Image2PCL
Enter the metaverse with 2D image to 3D projections!
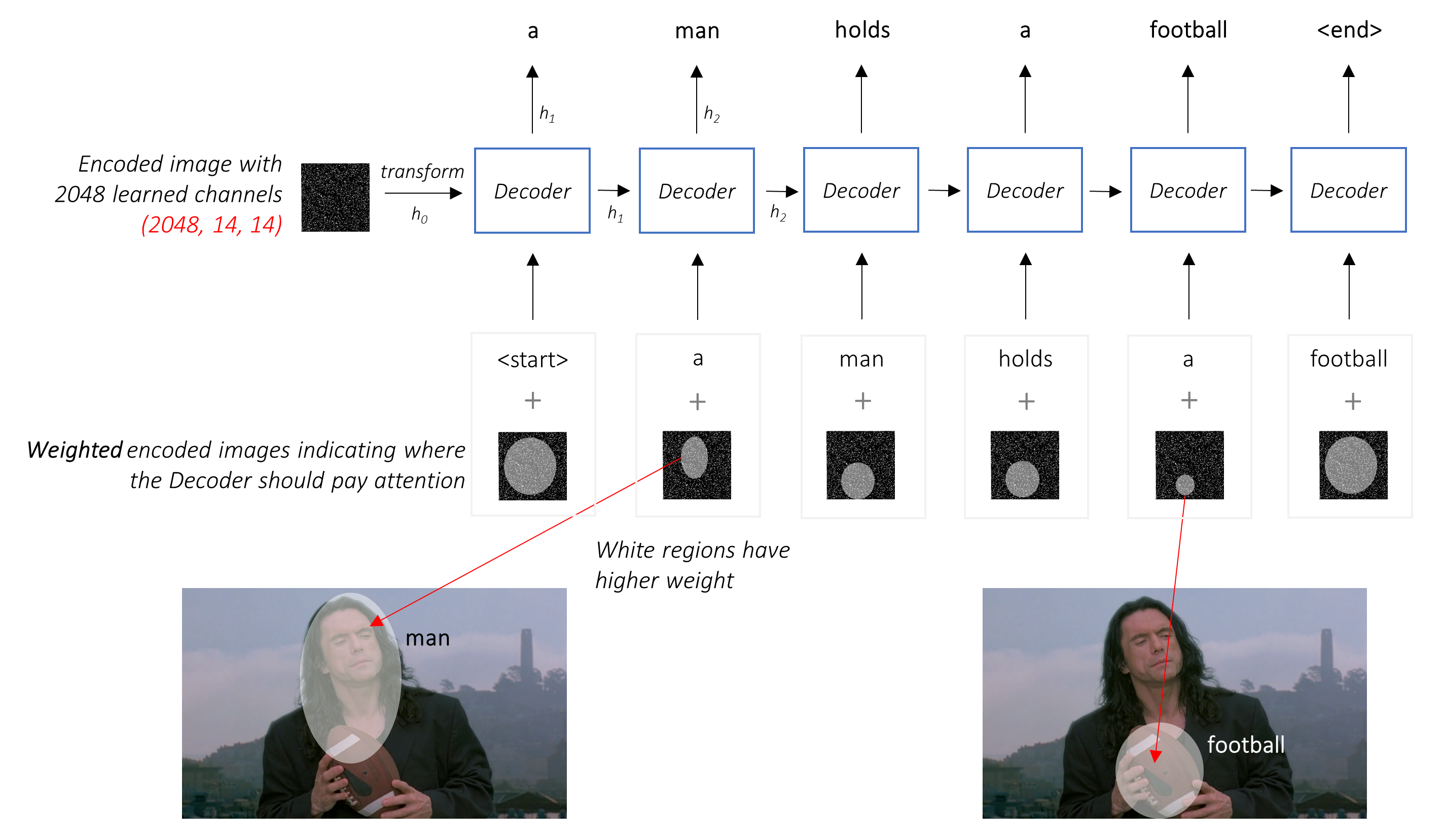
This is an implementation of an algorithm to project 2D images into the 3D space. See below for a visual summary of the project

The published code is inspired by the following works:
Monodepth2: https://www.github.com/nianticlabs/monodepth2
MMSegmentation: https://www.github.com/open-mmlab/mmsegmentation
Setup
Assuming you have already set up an Anaconda environment with PyTorch, CUDA and Python, install additional dependencies with:
pip install open3d
pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.html
Clone the mmsegmentation repository to your working directory
git clone https://github.com/open-mmlab/mmsegmentation
Create a 'models' folder to store your trained models for testing.
mkdir models
Trained KITTI models can be downloaded from the monodepth2 repository. This code was tested with the 'mono_640x192' model.
I also provide a custom-trained nuScenes model for testing with nuScenes images. This is helpful for multi-view point cloud rendering.
Test
To run a test, it is preferred to use images from a dataset with known camera intrinsics. For this implementation, we use two different datasets:
- KITTI Raw for single image testing
- nuScenes for multi-view images testing
To test on KITTI, run the following (replace the "<>" brackets and contents inside with the correct information):
python img2pcl.py \
--image_path <path to single image file or folder containing single image> \
--model_path <path to trained KITTI model> \
--data_type kitti_raw
To test on nuScenes to view a 360 3D point cloud, run the following (replace the "<>" brackets and contents inside with the correct information):
python img2pcl.py \
--image_path <path to folder containing nuScenes multi-cam images> \
--model_path <path to trained nuScenes model> \
--data_type nuscenes \
--nusc_camera_parameters <path to a json file containing nuscenes camera intrinsics and extrinsics>
 7 Sep 20, 2022
7 Sep 20, 2022
 458 Jan 2, 2023
458 Jan 2, 2023

 82 Dec 26, 2022
82 Dec 26, 2022

 29 Nov 17, 2022
29 Nov 17, 2022
 86 Dec 28, 2022
86 Dec 28, 2022
 63 Oct 30, 2022
63 Oct 30, 2022

 3 Apr 2, 2022
3 Apr 2, 2022
 2 Nov 5, 2021
2 Nov 5, 2021
 13 Jan 6, 2023
13 Jan 6, 2023

 4 Aug 20, 2022
4 Aug 20, 2022
 18 Nov 17, 2022
18 Nov 17, 2022
 740 Dec 24, 2022
740 Dec 24, 2022
 17 Dec 23, 2022
17 Dec 23, 2022
 612 Jan 4, 2023
612 Jan 4, 2023
 901 Jan 6, 2023
901 Jan 6, 2023
 110 Jan 7, 2023
110 Jan 7, 2023
 605 Jan 2, 2023
605 Jan 2, 2023