CIFAR10-Tensorflow
classification task on dataset-CIFAR10,by using Tensorflow/keras
在这一个库中,我使用Tensorflow与keras框架搭建了几个卷积神经网络模型,针对CIFAR10数据集进行了训练与测试。分别使用了基本框架Baseline,AlexNet,LeNet,ResNet,Inception和VGGNet六种模型,并对VGGNet模型中的超参数进行了微调,并观察结果。下面将对各个卷积神经网络模型的性能进行对比分析。
目录
CIFAR10简介
该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。 下面这幅图就是列举了10各类,每一类展示了随机的10张图片:

需要说明的是,这10类都是各自独立的,不会出现重叠。
所需环境
conda 4.10.3
keras 2.6.0
markdown 3.3.4
matplotlib 3.4.2
numpy 1.19.5
python 3.9.7
tensorflow-gpu 2.6.0
BaseLine网络
BaseLine网络是我经过卷积神经网络基础知识学习之后搭建的最为基础的模型,将输入图像依次经过CBAPD五个层(即卷积层、批标准化层、激活层、池化层和舍弃层),随后用概率输出的基础网络。 该网络结构简单,比较适合进行测试,因此我首先使用了这个网络模型,使用CIFAR10数据集进行了训练和测试。
BaseLine的网络结构如下:
Model: "baseline"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 456
_________________________________________________________________
batch_normalization (BatchNo multiple 24
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
dropout (Dropout) multiple 0
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dense (Dense) multiple 196736
_________________________________________________________________
dropout_1 (Dropout) multiple 0
_________________________________________________________________
dense_1 (Dense) multiple 1290
=================================================================
Total params: 198,506
Trainable params: 198,494
Non-trainable params: 12
_________________________________________________________________
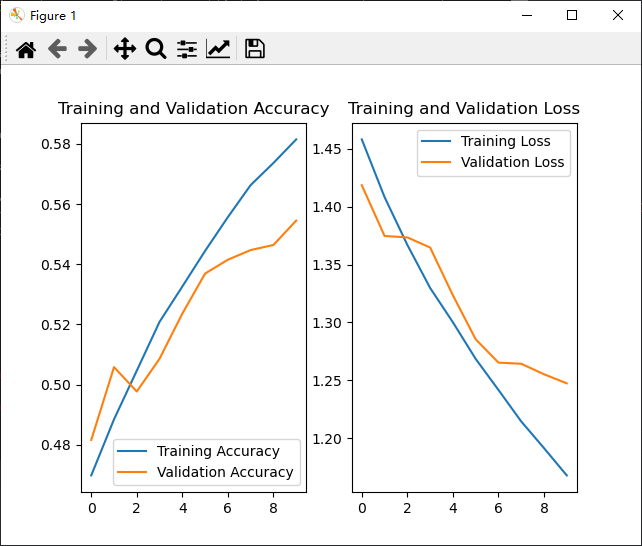
BaseLine网络训练结果
LeNet-5网络模型
LeNet-5卷积神经网络模型 LeNet-5:是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。
LenNet-5共有7层(不包括输入层),有2个卷积层、2个下抽样层(池化层)、3个全连接层3种连接方式,如下图所示。

LeNet-5网络结构
Model: "le_net5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 456
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
conv2d_1 (Conv2D) multiple 2416
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 multiple 0
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dense (Dense) multiple 48120
_________________________________________________________________
dense_1 (Dense) multiple 10164
_________________________________________________________________
dense_2 (Dense) multiple 850
=================================================================
Total params: 62,006
Trainable params: 62,006
Non-trainable params: 0
_________________________________________________________________
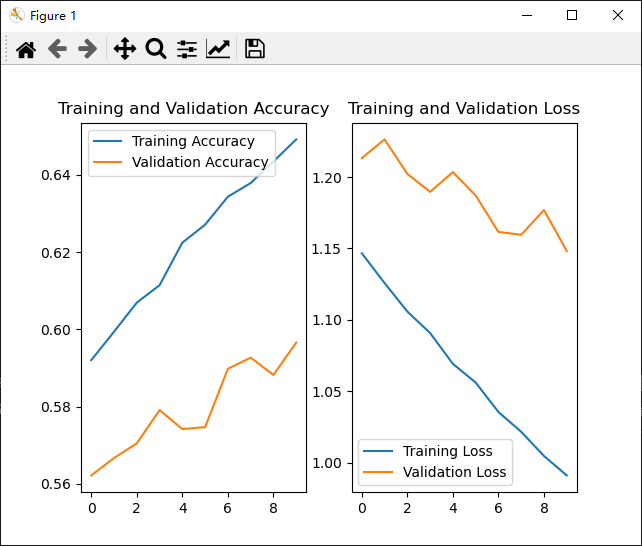
LeNet-5网络训练结果
论文来源
LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324.
