

Python Machine Learning Jupyter Notebooks (ML website)
Dr. Tirthajyoti Sarkar, Fremont, California (Please feel free to connect on LinkedIn here)
Also check out these super-useful Repos that I curated
-
Highly cited and useful papers related to machine learning, deep learning, AI, game theory, reinforcement learning
-
Carefully curated resource links for data science in one place
Requirements
- Python 3.6+
- NumPy (
pip install numpy) - Pandas (
pip install pandas) - Scikit-learn (
pip install scikit-learn) - SciPy (
pip install scipy) - Statsmodels (
pip install statsmodels) - MatplotLib (
pip install matplotlib) - Seaborn (
pip install seaborn) - Sympy (
pip install sympy) - Flask (
pip install flask) - WTForms (
pip install wtforms) - Tensorflow (
pip install tensorflow>=1.15) - Keras (
pip install keras) - pdpipe (
pip install pdpipe)
You can start with this article that I wrote in Heartbeat magazine (on Medium platform):
"Some Essential Hacks and Tricks for Machine Learning with Python"

Essential tutorial-type notebooks on Pandas and Numpy
Jupyter notebooks covering a wide range of functions and operations on the topics of NumPy, Pandans, Seaborn, Matplotlib etc.
- Detailed Numpy operations
- Detailed Pandas operations
- Numpy and Pandas quick basics
- Matplotlib and Seaborn quick basics
- Advanced Pandas operations
- How to read various data sources
- PDF reading and table processing demo
- How fast are Numpy operations compared to pure Python code? (Read my article on Medium related to this topic)
- Fast reading from Numpy using .npy file format (Read my article on Medium on this topic)
Tutorial-type notebooks covering regression, classification, clustering, dimensionality reduction, and some basic neural network algorithms
Regression
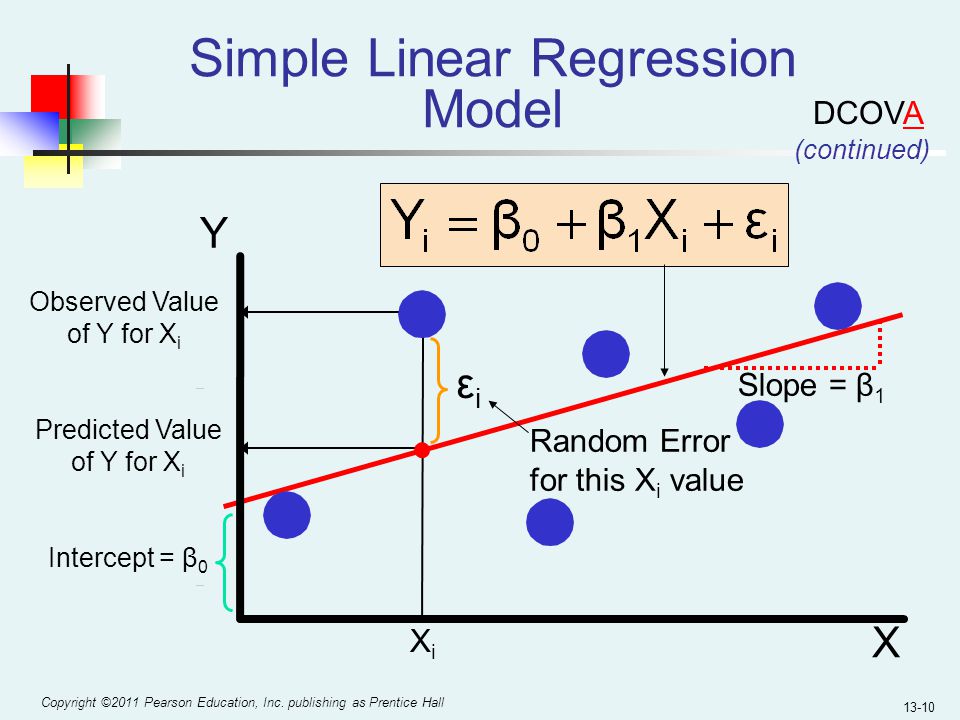
- Simple linear regression with t-statistic generation
-
Multiple ways to perform linear regression in Python and their speed comparison (check the article I wrote on freeCodeCamp)

-
Polynomial regression using scikit-learn pipeline feature (check the article I wrote on Towards Data Science)
-
Decision trees and Random Forest regression (showing how the Random Forest works as a robust/regularized meta-estimator rejecting overfitting)
-
Detailed visual analytics and goodness-of-fit diagnostic tests for a linear regression problem
-
Robust linear regression using
HuberRegressorfrom Scikit-learn
Classification
- Logistic regression/classification (Here is the Notebook)
-
k-nearest neighbor classification (Here is the Notebook)
-
Decision trees and Random Forest Classification (Here is the Notebook)
-
Support vector machine classification (Here is the Notebook) (check the article I wrote in Towards Data Science on SVM and sorting algorithm)

