Spider Admin Pro




Github: https://github.com/mouday/spider-admin-pro
Gitee: https://gitee.com/mouday/spider-admin-pro
Pypi: https://pypi.org/project/spider-admin-pro
简介
Spider Admin Pro 是Spider Admin的升级版
- 简化了一些功能;
- 优化了前端界面,基于Vue的组件化开发;
- 优化了后端接口,对后端项目进行了目录划分;
- 整体代码利于升级维护。
- 目前仅对Python3进行了支持

安装启动
方式一:
$ pip3 install spider-admin-pro
$ python3 -m spider_admin_pro.run
方式二:
$ git clone https://github.com/mouday/spider-admin-pro.git
$ python3 spider_admin_pro/run.py
配置参数
配置优先级:
yaml配置文件 > env环境变量 > 默认配置
1、默认配置
# flask 服务配置
PORT = 5002
HOST = '127.0.0.1'
# 登录账号密码
USERNAME = admin
PASSWORD = "123456"
JWT_KEY = FU0qnuV4t8rr1pvg93NZL3DLn6sHrR1sCQqRzachbo0=
# token过期时间,单位天
EXPIRES = 7
# scrapyd地址, 结尾不要加斜杆
SCRAPYD_SERVER = 'http://127.0.0.1:6800'
# 调度器 调度历史存储设置
# mysql or sqlite and other, any database for peewee support
SCHEDULE_HISTORY_DATABASE_URL = 'sqlite:///dbs/schedule_history.db'
# 调度器 定时任务存储地址
JOB_STORES_DATABASE_URL = 'sqlite:///dbs/apscheduler.db'
# 日志文件夹
LOG_DIR = 'logs'
2、env环境变量
在运行目录新建 .env 环境变量文件,默认参数如下
注意:为了与其他环境变量区分,使用SPIDER_ADMIN_PRO_作为变量前缀
如果使用python3 -m 运行,需要将变量加入到环境变量中,运行目录下新建文件env.bash
注意,此时等号后面不可以用空格
# flask 服务配置
export SPIDER_ADMIN_PRO_PORT=5002
export SPIDER_ADMIN_PRO_HOST='127.0.0.1'
# 登录账号密码
export SPIDER_ADMIN_PRO_USERNAME='admin'
export SPIDER_ADMIN_PRO_PASSWORD='123456'
export SPIDER_ADMIN_PRO_JWT_KEY='FU0qnuV4t8rr1pvg93NZL3DLn6sHrR1sCQqRzachbo0='
增加环境变量后运行
$ source env.bash
$ python3 -m spider_admin_pro.run
3、config.yml
在运行目录下新建config.yml 文件,运行时会自动读取该配置文件
eg:
# flask 服务配置
PORT: 5002
HOST: '127.0.0.1'
# 登录账号密码
USERNAME: admin
PASSWORD: "123456"
JWT_KEY: "FU0qnuV4t8rr1pvg93NZL3DLn6sHrR1sCQqRzachbo0="
# token过期时间,单位天
EXPIRES: 7
