![]()
Ruia




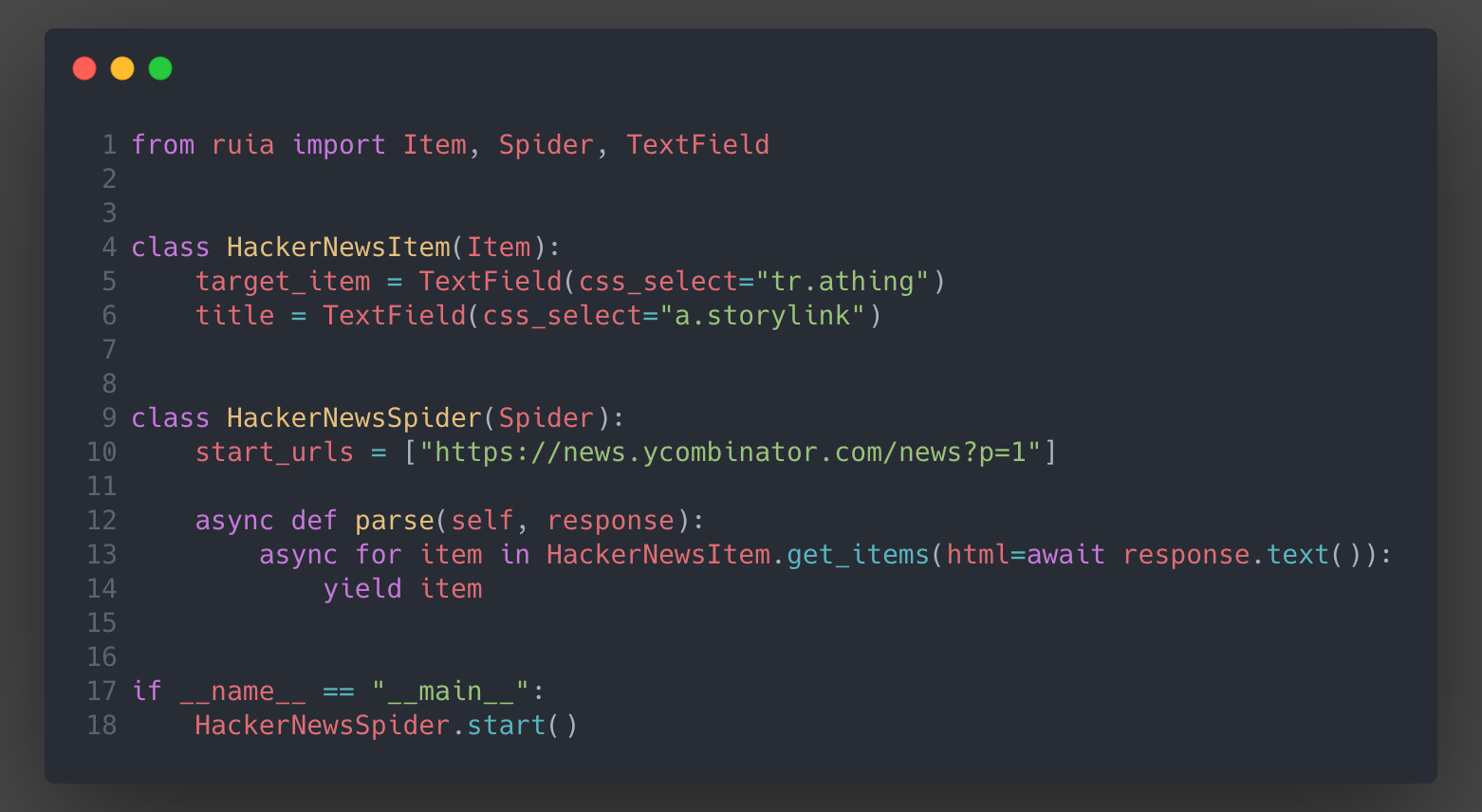
Overview
Ruia is an async web scraping micro-framework, written with asyncio and aiohttp, aims to make crawling url as convenient as possible.
Write less, run faster:
- Documentation: 中文文档 |documentation
- Organization: python-ruia
- Plugin: awesome-ruia(Any contributions you make are greatly appreciated!)
Features
- Easy: Declarative programming
- Fast: Powered by asyncio
- Extensible: Middlewares and plugins
- Powerful: JavaScript support
Installation
# For Linux & Mac
pip install -U ruia[uvloop]
# For Windows
pip install -U ruia
# New features
pip install git+https://github.com/howie6879/ruia
Tutorials
- Overview
- Installation
- Define Data Items
- Spider Control
- Request & Response
- Customize Middleware
- Write a Plugins
TODO
- Cache for debug, to decreasing request limitation, ruia-cache
- Provide an easy way to debug the script, ruia-shell
- Distributed crawling/scraping
Contribution
Ruia is still under developing, feel free to open issues and pull requests:
- Report or fix bugs
- Require or publish plugins
- Write or fix documentation
- Add test cases
!!!Notice: We use black to format the code








 8 Oct 27, 2022
8 Oct 27, 2022
 2k Jan 5, 2023
2k Jan 5, 2023
 45.5k Jan 7, 2023
45.5k Jan 7, 2023
 212 Nov 5, 2022
212 Nov 5, 2022
 2.3k Jan 4, 2023
2.3k Jan 4, 2023
 1 Dec 19, 2021
1 Dec 19, 2021
 1 Jan 25, 2022
1 Jan 25, 2022
 8.4k Jan 8, 2023
8.4k Jan 8, 2023
 2 Nov 8, 2021
2 Nov 8, 2021
 1 Nov 13, 2021
1 Nov 13, 2021
 5 Sep 25, 2022
5 Sep 25, 2022
 3 Jul 1, 2022
3 Jul 1, 2022
 1 Jan 4, 2022
1 Jan 4, 2022
 4 Apr 24, 2022
4 Apr 24, 2022
 12 Oct 22, 2022
12 Oct 22, 2022
 1 Feb 10, 2022
1 Feb 10, 2022
 704 Jan 6, 2023
704 Jan 6, 2023
 692 Dec 22, 2022
692 Dec 22, 2022
 2 Dec 14, 2022
2 Dec 14, 2022