiv)
cd directional_gsn
source molhiv_10_runs.sh
Citation
If you find our work useful for your research, please consider citing us:
@article{bouritsas2020improving,
title={Improving graph neural network expressivity via subgraph isomorphism counting},
author={Bouritsas, Giorgos and Frasca, Fabrizio and Zafeiriou, Stefanos and Bronstein, Michael M},
journal={arXiv preprint arXiv:2006.09252},
year={2020}
}
 25 Dec 28, 2022
25 Dec 28, 2022

 9 Nov 22, 2022
9 Nov 22, 2022

 284 Dec 21, 2022
284 Dec 21, 2022

 35 Nov 14, 2022
35 Nov 14, 2022
 94 Oct 26, 2022
94 Oct 26, 2022

 89 Dec 26, 2022
89 Dec 26, 2022
 9 Nov 14, 2022
9 Nov 14, 2022
 139 Dec 25, 2022
139 Dec 25, 2022

 16 Jun 30, 2022
16 Jun 30, 2022



 43 Nov 27, 2022
43 Nov 27, 2022
 37 Dec 8, 2022
37 Dec 8, 2022
 1 Dec 9, 2021
1 Dec 9, 2021
 32 Dec 26, 2022
32 Dec 26, 2022
 1 Nov 26, 2021
1 Nov 26, 2021
 35 Nov 22, 2022
35 Nov 22, 2022
 3 Jun 13, 2022
3 Jun 13, 2022
 28 Dec 16, 2022
28 Dec 16, 2022
 2 Oct 31, 2022
2 Oct 31, 2022
 519 Jan 2, 2023
519 Jan 2, 2023