This work has now been superseded by: https://github.com/sniklaus/revisiting-sepconv
sepconv-slomo
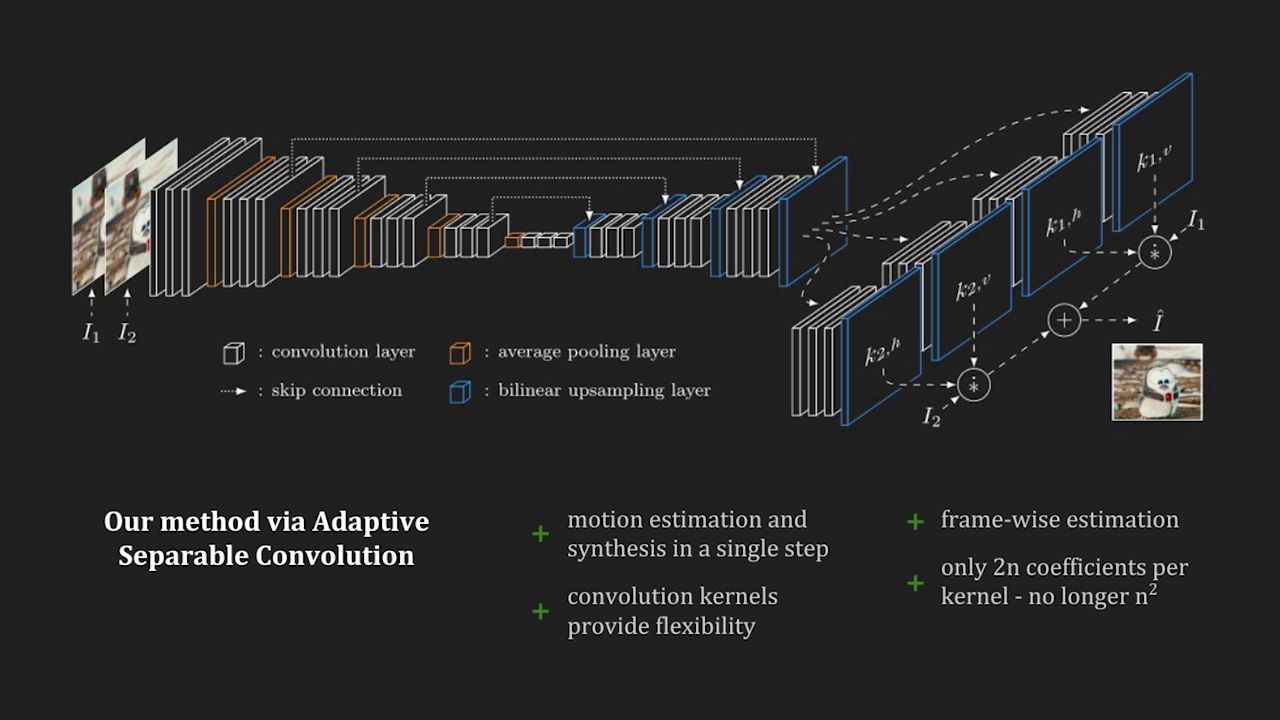
This is a reference implementation of Video Frame Interpolation via Adaptive Separable Convolution [1] using PyTorch. Given two frames, it will make use of adaptive convolution [2] in a separable manner to interpolate the intermediate frame. Should you be making use of our work, please cite our paper [1].

For a reimplemntation of our work, see: https://github.com/martkartasev/sepconv
And for another adaptation, consider: https://github.com/HyeongminLEE/pytorch-sepconv
For softmax splatting, please see: https://github.com/sniklaus/softmax-splatting
setup
The separable convolution layer is implemented in CUDA using CuPy, which is why CuPy is a required dependency. It can be installed using pip install cupy or alternatively using one of the provided binary packages as outlined in the CuPy repository.
If you plan to process videos, then please also make sure to have pip install moviepy installed.
usage
To run it on your own pair of frames, use the following command. You can either select the l1 or the lf model, please see our paper for more details. In short, the l1 model should be used for quantitative evaluations and the lf model for qualitative comparisons.
python run.py --model lf --one ./images/one.png --two ./images/two.png --out ./out.png
To run in on a video, use the following command.
python run.py --model lf --video ./videos/car-turn.mp4 --out ./out.mp4
For a quick benchmark using examples from the Middlebury benchmark for optical flow, run python benchmark.py. You can use it to easily verify that the provided implementation runs as expected.
video
license
The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
references
[1] @inproceedings{Niklaus_ICCV_2017,
author = {Simon Niklaus and Long Mai and Feng Liu},
title = {Video Frame Interpolation via Adaptive Separable Convolution},
booktitle = {IEEE International Conference on Computer Vision},
year = {2017}
}
[2] @inproceedings{Niklaus_CVPR_2017,
author = {Simon Niklaus and Long Mai and Feng Liu},
title = {Video Frame Interpolation via Adaptive Convolution},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
year = {2017}
}
acknowledgment
This work was supported by NSF IIS-1321119. The video above uses materials under a Creative Common license or with the owner's permission, as detailed at the end.











 280 Dec 23, 2022
280 Dec 23, 2022
 195 Dec 29, 2022
195 Dec 29, 2022
 544 Dec 19, 2022
544 Dec 19, 2022
 49 Jan 7, 2023
49 Jan 7, 2023
 86 Dec 28, 2022
86 Dec 28, 2022
 3k Jan 4, 2023
3k Jan 4, 2023
 28 Dec 9, 2022
28 Dec 9, 2022
 63 Dec 16, 2022
63 Dec 16, 2022
 4 Dec 15, 2022
4 Dec 15, 2022
 95 Dec 4, 2022
95 Dec 4, 2022
 6 May 3, 2022
6 May 3, 2022
 69 Dec 17, 2022
69 Dec 17, 2022
 31 Nov 25, 2022
31 Nov 25, 2022
 36 Jan 5, 2023
36 Jan 5, 2023
 228 Dec 25, 2022
228 Dec 25, 2022
 64 Dec 21, 2022
64 Dec 21, 2022
 100 Nov 30, 2022
100 Nov 30, 2022
 49 Nov 22, 2022
49 Nov 22, 2022
 9 Jun 17, 2022
9 Jun 17, 2022