- Naive Bayes classification (Here is the Notebook)
Clustering
-
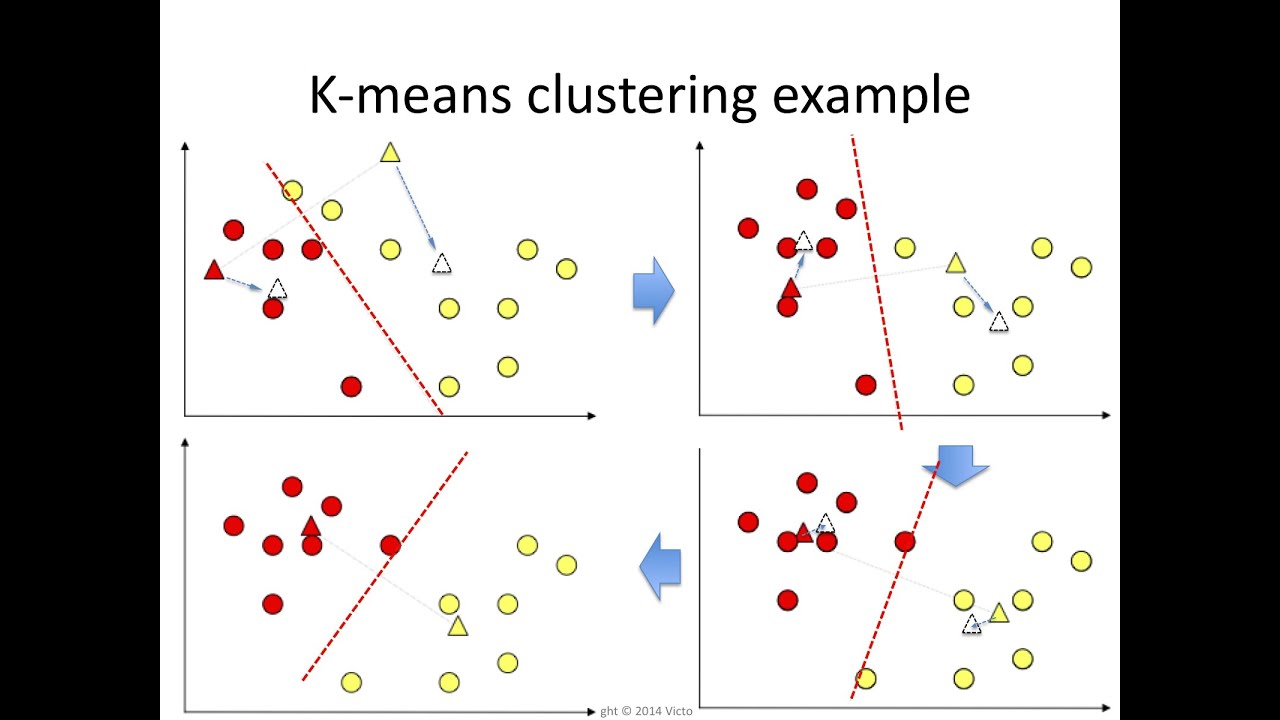
K-means clustering (Here is the Notebook)
-
Affinity propagation (showing its time complexity and the effect of damping factor) (Here is the Notebook)
-
Mean-shift technique (showing its time complexity and the effect of noise on cluster discovery) (Here is the Notebook)
-
DBSCAN (showing how it can generically detect areas of high density irrespective of cluster shapes, which the k-means fails to do) (Here is the Notebook)
-
Hierarchical clustering with Dendograms showing how to choose optimal number of clusters (Here is the Notebook)

