



Disclaimer
This project
- is stable and being incubated for long-term support. It may contain new experimental code, for which APIs are subject to change.
- requires PyStan as a system dependency. PyStan is licensed under GPLv3, which is a free, copyleft license for software.
Orbit: A Python Package for Bayesian Forecasting
Orbit is a Python package for Bayesian time series forecasting and inference. It provides a familiar and intuitive initialize-fit-predict interface for time series tasks, while utilizing probabilistic programing languages under the hood.
Currently, it supports concrete implementations for the following models:
- Exponential Smoothing (ETS)
- Damped Local Trend (DLT)
- Local Global Trend (LGT)
It also supports the following sampling methods for model estimation:
- Markov-Chain Monte Carlo (MCMC) as a full sampling method
- Maximum a Posteriori (MAP) as a point estimate method
- Variational Inference (VI) as a hybrid-sampling method on approximate distribution
Installation
Installing Stable Release
Install from PyPi:
$ pip install orbit-ml
Install from source:
$ git clone https://github.com/uber/orbit.git
$ cd orbit
$ pip install -r requirements.txt
$ pip install .
Installing from Dev Branch
$ pip install git+https://github.com/uber/orbit.git@dev
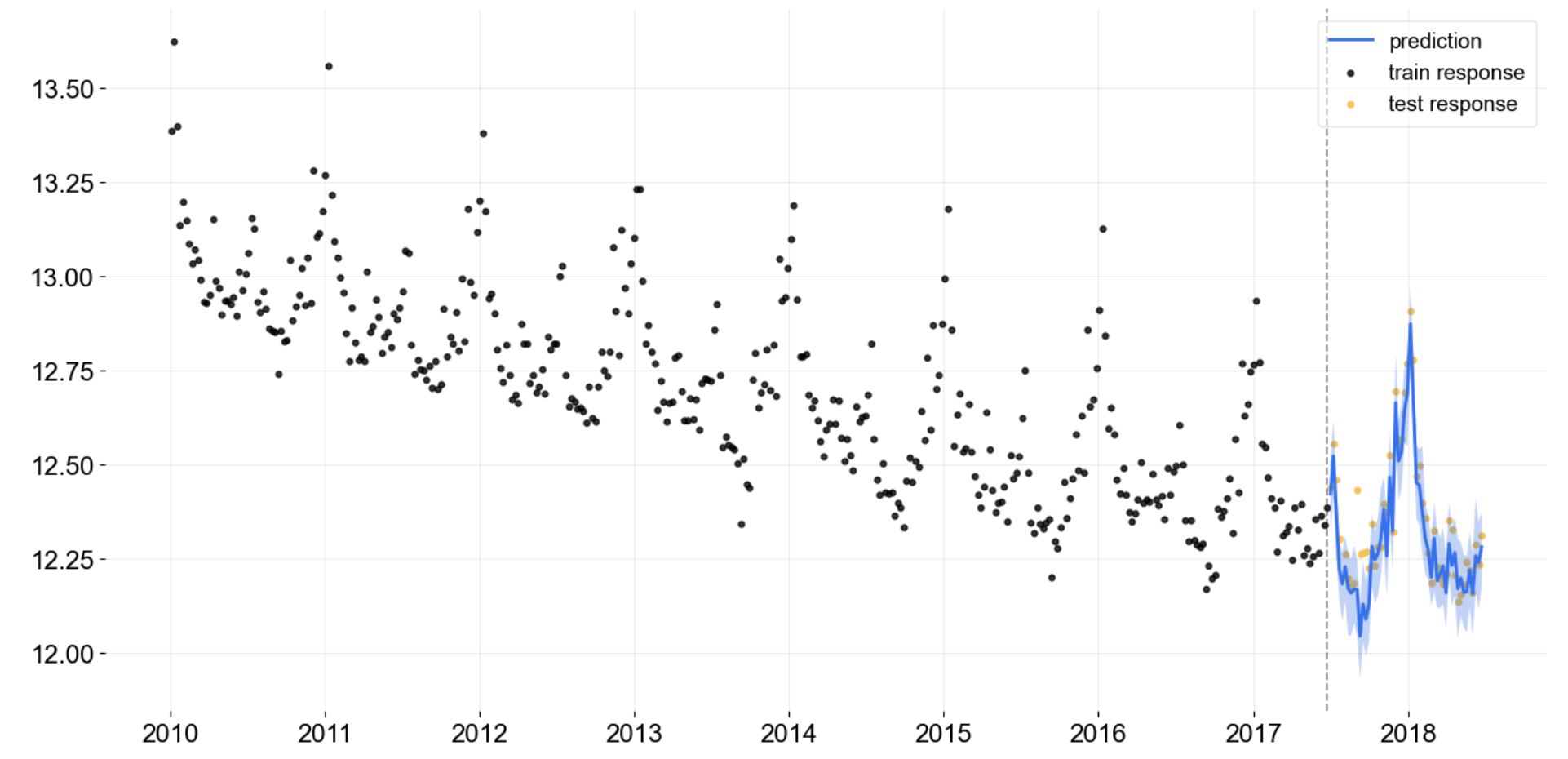
Quick Start with Damped-Local-Trend (DLT) Model
FULL Bayesian Prediction
from orbit.utils.dataset import load_iclaims
from orbit.models.dlt import DLTFull
from orbit.diagnostics.plot import plot_predicted_data
# log-transformed data
df = load_iclaims()
# train-test split
test_size=52
train_df=df[:-test_size]
test_df=df[-test_size:]
dlt = DLTFull(
response_col='claims', date_col='week',
regressor_col=['trend.unemploy', 'trend.filling', 'trend.job'],
seasonality=52,
)
dlt.fit(df=train_df)
# outcomes data frame
predicted_df = dlt.predict(df=test_df)
plot_predicted_data(
training_actual_df=train_df, predicted_df=predicted_df,
date_col=dlt.date_col, actual_col=dlt.response_col,
test_actual_df=test_df
