Grid Sample 1d
pytorch cuda extension of grid sample 1d. Since pytorch only supports grid sample 2d/3d, I extend the 1d version for efficiency. The forward pass is 2~3x faster than pytorch grid sample.
setup
- Pytorch == 1.7.1
- CUDA == 10.1
Other versions of pytorch or cuda may work but I haven't test.
you can choose to manually build it or use JIT
Build
python setup.py install
JIT
comment import grid_sample1d_cuda as grid_sample1d in op.py
uncomment
grid_sample1d = load(
'grid_sample1d_cuda', ['grid_sample1d_cuda.cpp', 'grid_sample1d_cuda_kernel.cu'], verbose=True)
in op.py
Usage
import torch
from grid_sample1d import GridSample1d
grid_sample1d = GridSample1d(padding_mode=True, align_corners=True)
N = 16
C = 256
L_in = 64
L_out = 128
input = torch.randn((N, C, L_in)).cuda()
grids = torch.randn((N, L_out)).cuda()
output = grid_sample1d(input, grids)
Options are
- padding_mode: True for border padding, False for zero padding
- align_corners: same with align_corners in
torch.nn.functional.grid_sample
difference
In forward pass, calculation on the channel dim C is parallel, which is serial in torch.nn.functional.grid_sample. Parallel calculation on C may cause round off error in backward. But for now, I found it doesn't influence the forward pass.
Test
Accuracy Test
Since grid sample 1d is a special case of grid sample 2d in most cases (not true when padding_mode & align_corners are both False). I test the accuracy of the implemented grid sample based on torch.nn.functional.grid_sample.
import torch
import torch.nn.functional as F
def gridsample1d_by2d(input, grid, padding_mode, align_corners):
shape = grid.shape
input = input.unsqueeze(-1) # batch_size * C * L_in * 1
grid = grid.unsqueeze(1) # batch_size * 1 * L_out
grid = torch.stack([-torch.ones_like(grid), grid], dim=-1)
z = F.grid_sample(input, grid, padding_mode=padding_mode, align_corners=align_corners)
C = input.shape[1]
out_shape = [shape[0], C, shape[1]]
z = z.view(*out_shape) # batch_size * C * L_out
return z
It is recommended to test on your computer because I only test it on CUDA 10.1 GTX 1080Ti
python test/acc_benchmark.py
Both the forward and the backward results are identical except for align_corners=True, padding_mode=False. It may be caused by round off error when we sum series float numbers in different orders.
Deterministic Test
It is very important to do deterministic test since the associative law is no more applied for the calculation of float numbers on computers.
python test/check_deterministic.py
Note
When padding_mode & align_corners are both False, we cannot regard grid sample 1d as a special case of grid sample 2d in pytorch. I have checked the cuda kernel of grid_sample in Pytorch. When padding_mode & align_corners are both False, the output of torch.nn.functional.grid_sample will be half of the expected. Hope it can be fixed one day.
CPU support
Too lazy to support
speed & memory cost
Here are the speed test results on different size of input 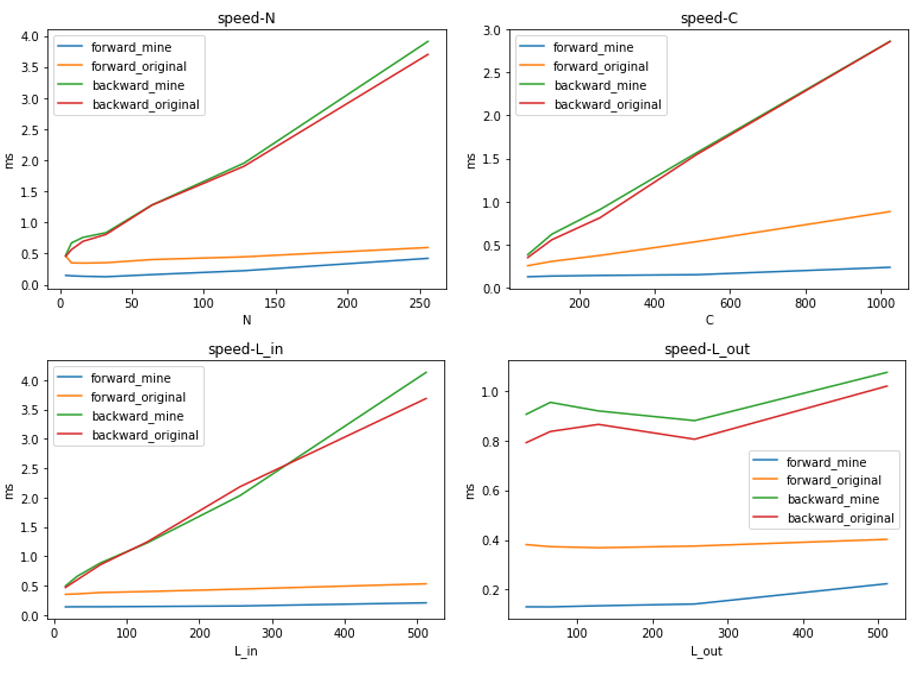
 6 Jan 12, 2022
6 Jan 12, 2022

 1.7k Jan 2, 2023
1.7k Jan 2, 2023
 4 Jun 20, 2022
4 Jun 20, 2022
 1 Dec 20, 2021
1 Dec 20, 2021

 276 Jan 7, 2023
276 Jan 7, 2023
 6.9k Jan 3, 2023
6.9k Jan 3, 2023
 5 Sep 29, 2021
5 Sep 29, 2021
 1.9k Jan 7, 2023
1.9k Jan 7, 2023
 16.5k Jan 8, 2023
16.5k Jan 8, 2023

 10 May 2, 2022
10 May 2, 2022
 237 Dec 23, 2022
237 Dec 23, 2022
 798 Jan 1, 2023
798 Jan 1, 2023
 97 Dec 1, 2022
97 Dec 1, 2022
 42 Jan 7, 2023
42 Jan 7, 2023
 106 Dec 14, 2022
106 Dec 14, 2022
 3 Jul 14, 2021
3 Jul 14, 2021
 14 Dec 17, 2022
14 Dec 17, 2022
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
 529 Jan 3, 2023
529 Jan 3, 2023