Dimensionality reduction
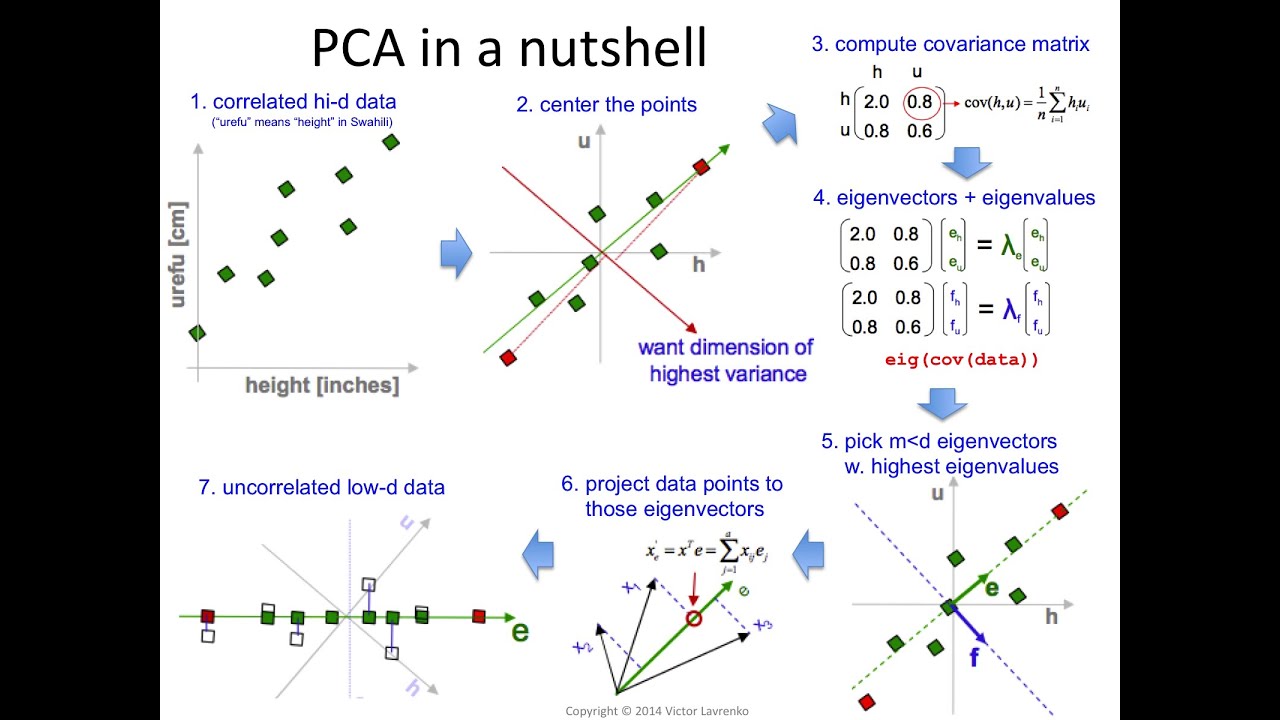
- Principal component analysis
Deep Learning/Neural Network
- Demo notebook to illustrate the superiority of deep neural network for complex nonlinear function approximation task
- Step-by-step building of 1-hidden-layer and 2-hidden-layer dense network using basic TensorFlow methods
Random data generation using symbolic expressions
-
How to use Sympy package to generate random datasets using symbolic mathematical expressions.
-
Here is my article on Medium on this topic: Random regression and classification problem generation with symbolic expression
Synthetic data generation techniques
Simple deployment examples (serving ML models on web API)
-
Serving a linear regression model through a simple HTTP server interface. User needs to request predictions by executing a Python script. Uses
FlaskandGunicorn. -
Serving a recurrent neural network (RNN) through a HTTP webpage, complete with a web form, where users can input parameters and click a button to generate text based on the pre-trained RNN model. Uses
Flask,Jinja,Keras/TensorFlow,WTForms.
Object-oriented programming with machine learning
Implementing some of the core OOP principles in a machine learning context by building your own Scikit-learn-like estimator, and making it better.
See my articles on Medium on this topic.
- Object-oriented programming for data scientists: Build your ML estimator
- How a simple mix of object-oriented programming can sharpen your deep learning prototype
Unit testing ML code with Pytest
Check the files and detailed instructions in the Pytest directory to understand how one should write unit testing code/module for machine learning models
Memory and timing profiling
Profiling data science code and ML models for memory footprint and computing time is a critical but often overlooed area. Here are a couple of Notebooks showing the ideas,








 84 Nov 25, 2022
84 Nov 25, 2022
 8.1k Dec 30, 2022
8.1k Dec 30, 2022
 19 Oct 3, 2022
19 Oct 3, 2022
 6 Dec 27, 2022
6 Dec 27, 2022
 2 Aug 23, 2022
2 Aug 23, 2022
 366 Jan 3, 2023
366 Jan 3, 2023
 152 Jan 7, 2023
152 Jan 7, 2023
 5.7k Dec 30, 2022
5.7k Dec 30, 2022
 0 Jan 31, 2022
0 Jan 31, 2022
 3k Jan 8, 2023
3k Jan 8, 2023
 4.2k Dec 29, 2022
4.2k Dec 29, 2022
 1.4k Jan 6, 2023
1.4k Jan 6, 2023
 671 Dec 25, 2022
671 Dec 25, 2022
 6.2k Jan 1, 2023
6.2k Jan 1, 2023
 511 Dec 20, 2022
511 Dec 20, 2022
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
 536 Dec 29, 2022
536 Dec 29, 2022
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
 154 Dec 17, 2022
154 Dec 17, 2022