DeepWeb Scapper

Att: Demo version
An simple script to scrappe deepweb to find pages. Will return if any of those exists and will save on a file. You should specify the name of the file to save. If you wish to estimate the amount of requests, just multiply the number of the threads with the depth number.
Example:
- threads = 300
- depth = 350
Total requests: 105000
If you have an good internet connection, you can set from 1000 to 10000 for depth, and if you have an good CPU, set from 1000 to 5000 threads. You should sit and wait from 2h to 8h to find something (with big numbers). If you have an low-end computer, it's more convenient to wait hours or days to find anything working. Be persistent. TOR links are pretty messy to scapre :) .
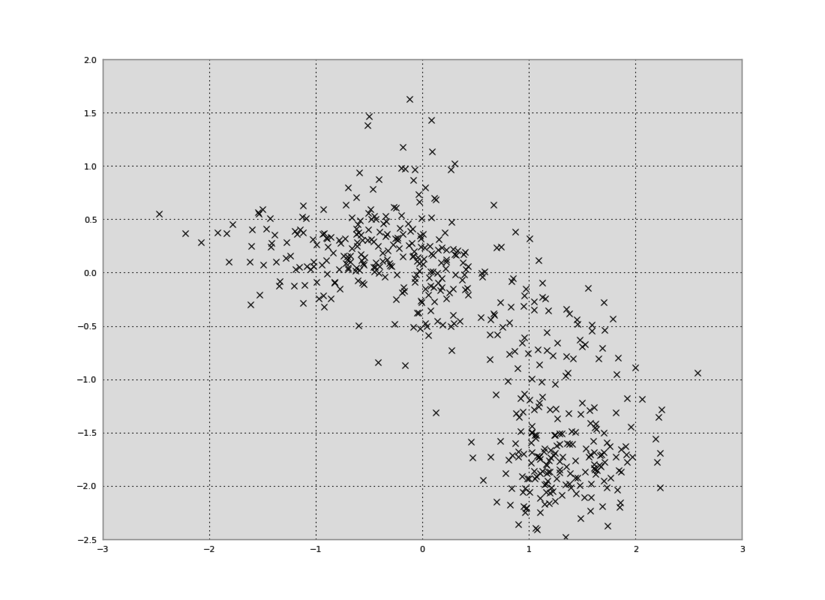
Screenshot with 30 million requests:

Todo
- Search for links using dicionaries (for DarkWeb)
- More improves
Requeriments
- Linux (any distro)
- TOR
- Python3 (requests, threading ,json, termcolor, string, bs4, socks, socket, random)
 1 Dec 4, 2021
1 Dec 4, 2021

 1 Jan 10, 2022
1 Jan 10, 2022
 6 Aug 26, 2022
6 Aug 26, 2022
 527 Dec 4, 2022
527 Dec 4, 2022
 41 Jul 6, 2022
41 Jul 6, 2022
 13 Nov 5, 2021
13 Nov 5, 2021
 38 Nov 7, 2022
38 Nov 7, 2022

 1k Jan 4, 2023
1k Jan 4, 2023

 754 Dec 29, 2022
754 Dec 29, 2022
 2 Nov 16, 2021
2 Nov 16, 2021
 22 May 31, 2022
22 May 31, 2022
 544 Jan 9, 2023
544 Jan 9, 2023
 5 May 2, 2022
5 May 2, 2022
 3 Feb 11, 2022
3 Feb 11, 2022
 377 Jan 3, 2023
377 Jan 3, 2023
 384 Jan 6, 2023
384 Jan 6, 2023
 69 Dec 20, 2022
69 Dec 20, 2022
 2.7k Jan 3, 2023
2.7k Jan 3, 2023
 221 Dec 18, 2022
221 Dec 18, 2022


 1k Jan 4, 2023
1k Jan 4, 2023
 754 Dec 29, 2022
754 Dec 29, 2022
 384 Jan 6, 2023
384 Jan 6, 2023
 69 Dec 20, 2022
69 Dec 20, 2022
 221 Dec 18, 2022
221 Dec 18, 2022
 4 Sep 5, 2022
4 Sep 5, 2022
 19 Jun 23, 2022
19 Jun 23, 2022
 23 Oct 8, 2022
23 Oct 8, 2022
 2 Nov 3, 2021
2 Nov 3, 2021
 3 Aug 24, 2022
3 Aug 24, 2022