Duplicate Image Detection
Getting Started
- Install dependencies
pip install -r requirements.txt - Run service
python main.py
Testing
- Test with
pytest
How it Works

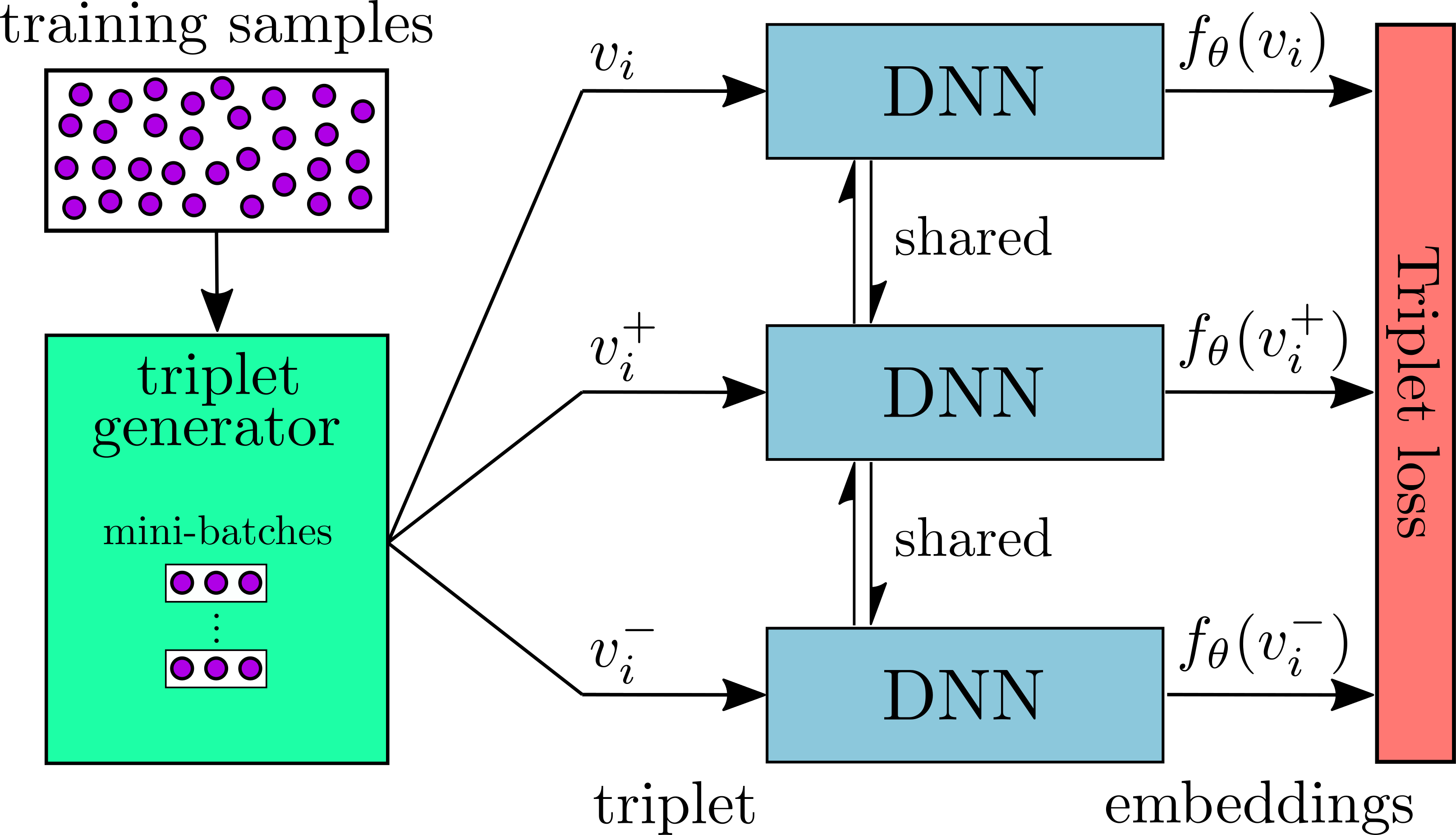
This system uses a perceptual hashing function, similar to Apple's CSAM Detection. Instead of generating image hashes using NeuralHash, it uses a difference hash (dHash), which is simpler and less computationally intensive as it doesn't require neural networks. Since we don't have the same privacy constraints as Apple, we will be using nearest neighbor searches to identify duplicate images.
Difference Hash
dHash is a perceptual hashing function that produces hash values that are resilient to image scaling, as well as changes in color, brightness, and aspect ratio [1]. There are 4 main steps for creating a difference hash for an image:

- Convert to greyscale*
- Resize image to (hash_size+1, hash_size)
- Calculate horizontal gradient, reducing image size to (hash_size, hash_size)
- Assign bits based on horizontal gradient values
*We convert the image to greyscale before resizing for optimal performance
Nearest Neighbors
Image hashes that we want to check for duplicates against will be stored in a binary index for fast and efficient nearest neighbor searches. We will use Hamming distance as a metric to determine the similarity between image hashes, for dHash, distances less than 10 (96.09% similarity) likely indicate similar/duplicate images [1].
References
[1] https://www.hackerfactor.com/blog/?/archives/529-Kind-of-Like-That.html

 78 Nov 19, 2022
78 Nov 19, 2022
 2 Jan 24, 2022
2 Jan 24, 2022
 6 Mar 30, 2022
6 Mar 30, 2022

 11 Dec 3, 2022
11 Dec 3, 2022
 1 Oct 15, 2021
1 Oct 15, 2021

 9 Nov 29, 2022
9 Nov 29, 2022
 32 Dec 26, 2022
32 Dec 26, 2022

 4.3k Jan 8, 2023
4.3k Jan 8, 2023
 10.6k Jan 4, 2023
10.6k Jan 4, 2023

 47 Dec 27, 2022
47 Dec 27, 2022
 57 Jan 1, 2023
57 Jan 1, 2023
 65 Dec 1, 2022
65 Dec 1, 2022
 8 Oct 7, 2022
8 Oct 7, 2022
 7 Nov 23, 2022
7 Nov 23, 2022
 1 Dec 14, 2021
1 Dec 14, 2021
 170 Dec 30, 2022
170 Dec 30, 2022
 139 Jan 1, 2023
139 Jan 1, 2023
 117 Jan 3, 2023
117 Jan 3, 2023
 555 Dec 24, 2022
555 Dec 24, 2022