3d-ken-burns
This is a reference implementation of 3D Ken Burns Effect from a Single Image [1] using PyTorch. Given a single input image, it animates this still image with a virtual camera scan and zoom subject to motion parallax. Should you be making use of our work, please cite our paper [1].

setup
Several functions are implemented in CUDA using CuPy, which is why CuPy is a required dependency. It can be installed using pip install cupy or alternatively using one of the provided binary packages as outlined in the CuPy repository. Please also make sure to have the CUDA_HOME environment variable configured.
In order to generate the video results, please also make sure to have pip install moviepy installed.
usage
To run it on an image and generate the 3D Ken Burns effect fully automatically, use the following command.
python autozoom.py --in ./images/doublestrike.jpg --out ./autozoom.mp4
To start the interface that allows you to manually adjust the camera path, use the following command. You can then navigate to http://localhost:8080/ and load an image using the button on the bottom right corner. Please be patient when loading an image and saving the result, there is a bit of background processing going on.
python interface.py
To run the depth estimation to obtain the raw depth estimate, use the following command. Please note that this script does not perform the depth adjustment, see #22 for information on how to add it.
python depthestim.py --in ./images/doublestrike.jpg --out ./depthestim.npy
To benchmark the depth estimation, run python benchmark-ibims.py or python benchmark-nyu.py. You can use it to easily verify that the provided implementation runs as expected.
colab
If you do not have a suitable environment to run this projects then you could give Colab a try. It allows you to run the project in the cloud, free of charge. There are several people who provide Colab notebooks that should get you started. A few that I am aware of include one from Arnaldo Gabriel, one from Vlad Alex, and one from Ahmed Harmouche.
dataset
This dataset is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License (CC BY-NC-SA 4.0) and may only be used for non-commercial purposes. Please see the LICENSE file for more information.
| scene | mode | color | depth | normal |
|---|---|---|---|---|
| asdf | flying | 3.7 GB | 1.0 GB | 2.9 GB |
| asdf | walking | 3.6 GB | 0.9 GB | 2.7 GB |
| blank | flying | 3.2 GB | 1.0 GB | 2.8 GB |
| blank | walking | 3.0 GB | 0.9 GB | 2.7 GB |
| chill | flying | 5.4 GB | 1.1 GB | 10.8 GB |
| chill | walking | 5.2 GB | 1.0 GB | 10.5 GB |
| city | flying | 0.8 GB | 0.2 GB | 0.9 GB |
| city | walking | 0.7 GB | 0.2 GB | 0.8 GB |
| environment | flying | 1.9 GB | 0.5 GB | 3.5 GB |
| environment | walking | 1.8 GB | 0.5 GB | 3.3 GB |
| fort | flying | 5.0 GB | 1.1 GB | 9.2 GB |
| fort | walking | 4.9 GB | 1.1 GB | 9.3 GB |
| grass | flying | 1.1 GB | 0.2 GB | 1.9 GB |
| grass | walking | 1.1 GB | 0.2 GB | 1.6 GB |
| ice | flying | 1.2 GB | 0.2 GB | 2.1 GB |
| ice | walking | 1.2 GB | 0.2 GB | 2.0 GB |
| knights | flying | 0.8 GB | 0.2 GB | 1.0 GB |
| knights | walking | 0.8 GB | 0.2 GB | 0.9 GB |
| outpost | flying | 4.8 GB | 1.1 GB | 7.9 GB |
| outpost | walking | 4.6 GB | 1.0 GB | 7.4 GB |
| pirates | flying | 0.8 GB | 0.2 GB | 0.8 GB |
| pirates | walking | 0.7 GB | 0.2 GB | 0.8 GB |
| shooter | flying | 0.9 GB | 0.2 GB | 1.1 GB |
| shooter | walking | 0.9 GB | 0.2 GB | 1.0 GB |
| shops | flying | 0.2 GB | 0.1 GB | 0.2 GB |
| shops | walking | 0.2 GB | 0.1 GB | 0.2 GB |
| slums | flying | 0.5 GB | 0.1 GB | 0.8 GB |
| slums | walking | 0.5 GB | 0.1 GB | 0.7 GB |
| subway | flying | 0.5 GB | 0.1 GB | 0.9 GB |
| subway | walking | 0.5 GB | 0.1 GB | 0.9 GB |
| temple | flying | 1.7 GB | 0.4 GB | 3.1 GB |
| temple | walking | 1.7 GB | 0.3 GB | 2.8 GB |
| titan | flying | 6.2 GB | 1.1 GB | 11.5 GB |
| titan | walking | 6.0 GB | 1.1 GB | 11.3 GB |
| town | flying | 1.7 GB | 0.3 GB | 3.0 GB |
| town | walking | 1.8 GB | 0.3 GB | 3.0 GB |
| underland | flying | 5.4 GB | 1.2 GB | 12.1 GB |
| underland | walking | 5.1 GB | 1.2 GB | 11.4 GB |
| victorian | flying | 0.5 GB | 0.1 GB | 0.8 GB |
| victorian | walking | 0.4 GB | 0.1 GB | 0.7 GB |
| village | flying | 1.6 GB | 0.3 GB | 2.8 GB |
| village | walking | 1.6 GB | 0.3 GB | 2.7 GB |
| warehouse | flying | 0.9 GB | 0.2 GB | 1.5 GB |
| warehouse | walking | 0.8 GB | 0.2 GB | 1.4 GB |
| western | flying | 0.8 GB | 0.2 GB | 0.9 GB |
| western | walking | 0.7 GB | 0.2 GB | 0.8 GB |
Please note that this is an updated version of the dataset that we have used in our paper. So while it has fewer scenes in total, each sample capture now has a varying focal length which should help with generalizability. Furthermore, some examples are either over- or under-exposed and it would be a good idea to remove these outliers. Please see #37, #39, and #40 for supplementary discussions.