AlexNet网络模型
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg,GoogLeNet。 这对于传统的机器学习分类算法而言,已经相当的出色。 AlexNet中包含了几个比较新的技术点,也首次在CNN中成功应用了ReLU、Dropout和LRN等Trick。同时AlexNet也使用了GPU进行运算加速。 AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。同时,AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
(6)数据增强,随机地从256256的原始图像中截取224224大小的区域(以及水平翻转的镜像),相当于增加了2*(256-224)^2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。同时,AlexNet论文中提到了会对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。

AlexNet网络结构
Model: "alex_net8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 2688
_________________________________________________________________
batch_normalization (BatchNo multiple 384
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
conv2d_1 (Conv2D) multiple 221440
_________________________________________________________________
batch_normalization_1 (Batch multiple 1024
_________________________________________________________________
activation_1 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 multiple 0
_________________________________________________________________
conv2d_2 (Conv2D) multiple 885120
_________________________________________________________________
conv2d_3 (Conv2D) multiple 1327488
_________________________________________________________________
conv2d_4 (Conv2D) multiple 884992
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 multiple 0
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dense (Dense) multiple 2099200
_________________________________________________________________
dropout (Dropout) multiple 0
_________________________________________________________________
dense_1 (Dense) multiple 4196352
_________________________________________________________________
dropout_1 (Dropout) multiple 0
_________________________________________________________________
dense_2 (Dense) multiple 20490
=================================================================
Total params: 9,639,178
Trainable params: 9,638,474
Non-trainable params: 704
_________________________________________________________________
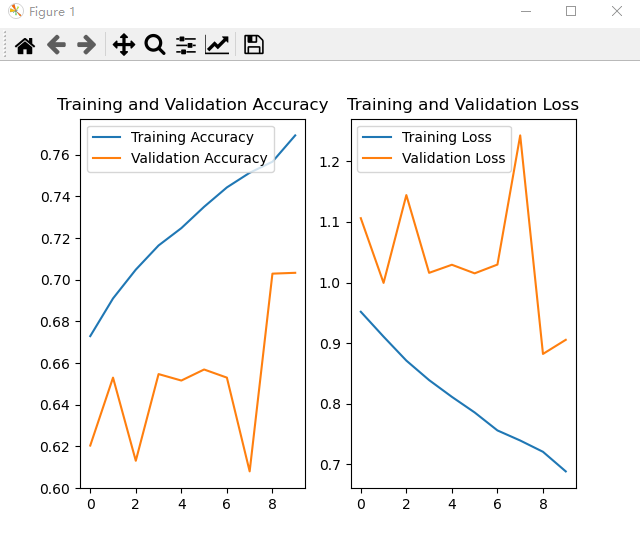
AlexNet网络训练结果
论文来源
Technicolor T , Related S , Technicolor T , et al. ImageNet Classification with Deep Convolutional Neural Networks.