# scrapyd地址, 结尾不要加斜杆
SCRAPYD_SERVER: "http://127.0.0.1:6800"
# 日志文件夹
LOG_DIR: 'logs'
生成jwt key
$ python -c 'import base64;import os;print(base64.b64encode(os.urandom(32)).decode())'
部署优化
1、使用 Gunicorn管理应用
Gunicorn文档:https://docs.gunicorn.org/
# 启动服务
$ gunicorn --config gunicorn.conf.py spider_admin_pro.run:app
一个配置示例:gunicorn.conf.py
# -*- coding: utf-8 -*-
"""
$ gunicorn --config gunicorn.conf.py spider_admin_pro.run:app
"""
import multiprocessing
import os
from gevent import monkey
monkey.patch_all()
# 日志文件夹
LOG_DIR = 'logs'
if not os.path.exists(LOG_DIR):
os.mkdir(LOG_DIR)
def resolve_file(filename):
return os.path.join(LOG_DIR, filename)
def get_workers():
return multiprocessing.cpu_count() * 2 + 1
# daemon = True
daemon = False # 使用supervisor不能是后台进程
# 进程名称
proc_name = "spider-admin-pro"
# 启动端口
bind = "127.0.0.1:5001"
# 日志文件
loglevel = 'debug'
pidfile = resolve_file("gunicorn.pid")
accesslog = resolve_file("access.log")
errorlog = resolve_file("error.log")
# 启动的进程数
# workers = get_workers()
workers = 2
worker_class = 'gevent'
# 启动时钩子
def on_starting(server):
ip, port = server.address[0]
print('server.address:', f'http://{ip}:{port}')
2、使用supervisor管理进程
spider-admin-pro.ini
[program: spider-admin-pro]
directory=/spider-admin-pro
command=/usr/local/python3/bin/gunicorn --config gunicorn.conf.py spider_admin_pro.run:app
stdout_logfile=logs/out.log
stderr_logfile=logs/err.log
stdout_logfile_maxbytes = 20MB
stdout_logfile_backups = 0
stderr_logfile_maxbytes=10MB
stderr_logfile_backups=0
3、使用Nginx转发请求
server {
listen 80;
server_name _;
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
location / {
proxy_pass http://127.0.0.1:5001/;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
