Multi-agent reinforcement learning algorithm and environment
[en/cn]
Pytorch implements multi-agent reinforcement learning algorithms including IQL, QMIX, VDN, COMA, QTRAN (QTRAN-Base and QTRAN-Alt), MAVEN, CommNet, DYMA-Cl, and G2ANet, which are among the most advanced MARL algorithms. SMAC is a decentralized micromanagement scenario for StarCraft II.
Project Address: https://github.com/starry-sky6688/StarCraft
Run:
python main.py --map=3m --alg=qmix
Run directly, and then the algorithm will start training on the map.
MRL environment configuration Starcraft II environment: https://github.com/oxwhirl/smac
Install StarCraft II
SMAC based on the complete game of StarCraft II (version >= 3.16.1). To install the game, follow the command below.
- Linux
Please use [blizzard repository] (https://github.com/Blizzard/s2client-proto#downloads) download the Linux version of starcraft II. By default, the game should be in a directory. This can be changed by setting environment variables. ~/StarCraftII/SC2PATH
- MacOS/Windows
From Battle.net, please install [starcraft II] (https://starcraft2.com/zh-tw/). The free starter version is also available. If you use the default installation location, PySC2 will find the latest binaries. Otherwise, like the Linux version, you need to set the environment variables with the correct location of the game. SC2PATH
SMAC map