video
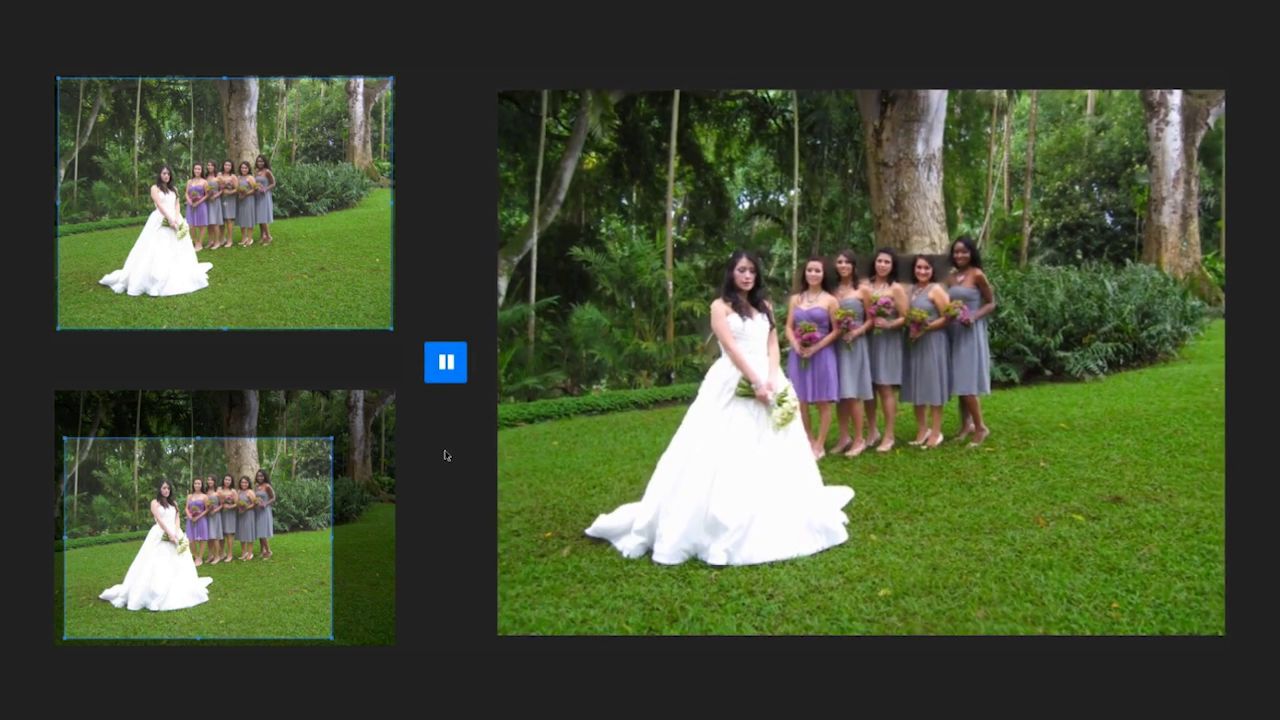
license
This is a project by Adobe Research. It is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License (CC BY-NC-SA 4.0) and may only be used for non-commercial purposes. Please see the LICENSE file for more information.
references
[1] @article{Niklaus_TOG_2019,
author = {Simon Niklaus and Long Mai and Jimei Yang and Feng Liu},
title = {3D Ken Burns Effect from a Single Image},
journal = {ACM Transactions on Graphics},
volume = {38},
number = {6},
pages = {184:1--184:15},
year = {2019}
}
acknowledgment
The video above uses materials under a Creative Common license or with the owner's permission, as detailed at the end.



















 436 Jan 9, 2023
436 Jan 9, 2023
 94 Dec 29, 2022
94 Dec 29, 2022
 94 Dec 3, 2022
94 Dec 3, 2022
 5 Dec 27, 2021
5 Dec 27, 2021
 19 Jun 23, 2022
19 Jun 23, 2022
 7 Nov 26, 2022
7 Nov 26, 2022
 1 Jun 28, 2022
1 Jun 28, 2022
 4 Aug 24, 2022
4 Aug 24, 2022
 47 Oct 11, 2022
47 Oct 11, 2022
 7 Feb 10, 2022
7 Feb 10, 2022
 173 Dec 30, 2022
173 Dec 30, 2022
 677 Dec 25, 2022
677 Dec 25, 2022
 3.2k Dec 25, 2022
3.2k Dec 25, 2022
 50 Dec 29, 2022
50 Dec 29, 2022
 149 Jan 8, 2023
149 Jan 8, 2023
 140 Nov 23, 2022
140 Nov 23, 2022
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
 1.8k Dec 28, 2022
1.8k Dec 28, 2022
 4 Aug 28, 2022
4 Aug 28, 2022