HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022
[Project page | Video]
Getting start
Dataset (Click here to download)

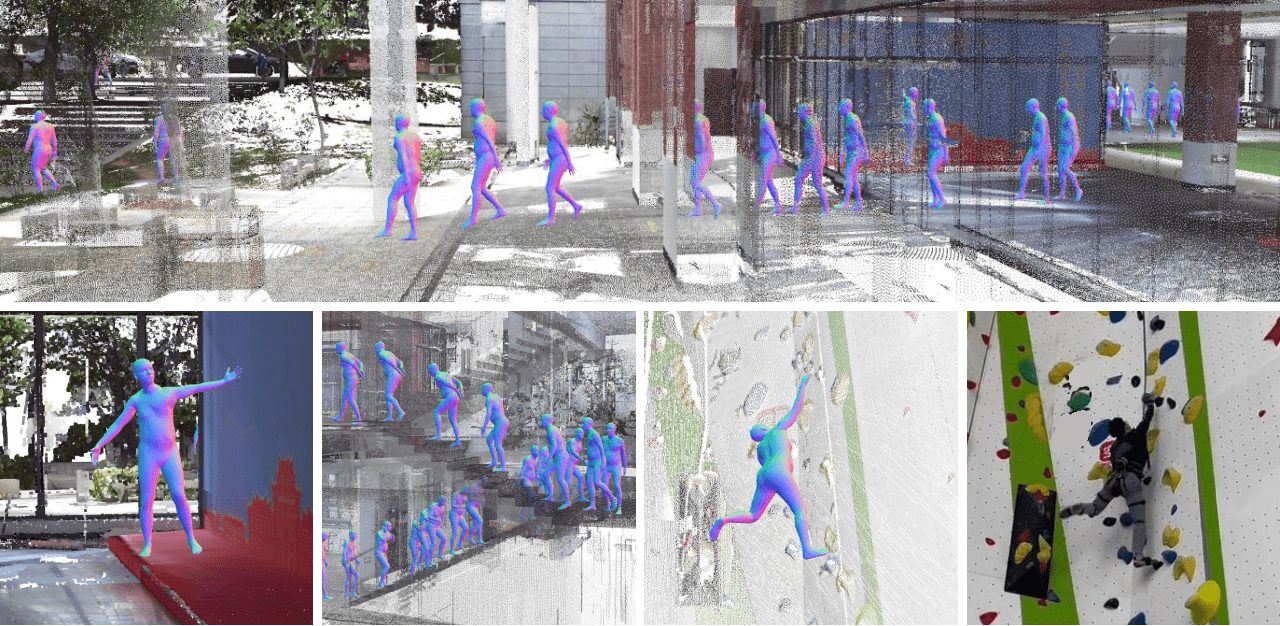
The large indoor and outdoor scenes in our dataset. Left: a climbing gym (1200 m2). Middle: a lab building with an outside courtyard 4000 m2. Right: a loop road scene 4600 m2
Data structure
Dataset root/
├── [Place_holder]/
| ├── [Place_holder].bvh # MoCap data from Noitom Axis Studio (PNStudio)
| ├── [Place_holder]_pos.csv # Every joint's roration, generated from `*_bvh`
| ├── [Place_holder]_rot.csv # Every joint's translation, generated from `*_bvh`
| ├── [Place_holder].pcap # Raw data from the LiDAR
| └── [Place_holder]_lidar_trajectory.txt # N×9 format file
├── ...
|
└── scenes/
├── [Place_holder].pcd
├── [Place_holder]_ground.pcd
├── ...
└── ...
- Place_holder can be replaced to
campus_raod,climbing_gym, andlab_building. *_lidar_trajectory.txtis generated by our Mapping method and manually calibrated with corresponding scenes.*_bvhand*_pcapare raw data from sensors. They will not be used in the following steps.- You can test your SLAM algorithm by using
*_pcapcaptured from Ouster1-64 with 1024×20Hz.
Preparation
- Download
basicModel_neutral_lbs_10_207_0_v1.0.0.pkland put it insmpldirectory. - Downloat the dataset and modify
dataset_rootanddata_nameinconfigs/sample.cfg.
dataset_root = /your/path/to/datasets
data_name = campus_road # or lab_building, climbing_gym
Requirement
Our code is tested under:
- Ubuntu: 18.04
- Python: 3.8
- CUDA: 11.0
- Pytorch: 1.7.0
Installation
conda create -n hsc4d python=3.8
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch
pip install open3d chumpy scipy configargparse matplotlib pathlib pandas opencv-python torchgeometry tensorboardx
- Note: For mask conversion compatibility in PyTorch 1.7.0, you need to manually edit the source file in torchgeometry. Follow the guide here
$ vi /home/dyd/software/anaconda3/envs/hsc4d/lib/python3.8/site-packages/torchgeometry/core/conversions.py
# mask_c1 = mask_d2 * (1 - mask_d0_d1)
# mask_c2 = (1 - mask_d2) * mask_d0_nd1
# mask_c3 = (1 - mask_d2) * (1 - mask_d0_nd1)
mask_c1 = mask_d2 * ~(mask_d0_d1)
mask_c2 = ~(mask_d2) * mask_d0_nd1
mask_c3 = ~(mask_d2) * ~(mask_d0_nd1)
- Note: When nvcc fatal error occurs.
export TORCH_CUDA_ARCH_LIST="8.0" #nvcc complier error. nvcc fatal: Unsupported gpu architecture
Preprocess
-
Transfer Mocap data [Optional, data provided]
pip install bvhtoolbox # https://github.com/OlafHaag/bvh-toolbox bvh2csv /your/path/to/campus_road.bvh- Output:
campus_road_pos.csv,campus_road_rot.csv
- Output:
-
LiDAR mapping [Optional, data provided]
- Process pcap file
cd initialize pip install ouster-sdk python ouster_pcap_to_txt.py -P /your/path/to/campus_road.pcap [-S start_frame] [-E end_frame]
-
Run your Mapping/SLAM algorithm.
-
Coordinate alignment (About 5 degree error after this step)
- The human stands as an A-pose before capture, and the human's face direction is regarded as scene's $Y$-axis direction.
- Rotate the scene cloud to make its $Z$-axis perpendicular to the starting position's ground.
- Translate the scene to make its origin to the first SMPL model's origin on the ground.
- LiDAR's ego motion $T^W$ and $R^W$ are translated and rotated as the scene does.
-
Output:
campus_road_lidar_trajectory.txt,scenes/campus_road.pcd
- Process pcap file
-
Data preprocessing for optimization.
python preprocess.py --dataset_root /your/path/to/datasets -fn campus_road -D 0.1
Data fusion
To be added
Data optimization
python main.py --config configs/sample.cfg
Visualization
To be added
Copyright
The HSC4D dataset is published under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 License.You must attribute the work in the manner specified by the authors, you may not use this work for commercial purposes and if you alter, transform, or build upon this work, you may distribute the resulting work only under the same license. Contact us if you are interested in commercial usage.
Bibtex
@misc{dai2022hsc4d,
title={HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR},
author={Yudi Dai and Yitai Lin and Chenglu Wen and Siqi Shen and Lan Xu and Jingyi Yu and Yuexin Ma and Cheng Wang},
year={2022},
eprint={2203.09215},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
 87 Jan 8, 2023
87 Jan 8, 2023
 45 Nov 29, 2022
45 Nov 29, 2022

 585 Jan 4, 2023
585 Jan 4, 2023
![[IROS'21] SurRoL: An Open-source Reinforcement Learning Centered and dVRK Compatible Platform for Surgical Robot Learning](https://github.com/med-air/SurRoL/raw/main/resources/img/surrol-overview.png)
 55 Jan 3, 2023
55 Jan 3, 2023

 182 Dec 30, 2022
182 Dec 30, 2022
 151 Dec 26, 2022
151 Dec 26, 2022

 36 Oct 30, 2022
36 Oct 30, 2022

 130 Dec 2, 2022
130 Dec 2, 2022

 3 Jan 7, 2022
3 Jan 7, 2022
 1 May 17, 2022
1 May 17, 2022
 122 Dec 13, 2022
122 Dec 13, 2022
 184 Dec 11, 2022
184 Dec 11, 2022
 66 Dec 21, 2022
66 Dec 21, 2022
 15 Nov 30, 2022
15 Nov 30, 2022
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
 102 Dec 25, 2022
102 Dec 25, 2022
 259 Dec 25, 2022
259 Dec 25, 2022
 259 Dec 28, 2022
259 Dec 28, 2022