VGGNet网络模型
VGG的作者在论文中将它称为是Very Deep Convolutional Network,如上图所示的VGG16网络带权层就达到了16层,这在当时已经很深了。网络的前半部分,每隔2~3个卷积层接一个最大池化层,4次池化共经历了13个卷积层,加上最后3个全连接层共有16层,也正因此我们称这个网络为VGG16。
VGG16不仅结构清晰,层参数也很简单。所有的卷积层都采用3x3的卷积核,步长为1;所有池化层都是2x2池化,步长为2。正因为此,我们看到图片尺寸变化规律,从224x224到112x112等,直到最后变成7x7。同时我们注意到特征图通道的数量也一直在加倍,从64到128最终变成512层。因此VGG16结构图画出来非常美观,实现起来也很规整。
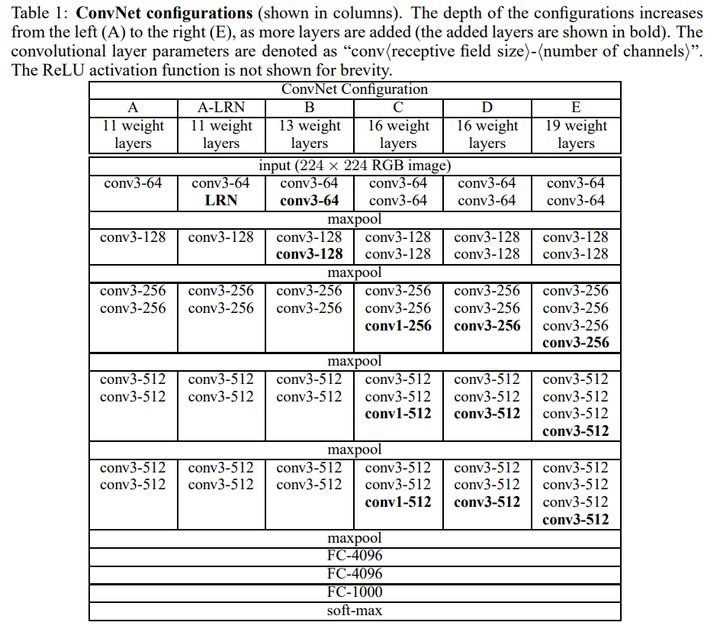
VGGNet网络结构
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 1792
_________________________________________________________________
batch_normalization (BatchNo multiple 256
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
conv2d_1 (Conv2D) multiple 36928
_________________________________________________________________
batch_normalization_1 (Batch multiple 256
_________________________________________________________________
activation_1 (Activation) multiple 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
dropout (Dropout) multiple 0
_________________________________________________________________
conv2d_2 (Conv2D) multiple 73856
_________________________________________________________________
batch_normalization_2 (Batch multiple 512
_________________________________________________________________
activation_2 (Activation) multiple 0
_________________________________________________________________
conv2d_3 (Conv2D) multiple 147584
_________________________________________________________________
batch_normalization_3 (Batch multiple 512
_________________________________________________________________
activation_3 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_1 (Dropout) multiple 0
_________________________________________________________________
conv2d_4 (Conv2D) multiple 295168
_________________________________________________________________
batch_normalization_4 (Batch multiple 1024
_________________________________________________________________
activation_4 (Activation) multiple 0
_________________________________________________________________
conv2d_5 (Conv2D) multiple 590080
_________________________________________________________________
batch_normalization_5 (Batch multiple 1024
_________________________________________________________________
activation_5 (Activation) multiple 0
_________________________________________________________________
conv2d_6 (Conv2D) multiple 590080
_________________________________________________________________
batch_normalization_6 (Batch multiple 1024
_________________________________________________________________
activation_6 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_2 (Dropout) multiple 0
_________________________________________________________________
conv2d_7 (Conv2D) multiple 1180160
_________________________________________________________________
batch_normalization_7 (Batch multiple 2048
_________________________________________________________________
activation_7 (Activation) multiple 0
_________________________________________________________________
conv2d_8 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_8 (Batch multiple 2048
_________________________________________________________________
activation_8 (Activation) multiple 0