SMAC consists of a number of battle scenarios with pre-configured maps. Before SMAC can be used, these maps need to be downloaded into the StarCraft II directory. Maps
Download the [SMAC map] (https://github.com/oxwhirl/smac/releases/download/v0.1-beta1/SMAC_Maps.zip) and unzip it to your directory. If you have SMAC installed with Git, simply copy the directory from the directory to the directory.
Create a new folder Maps under the root directory
Save the file to the StarCraft Maps folder.
run
python main.py --map=3m --alg=qmix
Environment configuration, feel a bit of a problem, actually change the python folder in the address, do not need to configure any environment variables. Error file, click to find C: change to F: can be.
result
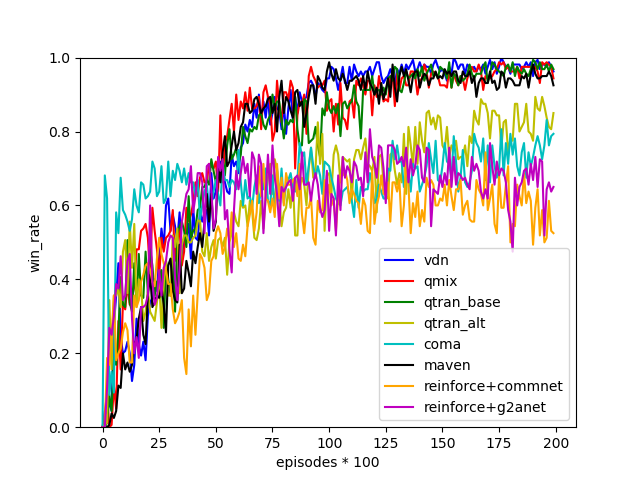
MADDPG
Git are not running, found on the test for a long time, on the basis of the https://github.com/starry-sky6688/MADDPG changed, run successfully.
- the corresponding papers: [Multi - Agent Actor - Critic for Mixed Cooperative - Competitive Environments] (https://arxiv.org/abs/1706.02275)
- the corresponding environment: (MPE) (https://github.com/openai/multiagent-particle-envs)
multi-agent environment
MPE Installation Method 1:
cd into the root directory and type pip install -e .
2 installation method 2: https://www.pettingzoo.ml/mpe
pip install pettingzoo[mpe]
Requirements
Python = 3.6.5 Multi-Agent Particle Environment(MPE) The torch = 1.1.0
result
python main.py --scenario-name=simple_tag --evaluate-episodes=10
