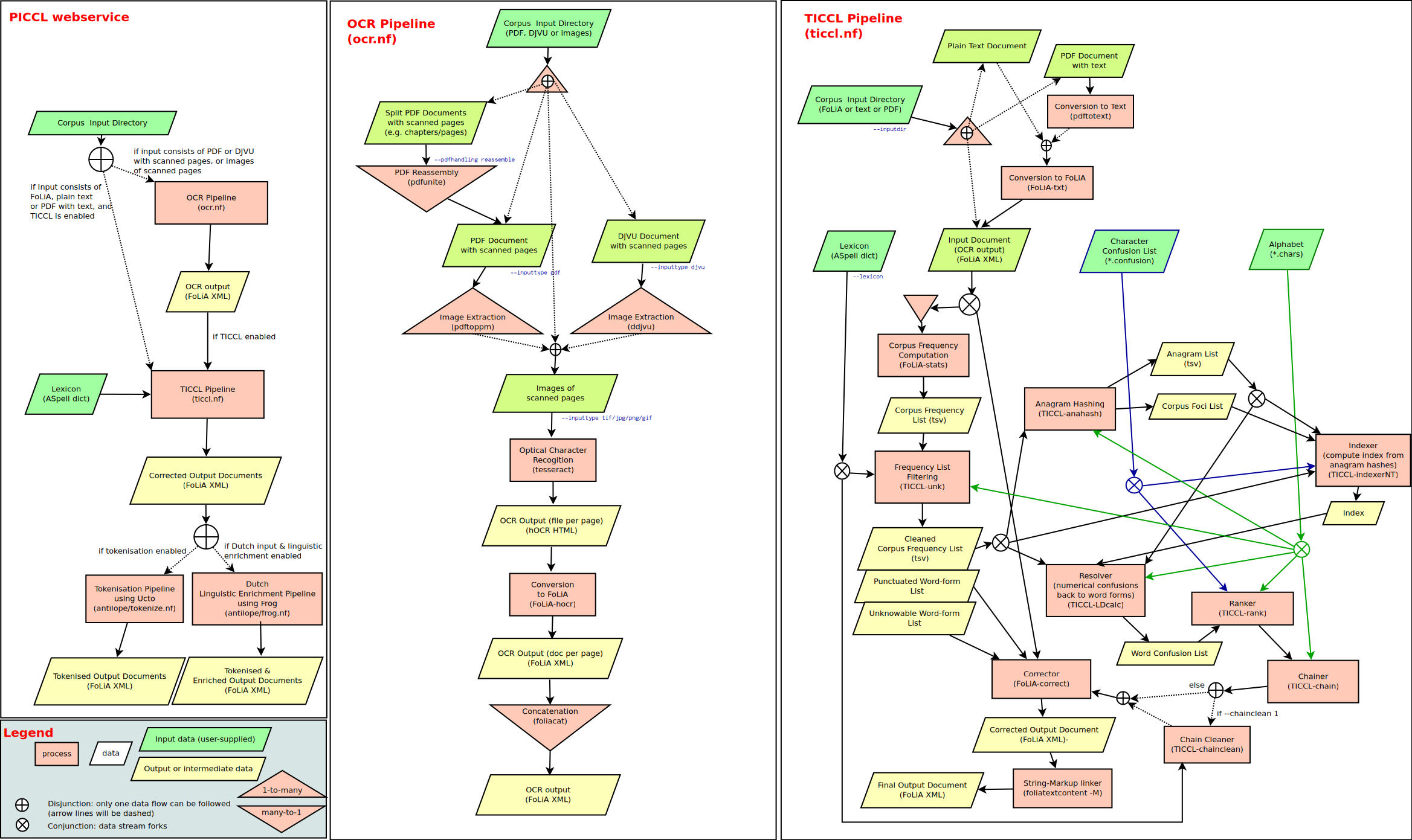
Hungarian Preverb Corpus
A gold standard corpus manually annotated with verb-preverb connections for Hungarian.
corpus
The corpus consist of the following 4 files:
| filename | # sentences | # preverbs |
|---|---|---|
| difficult_validate1.txt | 310 | 357 |
| difficult_validate2.txt | 840 | 935 |
| difficult_test.txt | 327 | 376 |
| general_test.txt | 503 | 500 |
Preverbs in the general dataset are in the distribution as they appear in normal Hungarian text. The difficult dataset is specially crafted: the most common and most-easy-to-handle pattern, i.e. when a verb is directly followed by its preverb (e.g. megy ki 'go out'), is omitted. validate is for development/validation, test is for testing. Note that a general_validate dataset would not be useful, because the trivial pattern would be in vast majority overwhelming the more interesting less frequent patterns.
Accordingly, the emPreverb tool which connects preverbs to their corresponding verb, was developed based only on interesting difficult examples, and tested both on difficult and general data.
(Remark. The difficult_validate dataset is divided into two parts for historical reasons, but you can simply use them together: they consist a total of 1150 sentences and 1292 preverbs.)
corpus annotation guidelines
- Preverb marked by a suffixed backslash followed by a (single digit!) ID number:
meg\1. - Word from which the preverb was separated marked by a pipe followed by the same ID number:
főzve|1. - Within the same line, different verb-prefix pairs must (obviously) receive different ID numbers.
- A preverb that does not belong to any word in the sentence (ellipsis etc.) is marked with a zero ID:
"Hazakísérhetlek?" "Meg\0 hát."Any number of preverbs can have the0ID within the same line. - In the
difficultdataset, a verb directly followed by its preverb is not annotated:főzte meg, but:főzte|1 volna meg\1. - In the
generaldataset, the first pattern is annotated as well:főzte|1 meg\1. - Normally there is a 1:1 correspondence between preverbs and verbs. However, there are exceptions, and these are annotated accordingly, e.g.
Se ki\1, se be\1 nem lehetett menni|1 Budakesziről;át-\1 meg átjárták|1.
Check (see Step 1 to 4 in evaluate.ipynb) whether tokens annotated as separated preverbs are also analysed by e-magyar morph,pos as preverbs. If not (e.g. if the preverb meg is tagged by emtsv as a [/Conj]), remove this annotation (or the whole item if no annotation left) from the dataset because preverb will necessarily fail due to incorrect emtsv annotation, which is extraneous to its performance evaluation. Exception: person-inflected preverb-like postpositions such as in utánam\1 dobják|1, which are tagged by emtsv as [/Post], and case-inflected personal pronouns such as in hozzá\1 voltam szokva|1, which are tagged as [/N|Pro], should not be removed from the dataset since preverb should be able to handle these.
If a token is annotated as the verb stem counterpart of a separated preverb, but is not tagged by emtsv as a verb, check whether the preverb annotation is correct, but if so, do not remove this annotation from the dataset. preverb is supposed to be able to handle the connection of such separated preverbs.
evaluation
An environment for reproducing evaluation of emPreverb as published in the paper below.
git clone https://github.com/ril-lexknowrep/emPreverb
cd emPreverb
make evaluate
Note that make evaluate clones this current repo inside emPreverb and runs evaluation.
The results are obtained in general_test_results.txt and difficult_test_results.txt. This should be exactly the same which can be found in Table 3 of the paper below.
development
An environment used for developing emPreverb. It is "for us" but if you insist to use it:
git clone https://github.com/ril-lexknowrep/emPreverb
cd emPreverb
git clone https://github.com/ril-lexknowrep/hungarian-preverb-corpus
cd hungarian-preverb-corpus/development
jupyter notebook evaluate.ipynb
(Remark. Yes, please clone this repo inside emPreverb.)
citation
If you use the corpus, please cite the following paper.
Pethő, Gergely and Sass, Bálint and Kalivoda, Ágnes and Simon, László and Lipp, Veronika: Igekötő-kapcsolás. In: MSZNY 2022.