_________________________________________________________________
conv2d_9 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_9 (Batch multiple 2048
_________________________________________________________________
activation_9 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_3 (Dropout) multiple 0
_________________________________________________________________
conv2d_10 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_10 (Batc multiple 2048
_________________________________________________________________
activation_10 (Activation) multiple 0
_________________________________________________________________
conv2d_11 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_11 (Batc multiple 2048
_________________________________________________________________
activation_11 (Activation) multiple 0
_________________________________________________________________
conv2d_12 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_12 (Batc multiple 2048
_________________________________________________________________
activation_12 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_4 (Dropout) multiple 0
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dense (Dense) multiple 262656
_________________________________________________________________
dropout_5 (Dropout) multiple 0
_________________________________________________________________
dense_1 (Dense) multiple 262656
_________________________________________________________________
dropout_6 (Dropout) multiple 0
_________________________________________________________________
dense_2 (Dense) multiple 5130
=================================================================
Total params: 15,262,026
Trainable params: 15,253,578
Non-trainable params: 8,448
_________________________________________________________________
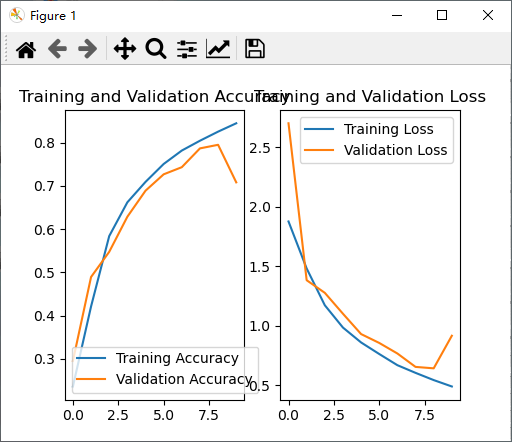
VGGNet网络训练结果
论文来源
Simonyan K , Zisserman A . Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
ResNet网络模型
ResNet(Residual Neural Network)网络作者想到了常规计算机视觉领域常用的residual representation的概念,并进一步将它应用在了CNN模型的构建当中,于是就有了基本的residual learning的block。它通过使用多个有参层来学习输入输出之间的残差表示,而非像一般CNN网络(如Alexnet/VGG等)那样使用有参层来直接尝试学习输入、输出之间的映射。实验表明使用一般意义上的有参层来直接学习残差比直接学习输入、输出间映射要容易得多(收敛速度更快),也有效得多(可通过使用更多的层来达到更高的分类精度)。
ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。ResNet的思想和Highway Network的思想也非常类似,允许原始输入信息直接传到后面的层中,如下图所示。
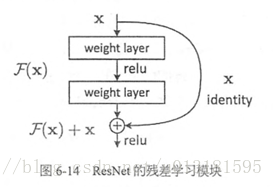
ResNet网络结构
Model: "res_net18"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 1728
_________________________________________________________________
batch_normalization (BatchNo multiple 256
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
sequential (Sequential) (None, 4, 4, 512) 11176448
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 5130
=================================================================
Total params: 11,183,562
Trainable params: 11,173,962
Non-trainable params: 9,600
_________________________________________________________________
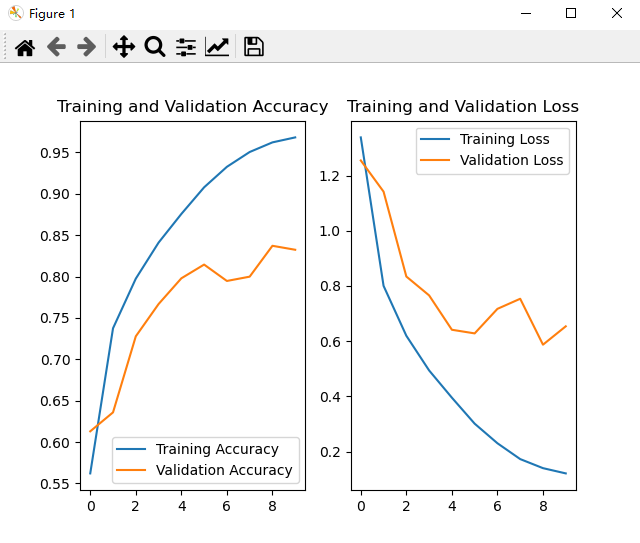
ResNet网络训练结果
论文来源
He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[J]. IEEE, 2016.
