Hi~
- 想问你在多卡条件下跑过事件检测的代码嘛?我用4张卡跑,报了下面的错误:
Training: 0%| | 0/1159 [00:22<?, ?it/s]
Traceback (most recent call last):
File "run_trigger_extraction.py", line 405, in <module>
main()
File "run_trigger_extraction.py", line 378, in main
train(args, model, processor)
File "run_trigger_extraction.py", line 243, in train
pred_sub_heads, pred_sub_tails = model(data, add_label_info=add_label_info)
File "/home/yc21/software/anaconda3/envs/lear/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/yc21/software/anaconda3/envs/lear/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 168, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/yc21/software/anaconda3/envs/lear/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 178, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/yc21/software/anaconda3/envs/lear/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
output.reraise()
File "/home/yc21/software/anaconda3/envs/lear/lib/python3.8/site-packages/torch/_utils.py", line 434, in reraise
raise exception
RuntimeError: Caught RuntimeError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/home/yc21/software/anaconda3/envs/lear/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/home/yc21/software/anaconda3/envs/lear/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
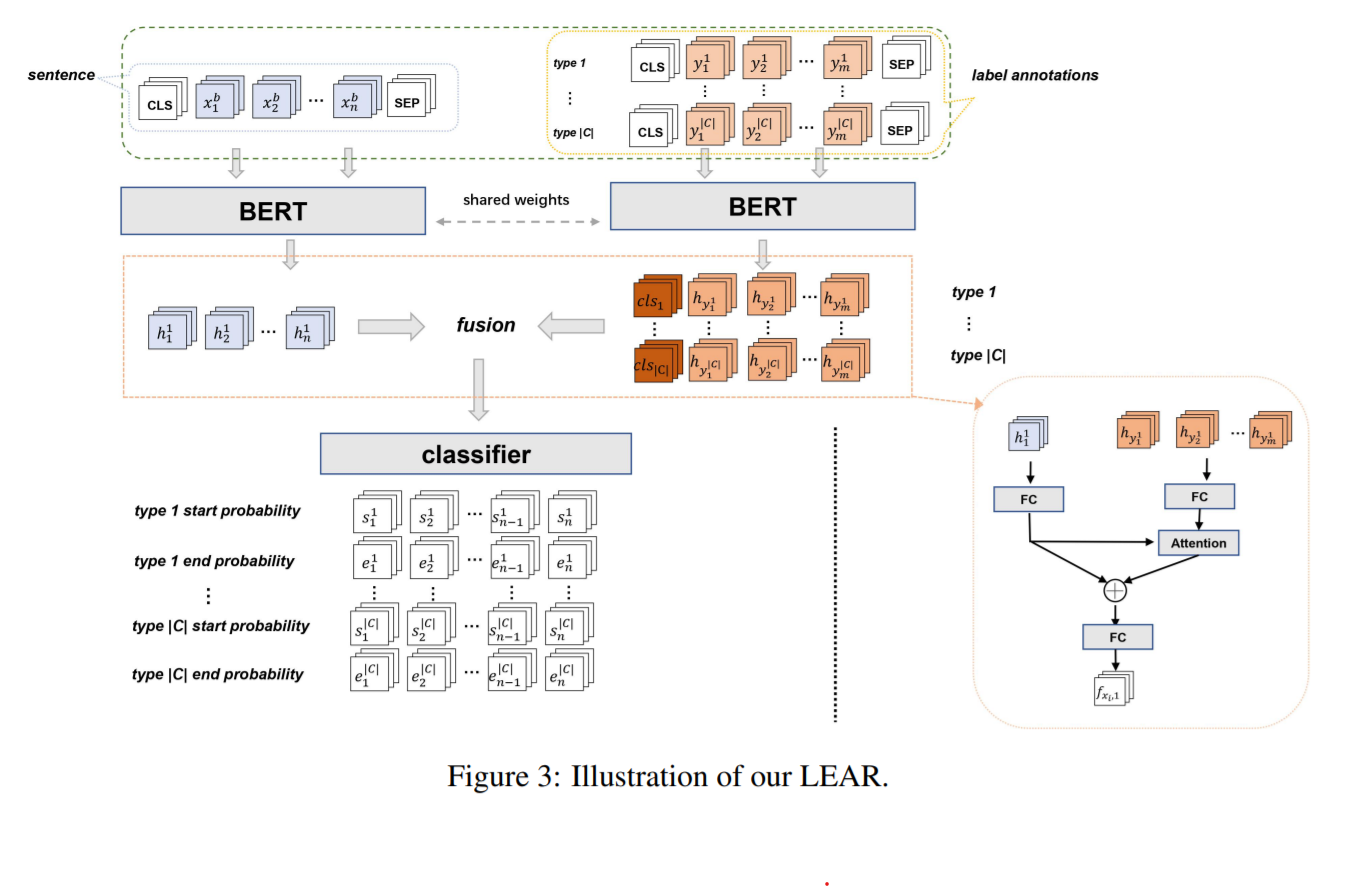
File "/home/yc21/project/LEAR/models/model_event.py", line 635, in forward
fused_results = self.label_fusing_layer(
File "/home/yc21/software/anaconda3/envs/lear/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/yc21/project/LEAR/utils/model_utils.py", line 320, in forward
return self.get_fused_feature_with_attn(token_embs, label_embs, input_mask, label_input_mask, return_scores=return_scores)
File "/home/yc21/project/LEAR/utils/model_utils.py", line 504, in get_fused_feature_with_attn
scores = torch.matmul(token_feature_fc, label_feature_t).view(
RuntimeError: shape '[4, 48, 33, -1]' is invalid for input of size 160512
- 我用一张卡跑,设置batchsize=2, gradient_accumulation_step=16, 能够跑通,但是得到的结果是train上的loss收敛到了6,dev的f1一直是0。我不知道这只是我的个人问题,还是有其他人也存在这个问题。有童鞋跑出相应的结果了么?
谢谢大家~






 39 Dec 11, 2022
39 Dec 11, 2022
 74 Dec 30, 2022
74 Dec 30, 2022
 89 Dec 26, 2022
89 Dec 26, 2022
 19 Aug 23, 2022
19 Aug 23, 2022
 57 Jan 1, 2023
57 Jan 1, 2023
 34 Dec 21, 2022
34 Dec 21, 2022
 35 Nov 17, 2022
35 Nov 17, 2022
 11 Jan 1, 2023
11 Jan 1, 2023
 42 Jan 7, 2023
42 Jan 7, 2023
 27 Oct 28, 2022
27 Oct 28, 2022
 105 Jan 3, 2023
105 Jan 3, 2023
 39 Jan 1, 2023
39 Jan 1, 2023
 25 Sep 6, 2022
25 Sep 6, 2022
 12 Nov 22, 2022
12 Nov 22, 2022
 9 Oct 28, 2022
9 Oct 28, 2022
 33 Dec 5, 2022
33 Dec 5, 2022
 105 Nov 25, 2022
105 Nov 25, 2022