 4 Jan 5, 2022
4 Jan 5, 2022
 214 Nov 22, 2022
214 Nov 22, 2022
 34 Aug 10, 2022
34 Aug 10, 2022

 49 Dec 1, 2022
49 Dec 1, 2022
 93 Nov 6, 2022
93 Nov 6, 2022

 471 Dec 16, 2022
471 Dec 16, 2022

 18 Dec 28, 2021
18 Dec 28, 2021
 437 Oct 9, 2022
437 Oct 9, 2022

 20 Dec 7, 2022
20 Dec 7, 2022
 32 Dec 14, 2022
32 Dec 14, 2022
 3 Apr 24, 2022
3 Apr 24, 2022
 1.8k Dec 30, 2022
1.8k Dec 30, 2022

 4 Jul 26, 2022
4 Jul 26, 2022
 4 Jan 14, 2022
4 Jan 14, 2022
 125 Dec 26, 2022
125 Dec 26, 2022
 227 Jan 2, 2023
227 Jan 2, 2023

 20 Aug 20, 2022
20 Aug 20, 2022
 41 Dec 27, 2022
41 Dec 27, 2022

 227 Jan 2, 2023
227 Jan 2, 2023
 34 Dec 18, 2022
34 Dec 18, 2022
 12 Apr 7, 2022
12 Apr 7, 2022
 47 Dec 15, 2022
47 Dec 15, 2022
 1 Feb 11, 2022
1 Feb 11, 2022
 3 Mar 9, 2022
3 Mar 9, 2022
 249 Jan 2, 2023
249 Jan 2, 2023
 7 Dec 5, 2022
7 Dec 5, 2022
 1 Mar 28, 2022
1 Mar 28, 2022
 7 Nov 30, 2022
7 Nov 30, 2022