ViT - Vision Transformer
This is an implementation of ViT - Vision Transformer by Google Research Team through the paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale"
Please install PyTorch with CUDA support following this link
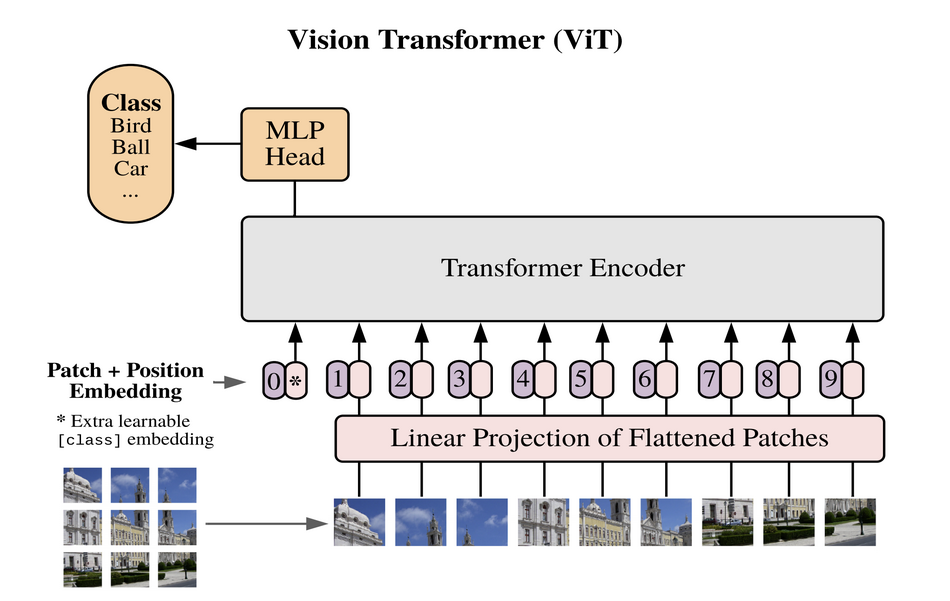
ViT Architecture
Configs
You can config the network by yourself through the config.txt file
128 #batch_size
500 #epoch
0.001 #learning_rate
0.0001 #gamma
224 #img_size
16 #patch_size
100 #num_class
768 #d_model
12 #n_head
12 #n_layers
3072 #d_mlp
3 #channels
0. #dropout
cls #pool
Training
Currently, you can only train this model on CIFAR-100 with the following commands:
> git clone https://github.com/quanmario0311/ViT_PyTorch.git
> cd ViT_PyTorch
> pip3 install -r requirements.txt
> python3 train.py
Suppport for other dataset and custom datasets will be updated later

 87 Nov 29, 2022
87 Nov 29, 2022

 52 Dec 29, 2022
52 Dec 29, 2022

 209 Dec 30, 2022
209 Dec 30, 2022

 5 Jan 3, 2023
5 Jan 3, 2023
 2 Oct 11, 2022
2 Oct 11, 2022

 3 Jun 3, 2022
3 Jun 3, 2022
 26 Nov 30, 2022
26 Nov 30, 2022

 62 Dec 24, 2022
62 Dec 24, 2022


 2 Dec 24, 2021
2 Dec 24, 2021
 44 Nov 24, 2022
44 Nov 24, 2022
 53 Dec 5, 2022
53 Dec 5, 2022
 75 Dec 2, 2022
75 Dec 2, 2022
 36 Oct 30, 2022
36 Oct 30, 2022
 12.6k Jan 9, 2023
12.6k Jan 9, 2023
 68 Sep 5, 2022
68 Sep 5, 2022
 1 Dec 24, 2021
1 Dec 24, 2021
 887 Jan 8, 2023
887 Jan 8, 2023
 1.4k Dec 30, 2022
1.4k Dec 30, 2022