实现过程
在了解了各个经典的卷积神经网络模型后,接下来我使用Keras框架对其进行了实现。
(1)使用tf.keras.datasets.cifar10函数直接读取cifar10数据集,并将其分割成x_train, y_train, x_test, y_test,分别表示训练集和测试集的图像与标签。
(2)定义网络类,描述不同层的功能,包括卷积层,BN层,激活层等等。
(3)使用model.compile函数定义训练的优化器,损失函数与metrics。
(4)使用断点续训功能,检测并读取.ckpt文件。
(5)使用model.fit函数进行训练。
(6)使用model.summary函数输出模型结构。
(7)输出权重至weight.txt文件。
(8)绘制acc和loss曲线。
超参数研究
在每个网络的实现过程中,用到了很多超参数,本文将以BaseLine网络为例,列举超参数的作用和调整后的效果。
(1)optimizer :用于选择训练的优化器,常见的有sgd、adagrad、adadelta、adam等,区别在于一阶动量和二阶动量的差别。
(2)loss:损失函数的使用,一般有mse和sparse_categorical_crossentropy两种。其中,from_logits代表是否将输出转为概率分布的形式,为False时表示转换为概率分布,为True时表示不转换,直接输出。
(3)Metrics:表示网络评价指标,常见的有accuracy、sparse_accuracy、sparse_categorical_accuracy,有的是用数值表示,有的是使用独热码表示。
(4)batch_size:表示送入网络的数据尺寸,batch_size太大,深度学习的优化(training loss降不下去)和泛化(generalization gap很大)都会出问题。而batch_size太小,会来不及收敛。一般常见的batch_size约为32。
(5)epochs:表示迭代次数,随着迭代次数的增加,网络模型会逐渐收敛。
(6)validation_freq:表示在执行新的验证运行之前要运行多少个训练时期,如,validation_freq = 1时,每1个时期运行一次验证。一般默认为1.
更新日志与作者
该文更新为2021.10.9,作者:黄一骏 邮箱:[email protected]
 8 Nov 2, 2022
8 Nov 2, 2022

 71 Jan 5, 2023
71 Jan 5, 2023

 86 Aug 3, 2022
86 Aug 3, 2022

 12 Nov 11, 2022
12 Nov 11, 2022
 6 Dec 14, 2022
6 Dec 14, 2022
 3 Apr 7, 2022
3 Apr 7, 2022
 4 Jun 13, 2022
4 Jun 13, 2022
 1 Jan 13, 2022
1 Jan 13, 2022
 2.2k Jan 8, 2023
2.2k Jan 8, 2023

 2.4k Jan 5, 2023
2.4k Jan 5, 2023
 12 Jan 6, 2023
12 Jan 6, 2023
 9 Nov 7, 2022
9 Nov 7, 2022
 654 Dec 26, 2022
654 Dec 26, 2022
 2.4k Dec 28, 2022
2.4k Dec 28, 2022
 58 Dec 21, 2022
58 Dec 21, 2022
 19 Dec 12, 2022
19 Dec 12, 2022
 20 Dec 27, 2022
20 Dec 27, 2022
 14 Sep 13, 2022
14 Sep 13, 2022
 7 Jan 24, 2022
7 Jan 24, 2022