TuckER: Tensor Factorization for Knowledge Graph Completion
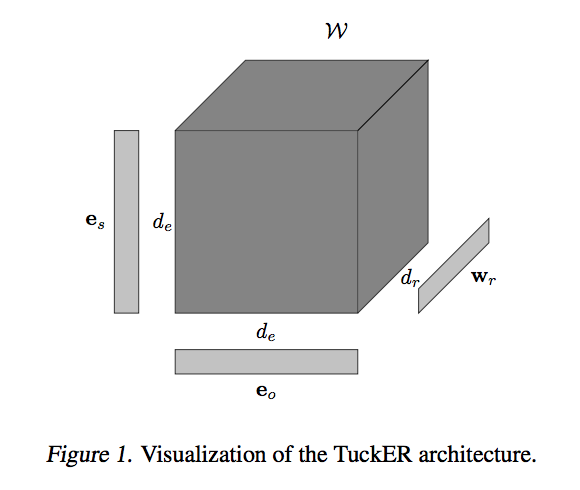
This codebase contains PyTorch implementation of the paper:
TuckER: Tensor Factorization for Knowledge Graph Completion. Ivana Balažević, Carl Allen, and Timothy M. Hospedales. Empirical Methods in Natural Language Processing (EMNLP), 2019. [Paper]
TuckER: Tensor Factorization for Knowledge Graph Completion. Ivana Balažević, Carl Allen, and Timothy M. Hospedales. ICML Adaptive & Multitask Learning Workshop, 2019. [Short Paper]
Link Prediction Results
| Dataset | MRR | Hits@10 | Hits@3 | Hits@1 |
|---|---|---|---|---|
| FB15k | 0.795 | 0.892 | 0.833 | 0.741 |
| WN18 | 0.953 | 0.958 | 0.955 | 0.949 |
| FB15k-237 | 0.358 | 0.544 | 0.394 | 0.266 |
| WN18RR | 0.470 | 0.526 | 0.482 | 0.443 |
Running a model
To run the model, execute the following command:
CUDA_VISIBLE_DEVICES=0 python main.py --dataset FB15k-237 --num_iterations 500 --batch_size 128
--lr 0.0005 --dr 1.0 --edim 200 --rdim 200 --input_dropout 0.3
--hidden_dropout1 0.4 --hidden_dropout2 0.5 --label_smoothing 0.1
Available datasets are:
FB15k-237
WN18RR
FB15k
WN18
To reproduce the results from the paper, use the following combinations of hyperparameters with batch_size=128:
| dataset | lr | dr | edim | rdim | input_d | hidden_d1 | hidden_d2 | label_smoothing |
|---|---|---|---|---|---|---|---|---|
| FB15k | 0.003 | 0.99 | 200 | 200 | 0.2 | 0.2 | 0.3 | 0. |
| WN18 | 0.005 | 0.995 | 200 | 30 | 0.2 | 0.1 | 0.2 | 0.1 |
| FB15k-237 | 0.0005 | 1.0 | 200 | 200 | 0.3 | 0.4 | 0.5 | 0.1 |
| WN18RR | 0.003 | 1.0 | 200 | 30 | 0.2 | 0.2 | 0.3 | 0.1 |
Requirements
The codebase is implemented in Python 3.6.6. Required packages are:
numpy 1.15.1
pytorch 1.0.1
Citation
If you found this codebase useful, please cite:
@inproceedings{balazevic2019tucker,
title={TuckER: Tensor Factorization for Knowledge Graph Completion},
author={Bala\v{z}evi\'c, Ivana and Allen, Carl and Hospedales, Timothy M},
booktitle={Empirical Methods in Natural Language Processing},
year={2019}
}











 2.8k Feb 12, 2021
2.8k Feb 12, 2021
 3 Dec 27, 2022
3 Dec 27, 2022
 41 Nov 30, 2022
41 Nov 30, 2022
 68 Dec 28, 2022
68 Dec 28, 2022
 96 Nov 5, 2022
96 Nov 5, 2022
 20 Dec 11, 2022
20 Dec 11, 2022
 283 Jan 4, 2023
283 Jan 4, 2023
 167 Jul 6, 2022
167 Jul 6, 2022
 9 Jun 10, 2022
9 Jun 10, 2022
 47 Jan 9, 2023
47 Jan 9, 2023
 67 Dec 20, 2022
67 Dec 20, 2022
 4 May 20, 2022
4 May 20, 2022
 46 Nov 17, 2022
46 Nov 17, 2022
 12 Oct 23, 2022
12 Oct 23, 2022
 50 Jun 7, 2022
50 Jun 7, 2022
 536 Jan 6, 2023
536 Jan 6, 2023
 5 May 23, 2022
5 May 23, 2022
 127 Jan 5, 2023
127 Jan 5, 2023