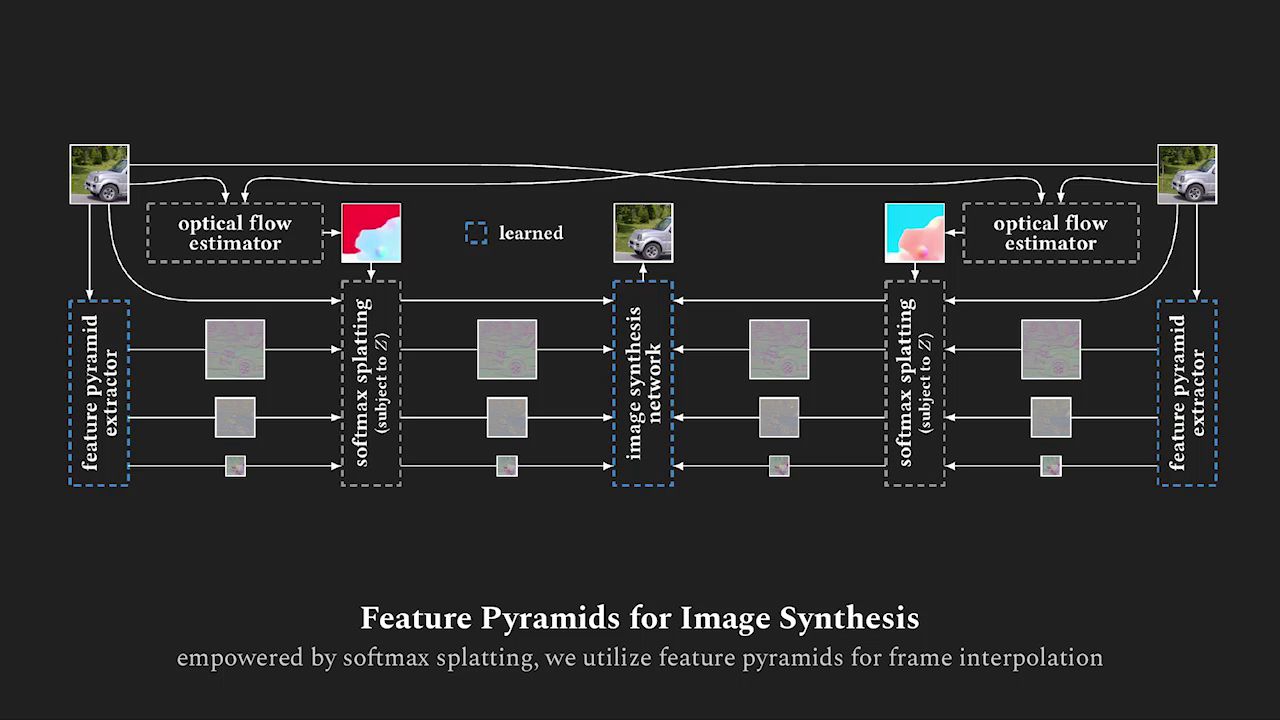
softmax-splatting
This is a reference implementation of the softmax splatting operator, which has been proposed in Softmax Splatting for Video Frame Interpolation [1], using PyTorch. Softmax splatting is a well-motivated approach for differentiable forward warping. It uses a translational invariant importance metric to disambiguate cases where multiple source pixels map to the same target pixel. Should you be making use of our work, please cite our paper [1].

setup
The softmax splatting is implemented in CUDA using CuPy, which is why CuPy is a required dependency. It can be installed using pip install cupy or alternatively using one of the provided binary packages as outlined in the CuPy repository.
The provided example script is using OpenCV to load and display images, as well as to read the provided optical flow file. An easy way to install OpenCV for Python is using the pip install opencv-contrib-python package.
usage
We provide a small script to replicate the third figure of our paper [1]. You can simply run python run.py to obtain the comparison between summation splatting, average splatting, linear splatting, and softmax splatting. Please see this exemplatory run.py for additional information on how to use the provided reference implementation of our proposed softmax splatting operator for differentiable forward warping.
xiph
In our paper, we propose to use 4K video clips from Xiph to evaluate video frame interpolation on high-resolution footage. Please see the supplementary benchmark.py on how to reproduce the shown metrics.
video
license
The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
references
[1] @inproceedings{Niklaus_CVPR_2020,
author = {Simon Niklaus and Feng Liu},
title = {Softmax Splatting for Video Frame Interpolation},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
year = {2020}
}
acknowledgment
The video above uses materials under a Creative Common license as detailed at the end.



 Top left: frame 1; Top right: frame 2; Bottom Left: warped frame
Top left: frame 1; Top right: frame 2; Bottom Left: warped frame










 302 Dec 14, 2022
302 Dec 14, 2022
 46 Dec 14, 2022
46 Dec 14, 2022
 2.3k Jan 5, 2023
2.3k Jan 5, 2023
 287 Nov 25, 2022
287 Nov 25, 2022
 120 Dec 15, 2022
120 Dec 15, 2022
 65 Oct 6, 2022
65 Oct 6, 2022
 9 Oct 30, 2022
9 Oct 30, 2022
 159 Dec 20, 2022
159 Dec 20, 2022
 5 Nov 14, 2022
5 Nov 14, 2022
 21 Dec 7, 2022
21 Dec 7, 2022
 170 Dec 27, 2022
170 Dec 27, 2022
 91 Nov 21, 2022
91 Nov 21, 2022
 3 Oct 15, 2022
3 Oct 15, 2022
 19 Aug 30, 2022
19 Aug 30, 2022
 442 Dec 16, 2022
442 Dec 16, 2022
 135 Dec 30, 2022
135 Dec 30, 2022
 4 Sep 17, 2022
4 Sep 17, 2022
 1 Nov 16, 2021
1 Nov 16, 2021