)
Contributing
We welcome community contributors to the project. Before you start, please read our code of conduct and check out contributing guidelines first.
Versioning
We document versions and changes in our changelog.
References
Documentation
- HTML documentation (stable): https://orbit-ml.readthedocs.io/en/stable/
- HTML documentation (old): https://uber.github.io/orbit/
Citation
To cite Orbit in publications, refer to the following whitepaper:
Orbit: Probabilistic Forecast with Exponential Smoothing
Bibtex:
@misc{
ng2020orbit,
title={Orbit: Probabilistic Forecast with Exponential Smoothing},
author={Edwin Ng,
Zhishi Wang,
Huigang Chen,
Steve Yang,
Slawek Smyl},
year={2020}, eprint={2004.08492}, archivePrefix={arXiv}, primaryClass={stat.CO}
}
Papers
- Hyndman, R., Koehler, A. B., Ord, J. K., and Snyder, R. D. Forecasting with exponential smoothing: the state space approach. Springer Science & Business Media, 2008.
- Bingham, E., Chen, J. P., Jankowiak, M., Obermeyer, F., Pradhan, N., Karaletsos, T., Singh, R., Szerlip, P., Horsfall, P., and Goodman, N. D. Pyro: Deep universal probabilistic programming. The Journal of Machine Learning Research, 20(1):973–978, 2019.
- Taylor, S. J. and Letham, B. Forecasting at scale. The American Statistician, 72(1):37–45, 2018.
- Hoffman, M.D. and Gelman, A. The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res., 15(1), pp.1593-1623, 2014.














 2.2k Dec 28, 2022
2.2k Dec 28, 2022
 4.7k Jan 9, 2023
4.7k Jan 9, 2023
 2.5k Dec 30, 2022
2.5k Dec 30, 2022
 7.7k Dec 30, 2022
7.7k Dec 30, 2022
 3k Jan 2, 2023
3k Jan 2, 2023
 2.2k Dec 25, 2022
2.2k Dec 25, 2022
 3 Jan 31, 2022
3 Jan 31, 2022
 3.8k Jan 5, 2023
3.8k Jan 5, 2023
 1 Nov 8, 2021
1 Nov 8, 2021
 61 Oct 2, 2022
61 Oct 2, 2022
 1.8k Jan 9, 2023
1.8k Jan 9, 2023
 1 Jan 19, 2022
1 Jan 19, 2022
 861 Dec 29, 2022
861 Dec 29, 2022
 527 Dec 4, 2022
527 Dec 4, 2022
 3 Nov 8, 2022
3 Nov 8, 2022
 687 Dec 25, 2022
687 Dec 25, 2022
 12 Dec 28, 2022
12 Dec 28, 2022
 4 Oct 17, 2022
4 Oct 17, 2022