使用扩展
收集运行日志:scrapy-util 可以帮助你收集到程序运行的统计数据
技术栈:
1、前端技术:
| 功能 | 第三方库及文档 |
|---|---|
| 基本框架 | vue |
| 仪表盘图表 | echarts |
| 网络请求 | axios |
| 界面样式 | Element-UI |
2、后端技术
| 功能 | 第三方库及文档 |
|---|---|
| 接口服务 | Flask |
| 任务调度 | apscheduler |
| scrapyd接口 | scrapyd-api |
| 网络请求 | session-request |
| ORM | peewee |
| jwt | jwt |
| 系统信息 | psutil |
项目结构
【公开仓库】基于Flask的后端项目spider-admin-pro: https://github.com/mouday/spider-admin-pro
【私有仓库】基于Vue的前端项目spider-admin-pro-web: https://github.com/mouday/spider-admin-pro-web
spider-admin-pro项目主要目录结构:
.
├── run.py # 程序入口
├── api # Controller层
├── service # Sevice层
├── model # Model层
├── exceptions # 异常
├── utils # 工具类
└── web # 静态web页
经验总结
Scrapyd 不能直接暴露在外网
- 其他人通过deploy部署可以将代码部署到你的机器上,如果是root用户运行,还会在你机器上做其他的事情
- 还有运行日志中会出现配置文件中的信息,存在信息泄露的危险
TODO
1. 补全开发文档
2. 支持命令行安装可用
3. 优化代码布局,提取公共库
4. 日志自动刷新
5. scrapy项目数据收集
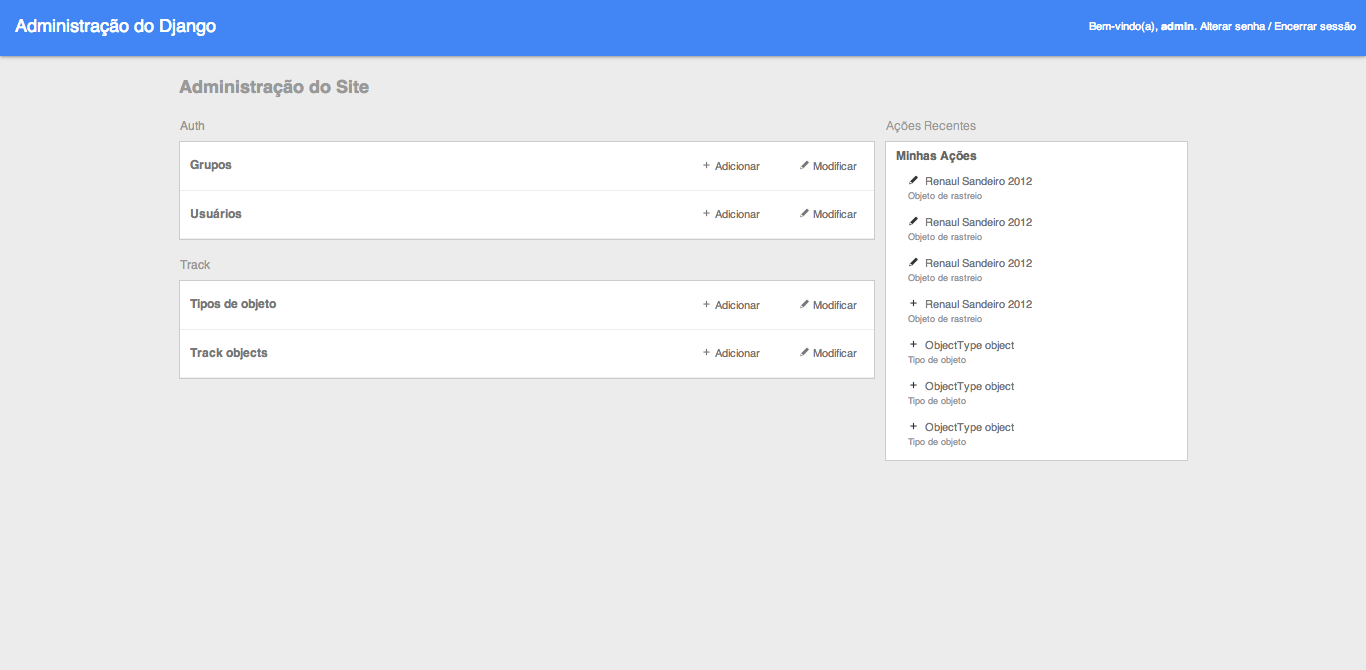
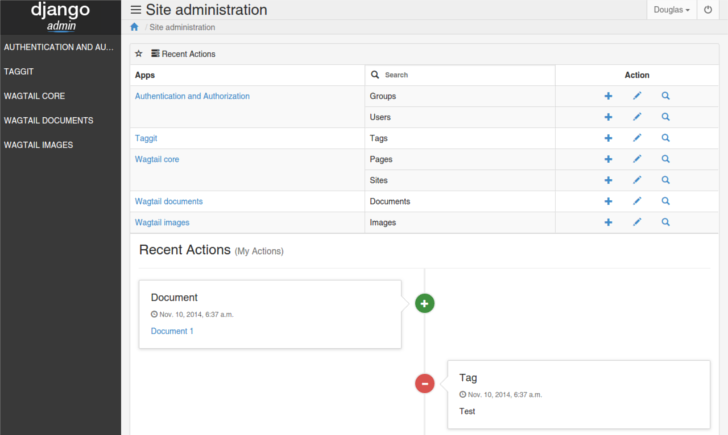
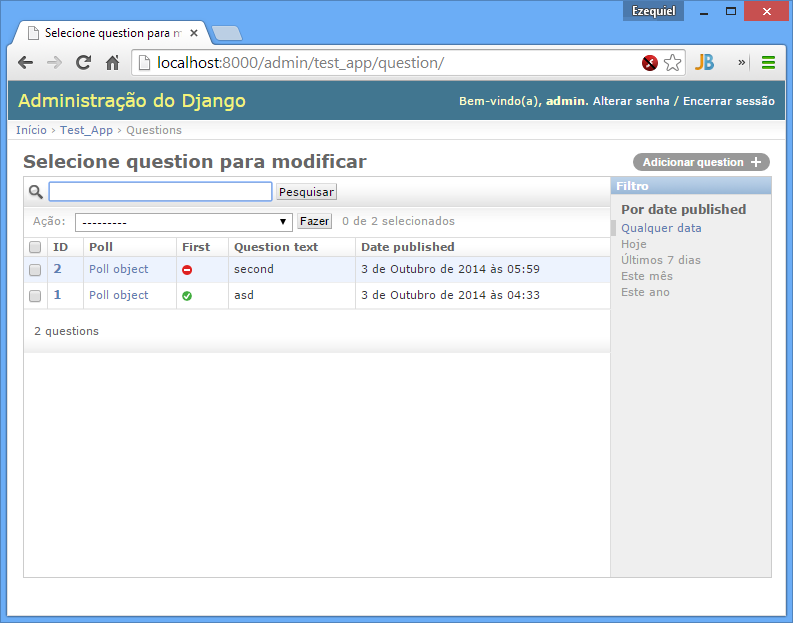
项目截图





 2.2k Dec 29, 2022
2.2k Dec 29, 2022

 2.6k Jan 7, 2023
2.6k Jan 7, 2023
 907 Dec 31, 2022
907 Dec 31, 2022
 326 Dec 3, 2022
326 Dec 3, 2022

 258 Nov 30, 2022
258 Nov 30, 2022
 236 Dec 15, 2022
236 Dec 15, 2022
 852 Dec 2, 2022
852 Dec 2, 2022
 1.6k Dec 28, 2022
1.6k Dec 28, 2022
 364 Jan 8, 2023
364 Jan 8, 2023





 1.3k Dec 27, 2022
1.3k Dec 27, 2022
 17 Nov 16, 2022
17 Nov 16, 2022
 3.4k Dec 29, 2022
3.4k Dec 29, 2022
 4.7k Dec 31, 2022
4.7k Dec 31, 2022
 5.5k Dec 28, 2022
5.5k Dec 28, 2022
 3.4k Dec 31, 2022
3.4k Dec 31, 2022
 1.6k Dec 28, 2022
1.6k Dec 28, 2022
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
 1.2k Dec 29, 2022
1.2k Dec 29, 2022
 1.6k Jan 2, 2023
1.6k Jan 2, 2023