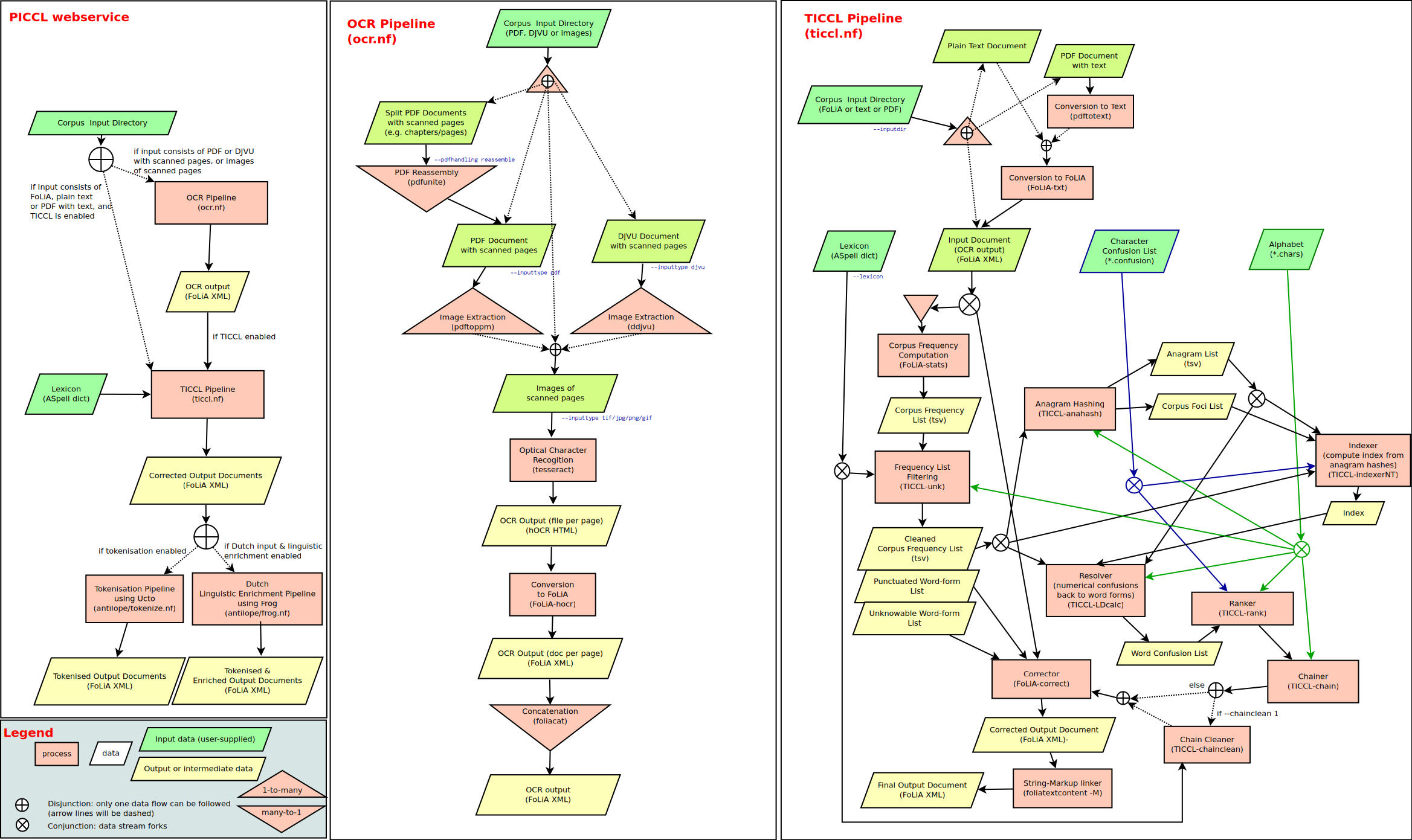
Optical Character Recognition
OCR (Optical Character Recognition) is a technology that enables the conversion of document types such as scanned paper documents, PDF files or pictures taken with a digital camera into editable and searchable data. OCR creates words from letters and sentences from words by selecting and separating letters from images.

Requirements
pip install -r requirements.txt
Usage
python main.py
Also you can check the result by one by like:
You have to initilaze your object.
ocr=OCR(image_folder="test/")
After that, for keras ocr:
ocr.keras_ocr_works()
for easyocr:
ocr.easyocr_model_works()
for pytesseract:
ocr.pytesseract_model_works()
Results



Conclusion
-
It seems that pytesseract is not very good at detecting text in the entire image and converting str. Instead, text should be detected first with text detection and the texts have to given OCR engines.
-
While keras_ocr is good in terms of accuracy but it is costly in terms of time. Also if you’re using CPU, time might be an issue for you. Keras-OCR is image specific OCR tool. If text is inside the image and their fonts and colors are unorganized.
-
Easy-OCR is lightweight model which is giving a good performance for receipt or PDF conversion. It is giving more accurate results with organized texts like PDF files, receipts, bills. Easy OCR also performs well on noisy images.
-
Pytesseract is performing well for high-resolution images. Certain morphological operations such as dilation, erosion, OTSU binarization can help increase pytesseract performance.
-
All these results can be further improved by performing specific image operations. OCR Prediction is not only dependent on the model and also on a lot of other factors like clarity, grey scale of the image, hyper parameter, weight age given, etc.
Source
https://github.com/faustomorales/keras-ocr
https://github.com/JaidedAI/EasyOCR
https://pypi.org/project/pytesseract/

 562 Jan 3, 2023
562 Jan 3, 2023

 311 Dec 24, 2022
311 Dec 24, 2022
 496 Jan 5, 2023
496 Jan 5, 2023

 444 Dec 30, 2022
444 Dec 30, 2022
 38 Dec 5, 2022
38 Dec 5, 2022
 38 Oct 14, 2022
38 Oct 14, 2022
 41 Dec 27, 2022
41 Dec 27, 2022
 489 Dec 21, 2022
489 Dec 21, 2022
 646 Nov 11, 2022
646 Nov 11, 2022

 2 Feb 22, 2022
2 Feb 22, 2022
 1 Dec 7, 2021
1 Dec 7, 2021
 71 Dec 30, 2022
71 Dec 30, 2022
 3 Sep 17, 2022
3 Sep 17, 2022
 27.5k Jan 8, 2023
27.5k Jan 8, 2023
 5 Dec 6, 2021
5 Dec 6, 2021
 16.7k Jan 3, 2023
16.7k Jan 3, 2023
 1.7k Dec 31, 2022
1.7k Dec 31, 2022
 58 Jan 7, 2023
58 Jan 7, 2023
 59 Sep 10, 2022
59 Sep 10, 2022