Py --scenario-name=simple_tag --evaluate-episodes=10
Modify the 'simple_tag' replacement environment.
result
In this task, two blue agents gain a reward by minimizing their closest approach to a green landmark (only one needs to get close enough for the best reward), while maximizing the distance between a red opponent and the green landmark. Red opponents are rewarded by minimizing their distance from green landmarks; However, in any given trial, it doesn't know which landmark is green, so it must follow the blue proxy. Therefore, the blue agent should learn to trick the red agent by overwriting two landmarks.
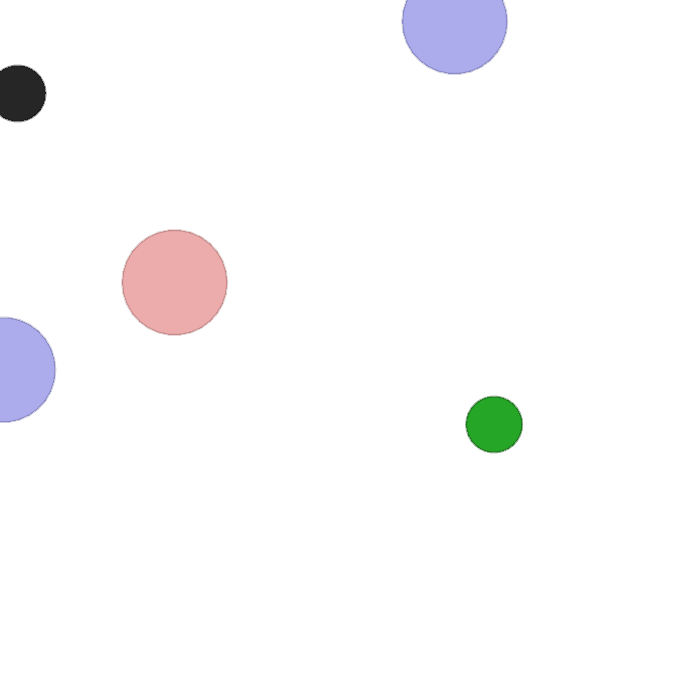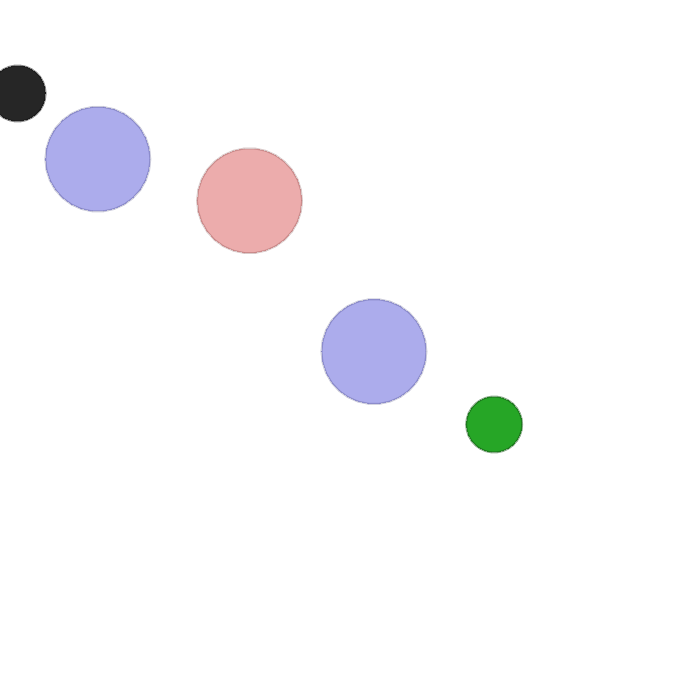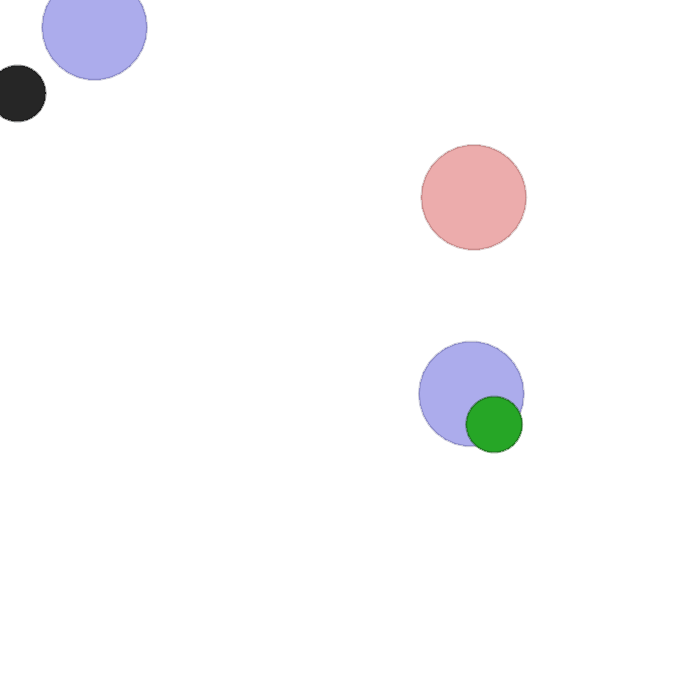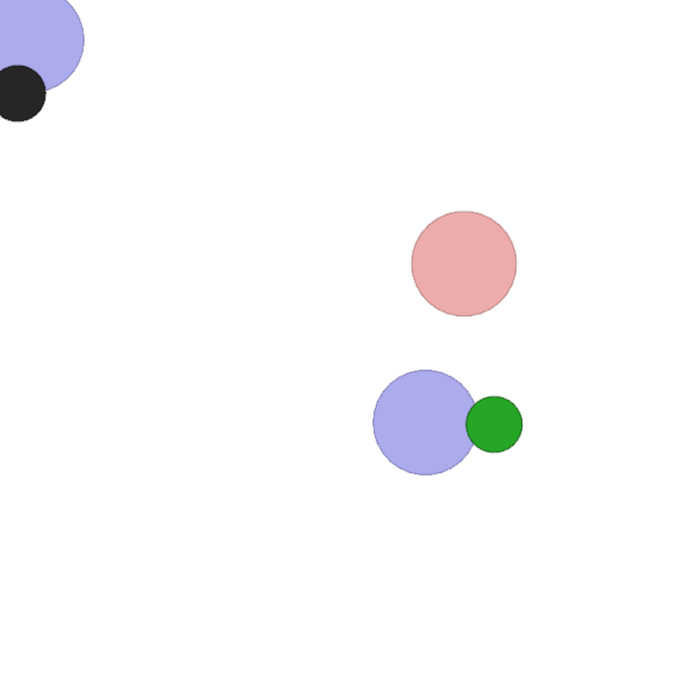



 83 Jan 6, 2023
83 Jan 6, 2023
 10 Oct 10, 2022
10 Oct 10, 2022

 14 Sep 16, 2022
14 Sep 16, 2022
 159 Dec 28, 2022
159 Dec 28, 2022
 983 Dec 23, 2022
983 Dec 23, 2022

 234 Nov 5, 2022
234 Nov 5, 2022

 1 May 15, 2022
1 May 15, 2022

 56 Nov 15, 2022
56 Nov 15, 2022
 8 Sep 30, 2022
8 Sep 30, 2022

 1.1k Jan 2, 2023
1.1k Jan 2, 2023
 1 Nov 10, 2021
1 Nov 10, 2021
 3.7k Jan 3, 2023
3.7k Jan 3, 2023
 297 Dec 12, 2022
297 Dec 12, 2022
 463 Dec 23, 2022
463 Dec 23, 2022
 183 Dec 28, 2022
183 Dec 28, 2022
 405 Jan 6, 2023
405 Jan 6, 2023
 348 Jan 8, 2023
348 Jan 8, 2023
 334 Jan 6, 2023
334 Jan 6, 2023
 96 Dec 22, 2022
96 Dec 22, 2022